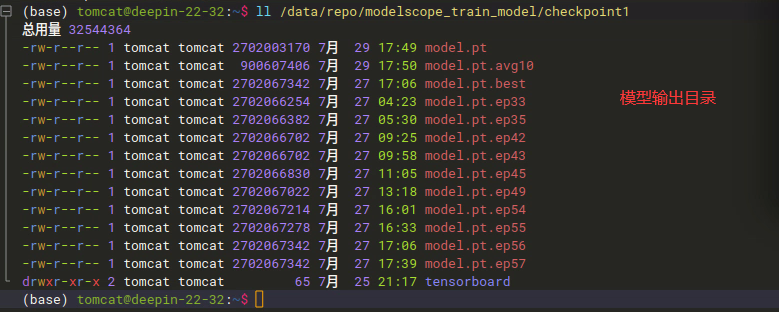
modelscope-funasr如何使用已经有的训练数据集?如何生成am.mvn;还是说直接拷贝【damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch】目录的am.mvn文件即可;在用funasr-1.1.4时,使用自定义数据集做训练测试模型:damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch,源模型:
代码: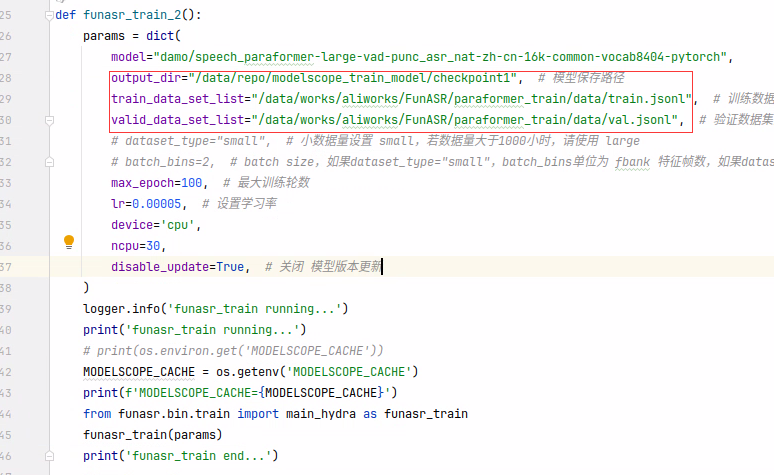
数据集:
训练完成输出信息