
介绍一下regexp_extract?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
regexp_extract函数用于从字符串中提取符合正则表达式的子串。以下是该函数的基本使用方法和参数说明:
基本语法: - regexp_extract(string source, string pattern[, bigint groupid])
source: 必填,STRING类型,待处理的原始字符串。 pattern: 必填,STRING类型,用于匹配的正则表达式。groupid: 可选,BIGINT类型,默认为1,指定了想要提取的分组编号(从1开始计数)。如果未指定或设置为0,则返回整个匹配的字符串。
功能描述: - 根据提供的正则表达式pattern在字符串source中进行匹配,然后返回第groupid个括号捕获的子串。如果正则表达式中没有括号或未指定有效的groupid,函数将按规则返回错误或特定结果。
示例: - regexp_extract('foothebar', 'foo(.*?)(bar)', 2) 将返回 'bar',因为它匹配了第二个括号内的内容。 请注意,数据以UTF-8格式存储,对于特殊字符如中文,可采用Unicode编码表示。
参考链接:REGEXP_EXTRACThttps://help.aliyun.com/zh/maxcompute/user-guide/regexp-extract
regexp_extract 是一个在不同数据处理和分析系统中广泛使用的函数,阿里云Log Service (SLS)、MaxCompute以及其他支持正则表达式的环境如Apache Flink中,用于从字符串中根据正则表达式提取特定模式的子串。
函数签名:
regexp_extract_all(source, pattern[, group_id])regexp_extract(string source, string pattern[, bigint groupid])参数说明:
source: 必填参数,类型为STRING。表示需要从中提取信息的原始字符串。pattern: 必填参数,类型为STRING。定义了正则表达式模式,用于在source中查找匹配项。group_id: 可选参数,默认值为1,类型为BIGINT。指定了希望返回的正则表达式中括号分组的编号。编号从1开始,表示第一个括号内的匹配内容。如果设置为0,则返回整个正则表达式匹配到的字符串。group_id参数,可以选择提取正则表达式中特定括号分组的内容,提供了提取灵活性。regexp_extract_all中,会返回所有匹配到的子串组成的数组,适用于需要收集所有匹配情况的场景。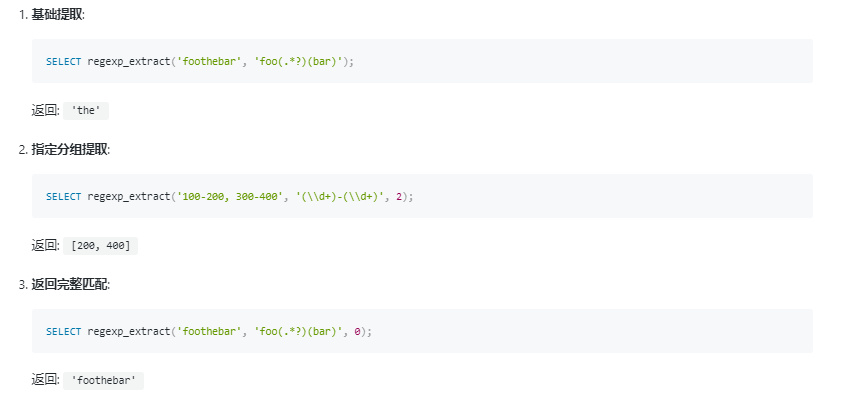
相关链接
字符串函数 REGEXP_EXTRACT https://help.aliyun.com/zh/iot/user-guide/iot-platform-string-functions

