
 4000积分,罗技无线鼠标*2
4000积分,罗技无线鼠标*2
AIGC是指通过人工智能技术自动生成内容的生产方式,已经成为继互联网时代的下一个产业时代风口。其中,文生图(Text-to-image Generation)任务是流行的跨模态生成任务,旨在生成与给定文本对应的图像。WebUI文生图推理效果如图所示。
现邀请您使用阿里云交互式建模(PAI-DSW),基于Diffusers开源库进行AIGC Stable Diffusion模型的微调训练,以及启动WebUI进行模型推理(点击https://developer.aliyun.com/adc/scenario/45863d6684d04656b1553478d9147b61即可开始操作)并分享配置过程、输出结果及使用体验。
本期话题:基于PAI-DSW,打造定制化文生图工具,分享配置过程、输出结果及使用体验
话题规则:
1、使用https://developer.aliyun.com/adc/scenario/45863d6684d04656b1553478d9147b61进行操作。
2、话题讨论要求围绕指定方向展开,分享配置过程、输出结果及使用体验的截图和操作记录。
3、图文并茂,字数少于50字无效,言之无物无效,无具体讨论的回复将会视为无效回复,对于无效回复工作人员有权删除。
配置过程: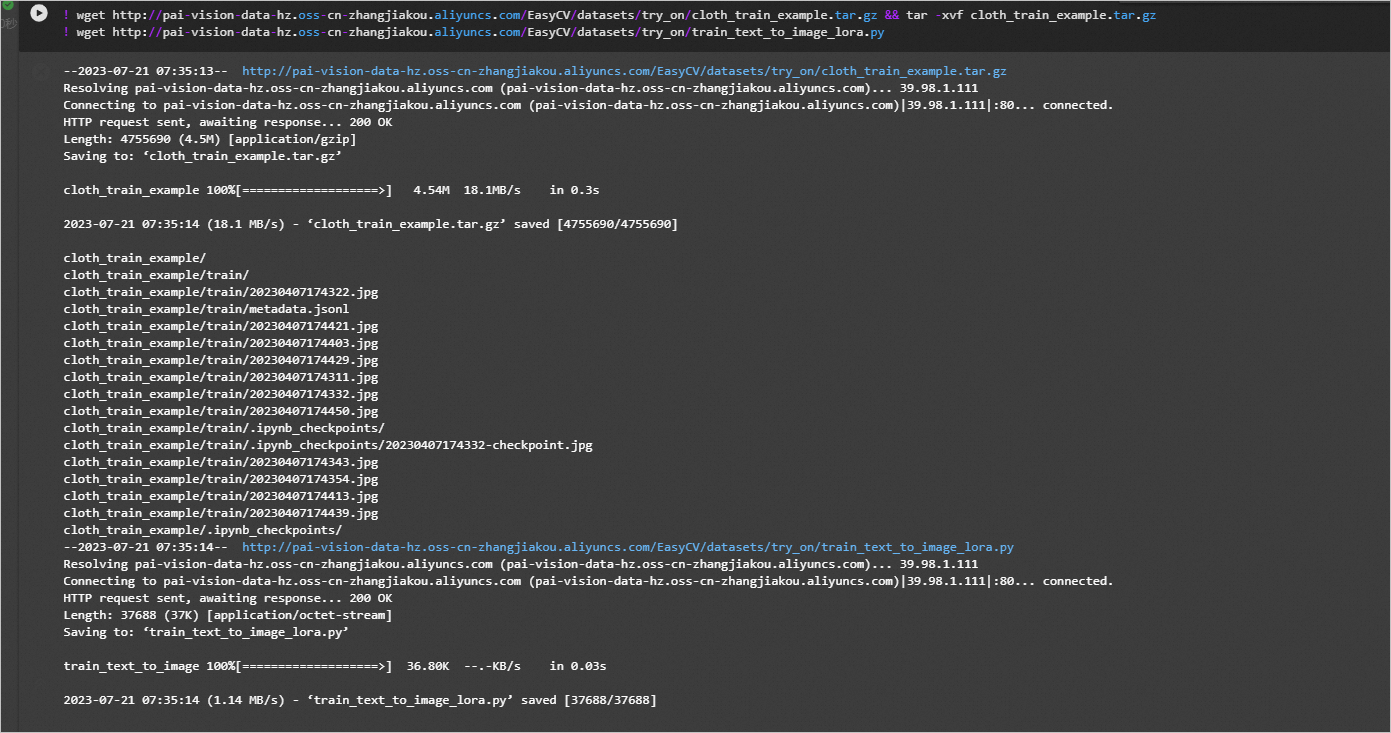

输出结果: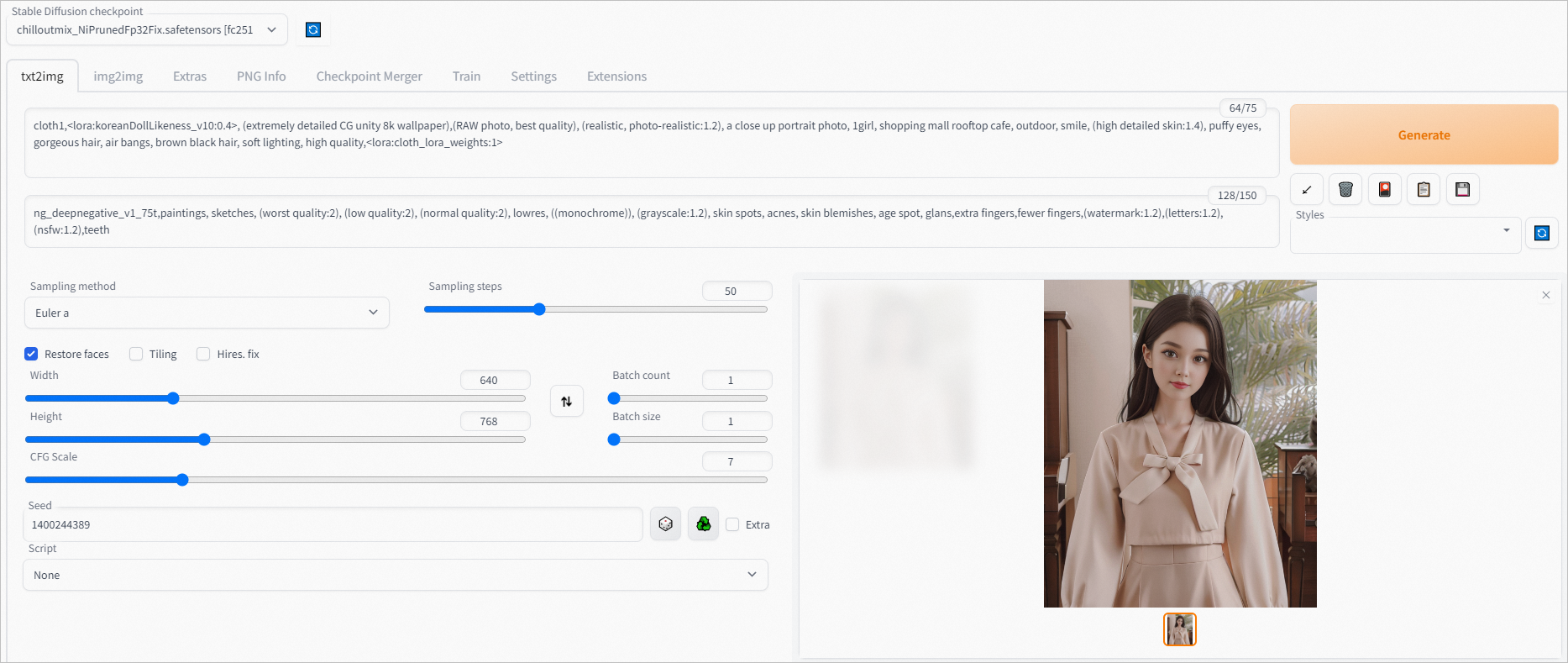
本期奖品:截止2024年8月16日24时,参与本期话题讨论,将会选出2个优质回答获得罗技M172无线鼠标。快来参加讨论吧~
优质回答获奖规则:字数不少于100字,明确清晰的配置过程、详细的使用体验分享。内容阳光积极,健康向上。
未获得实物奖品者,按要求完成回复的参与者均可获得20积分奖励。所获积分可前往积分商城进行礼品兑换。
注:讨论内容要求原创,如有参考,一律注明出处,如有复制抄袭、不当言论等回答将不予发奖。阿里云开发者社区有权对回答进行删除。获奖名单将于活动结束后5个工作日内公布,奖品将于7个工作日内进行发放,节假日顺延。
中奖用户:
截止到8月16日共收到48条有效回复,获奖用户如下
优质回答:穿过生命散发芬芳、DreamSpark
恭喜以上用户!感谢大家对本话题的支持~
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
基于PAI-DSW,打造定制化文生图工具,分享使用体验
首先,通过PAI-DSW创建Notebook实例并安装Diffusers、Stable-Diffusion-WebUI等必要库。
接着,准备训练所需的文本及图像数据集。
在Notebook中加载Stable Diffusion模型并使用Diffusers进行微调,同时设置LoRA参数。
最后,配置WebUI启动交互界面,并设置API以实现模型推理功能。
文档提供了丰富详尽的场景描述与配置指南,助您快速理解内容并进行实操。
无论是初学者还是有经验的用户,都能从中受益,轻松掌握所需技能和知识,高效完成任务。
该系统在运行过程中显示出了极高的灵敏性和快速响应能力,能即时满足用户需求。在整个操作过程中,没有出现过任何卡顿或是延迟的情况,这极大保证了用户流畅、无阻的操作体验。
基于PAI-DSW,打造定制化文生图工具,分享使用体验
基于阿里云机器学习平台PAI的数据科学工作坊(PAI-DSW),构建定制化文本生成图像应用。
涵盖模型训练、部署及使用等关键步骤,极大地提升了个性化图像生成的可能性,为用户打造从数据处理到模型应用的一站式解决方案。
确保已激活PAI-DSW服务并建立工作空间,从阿里云免费试用中心获取资源包。
登录PAI控制台后,选择“交互式建模(DSW)”来创建实例,需要指定实例名称、GPU型号(推荐ecs.gn6v-c8g1.2xlarge)及镜像版本。
实例启动后,在Notebook中搜索基于Diffusion模型的中文教程,例如AIGC Stable Diffusion的Lora微调教程,并安装所需库(如Diffusers)。
下载预训练模型开始训练过程,根据需求调整学习率等参数以优化模型效果。
PAI-DSW提供了一个直观简便的开发环境,支持用户通过Notebook进行流畅的代码编写与命令执行。
它利用EAS服务简化了模型部署过程,即便不具备深厚底层技术知识,也能实现模型的快速上线和运行,整体操作极为简单快捷。
阿里云EAS服务供应优质计算资源与稳定网络环境,确保模型推理高效稳定,使用户随时随地获取高品质图像生成结果。
基于PAI-DSW,打造定制化文生图工具,分享使用体验
在数字化浪潮中,“AI动手”应运而生,这是一款革命性的定制化文生图工具。
它采用先进的自然语言处理和深度学习技术,能精准捕捉并理解文字中的情感与想象,将其瞬间转化为独一无二的图像作品。
无论是水彩画、数字艺术,还是复古海报和未来科幻场景,丰富的风格模板及个性化设置选项让创意无限延伸。
此外,“AI动手”还支持持续学习和用户反馈优化,以确保每次使用都能更好地满足的需求,为创造更满意的视觉体验。
基于PAI-DSW,打造定制化文生图工具,分享使用体验
AI动手是一款集成人工智能与图形设计的定制化文本转图像工具。通过自然语言处理及图像生成技术,它能够实现从文字描述到图像创作的无缝对接,为用户提供高效且个性化的创作体验。
运用高性能计算资源进行深度学习模型训练,实现从文本信息中自动抽取关键元素并生成对应的图像。在训练过程中,我们不断优化调整超参数以提升所生成图像的精度和质量。
模型选择的过程,特别是适用于从文本生成图像的任务。需要挑选出合适的生成模型,例如基于生成对抗网络(GAN)或是扩散模型等结构。经过训练后,这些模型能够实现从输入的文字描述中生成对应的图像的目标。
基于PAI-DSW,打造定制化文生图工具,分享使用体验
该架构首次融合了Transformer与GANs/Diffusion Models技术,其中Transformer深度处理文本以精准捕捉语义及上下文关联;而GANs或Diffusion Models则基于处理后的文本生成对应的图像内容,创造性地完成从文本到图像的转换。
数据集包含文本与图像两部分,文本部分涵盖了多样化的图像描述信息,包括句子、段落及标签等;
图像部分则是对应的图片集合,确保每张图片与其描述精准匹配。
此外,还提供了数据预处理流程,涉及文本清洗、分词编码以及图像的尺寸调整和归一化等关键步骤。
专注于定制化开发,主打特色包括简洁友好的用户界面,支持文本输入和图像展示。
提供参数调节选项,允许用户自定义风格、色彩及分辨率等属性。
集成的风格迁移技术能够实现多种艺术风格的选择和应用,为您打造独一无二的个性化图像生成体验。
准备数据集及训练代码。
我们提供了训练代码及一个小的示例数据,可以参照该格式准备自定义数据。
在JupyterLab的Notebook中,执行如下命令,下载示例数据集。后续会使用该数据集进行模型训练。
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/cloth_train_example.tar.gz && tar -xvf cloth_train_example.tar.gz
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/train_text_to_image_lora.py
系统输出如图结果,表示代码执行成功。
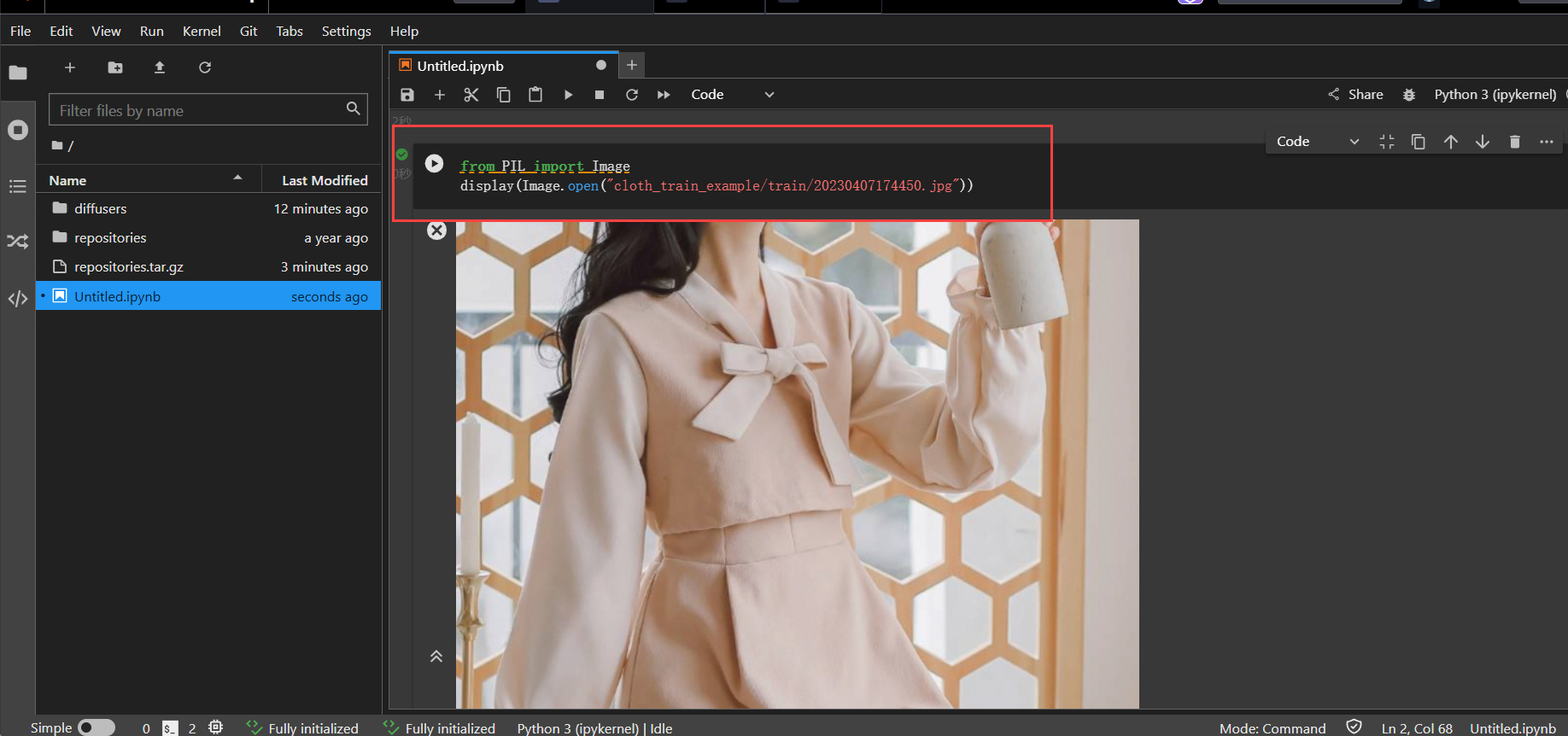
执行如下命令,查看示例服装。
from PIL import Image
display(Image.open("cloth_train_example/train/20230407174450.jpg"))

执行如下命令,下载预训练模型并转化成diffusers格式。
说明:为了加速下载我们在oss做了缓存,用户可以运行如下命令直接下载,用户也可前往hugging face官网下载。
safety_checker_url = f"{prefix}/aigc-data/hug_model/models--CompVis--stable-diffusion-safety-checker.tar.gz"
aria2(safety_checker_url, safety_checker_url.split("/")[-1], "./")
! tar -xf models--CompVis--stable-diffusion-safety-checker.tar.gz -C /root/.cache/huggingface/hub/
clip_url = f"{prefix}/aigc-data/hug_model/models--openai--clip-vit-large-patch14.tar.gz"
aria2(clip_url, clip_url.split("/")[-1], "./")
! tar -xf models--openai--clip-vit-large-patch14.tar.gz -C /root/.cache/huggingface/hub/
model_url = f"{prefix}/aigc-data/sd_models/chilloutmix_NiPrunedFp32Fix.safetensors"
aria2(model_url, model_url.split("/")[-1], "stable-diffusion-webui/models/Stable-diffusion/")
! python diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py \
--checkpoint_path=stable-diffusion-webui/models/Stable-diffusion/chilloutmix_NiPrunedFp32Fix.safetensors \
--dump_path=chilloutmix-ni --from_safetensors
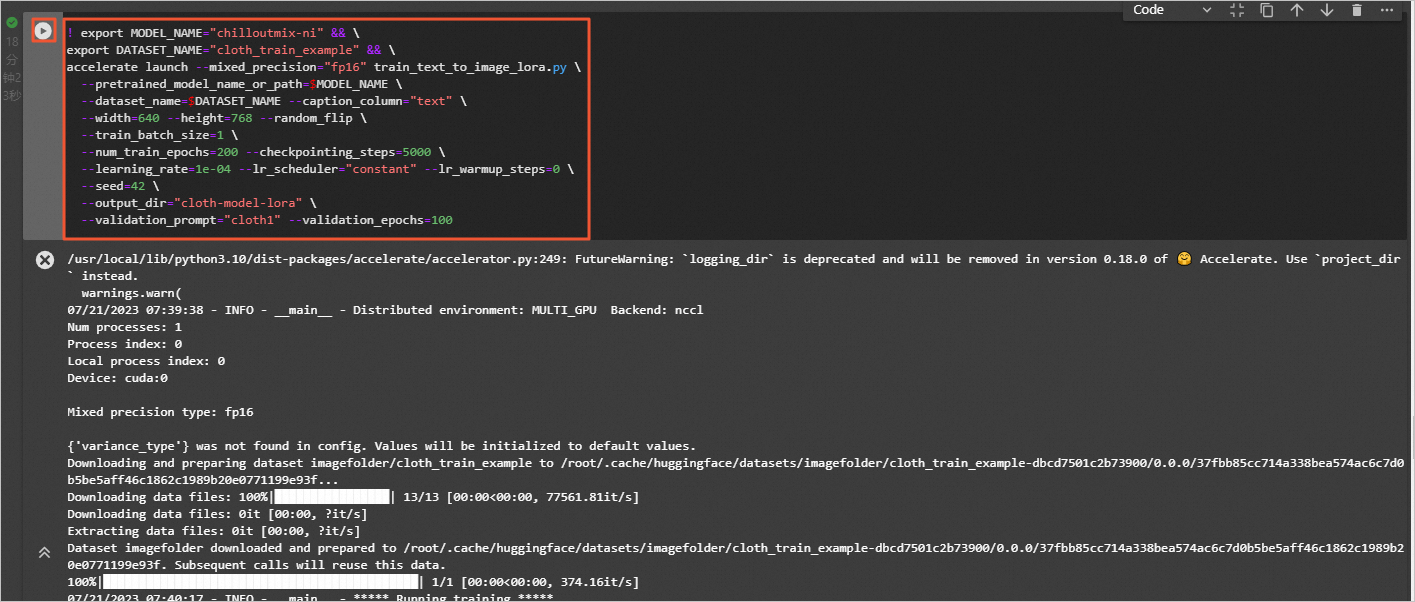
模型训练。执行如下命令,设置num_train_epochs为200,进行lora模型的训练。
! export MODEL_NAME="chilloutmix-ni" && \
export DATASET_NAME="cloth_train_example" && \
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--width=640 --height=768 --random_flip \
--train_batch_size=1 \
--num_train_epochs=200 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="cloth-model-lora" \
--validation_prompt="cloth1" --validation_epochs=100
``` 
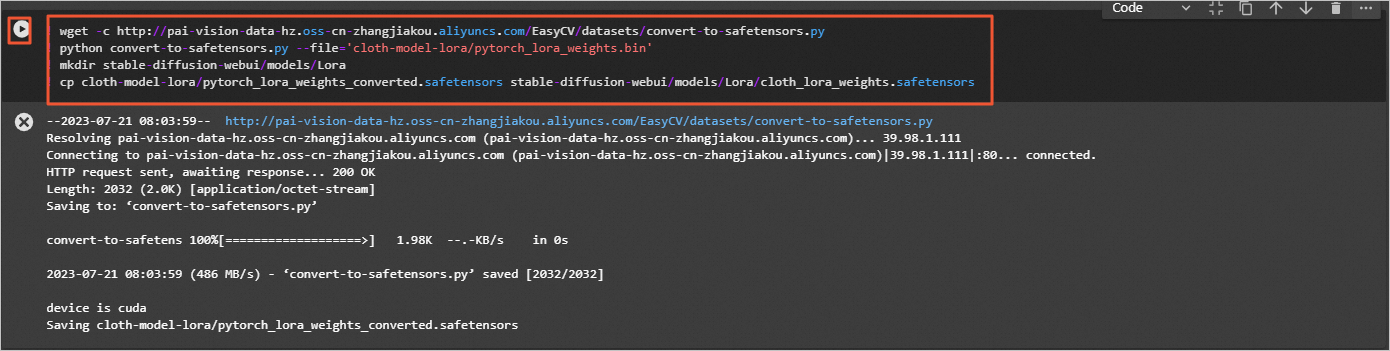
准备WebUI所需模型文件。
将lora模型转化成WebUI支持格式并拷贝到WebUI所在目录。
```js
! wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/convert-to-safetensors.py
! python convert-to-safetensors.py --file='cloth-model-lora/pytorch_lora_weights.bin'
! mkdir stable-diffusion-webui/models/Lora
! cp cloth-model-lora/pytorch_lora_weights_converted.safetensors stable-diffusion-webui/models/Lora/cloth_lora_weights.safetensors
``` 
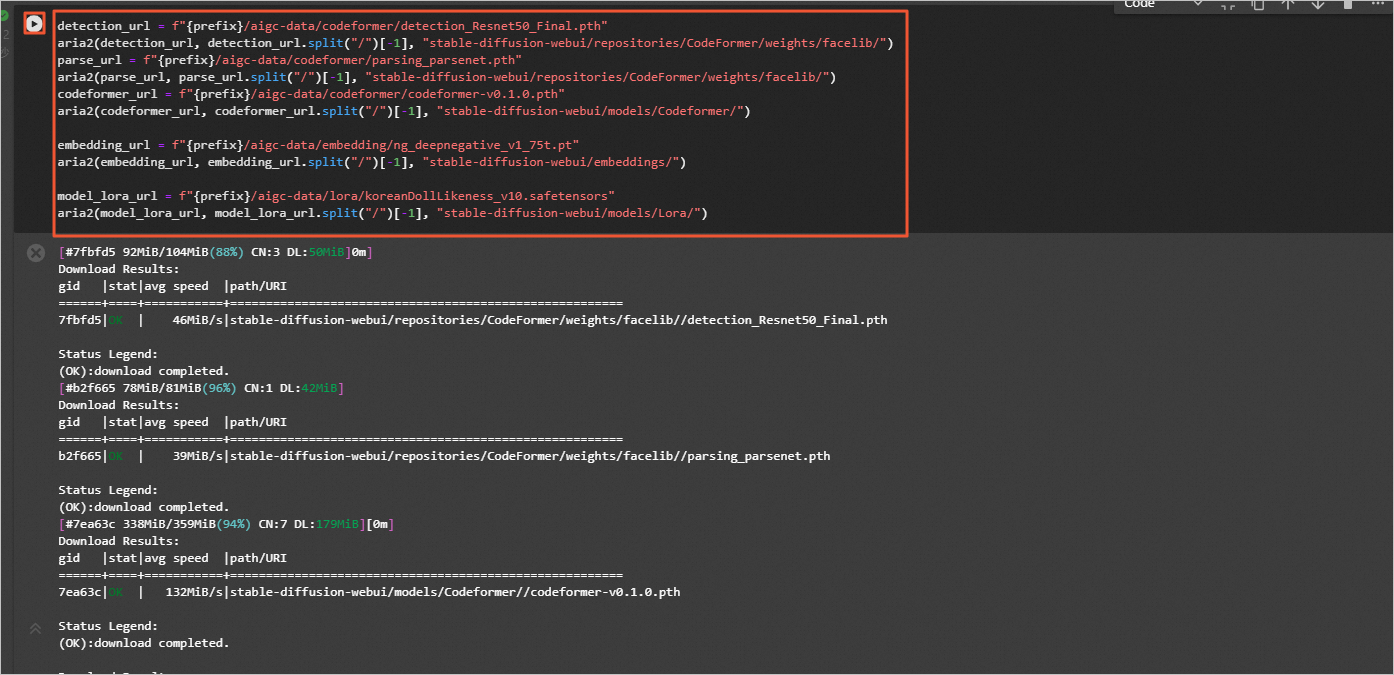
准备额外模型文件。
为了加速下载我们在oss做了缓存,用户可以运行如下命令直接下载。
```js
detection_url = f"{prefix}/aigc-data/codeformer/detection_Resnet50_Final.pth"
aria2(detection_url, detection_url.split("/")[-1], "stable-diffusion-webui/repositories/CodeFormer/weights/facelib/")
parse_url = f"{prefix}/aigc-data/codeformer/parsing_parsenet.pth"
aria2(parse_url, parse_url.split("/")[-1], "stable-diffusion-webui/repositories/CodeFormer/weights/facelib/")
codeformer_url = f"{prefix}/aigc-data/codeformer/codeformer-v0.1.0.pth"
aria2(codeformer_url, codeformer_url.split("/")[-1], "stable-diffusion-webui/models/Codeformer/")
embedding_url = f"{prefix}/aigc-data/embedding/ng_deepnegative_v1_75t.pt"
aria2(embedding_url, embedding_url.split("/")[-1], "stable-diffusion-webui/embeddings/")
model_lora_url = f"{prefix}/aigc-data/lora/koreanDollLikeness_v10.safetensors"
aria2(model_lora_url, model_lora_url.split("/")[-1], "stable-diffusion-webui/models/Lora/")
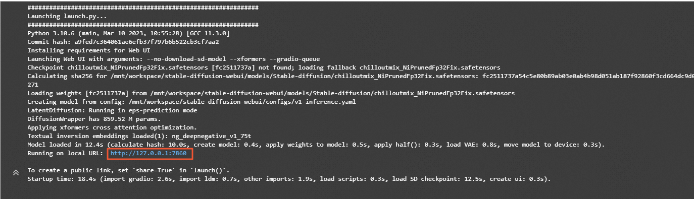
在JupyterLab的Notebook中,执行如下命令,启动WebUI。
说明:由于Github访问存在不稳定性,如果运行后未出现正常返回结果且提示网络相关原因,例如:Network is unreachable、unable to access 'https://github.com/......',您可以重新运行命令。
! cd stable-diffusion-webui && python -m venv --system-site-packages --symlinks venv
! cd stable-diffusion-webui && \
sed -i 's/can_run_as_root=0/can_run_as_root=1/g' webui.sh && \
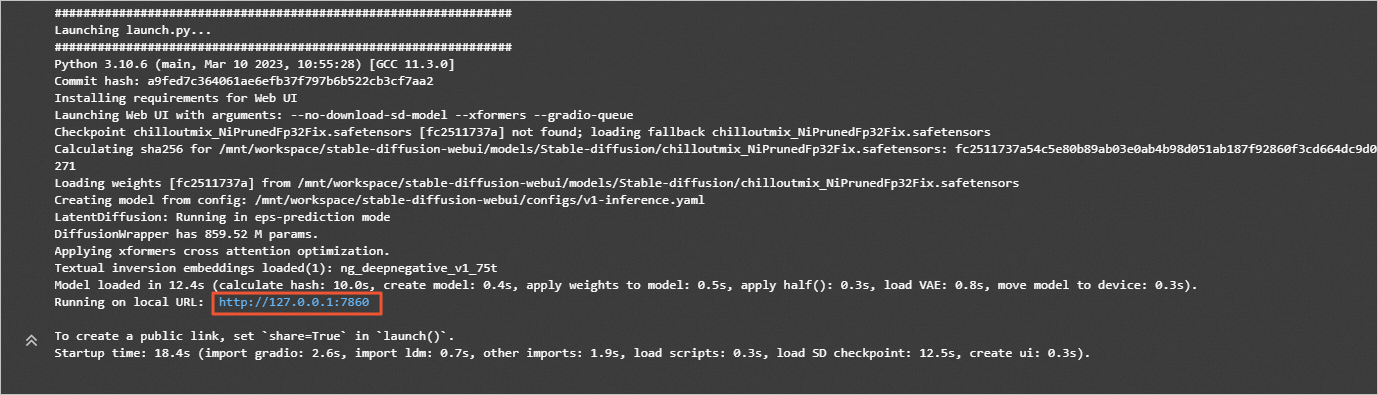
./webui.sh --no-download-sd-model --xformers --gradio-queue
在返回结果中,单击URL链接(http://127.0.0.1:7860),进入WebUI页面。后续您可以在该页面,进行模型推理。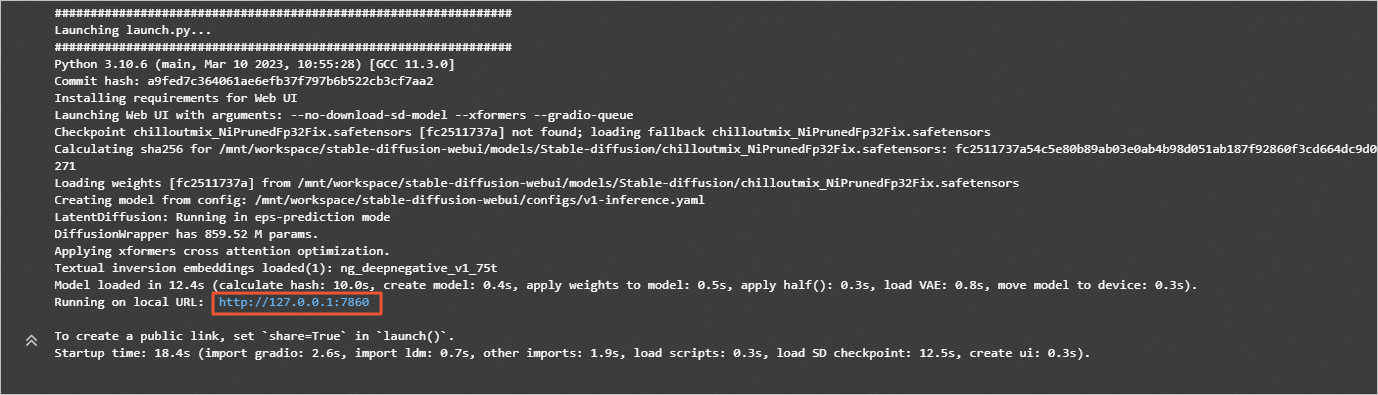
完成以上操作后,您已经成功完成了AIGC文生图模型微调训练及WebUI部署。您可以在WebUI页面,进行模型推理验证。
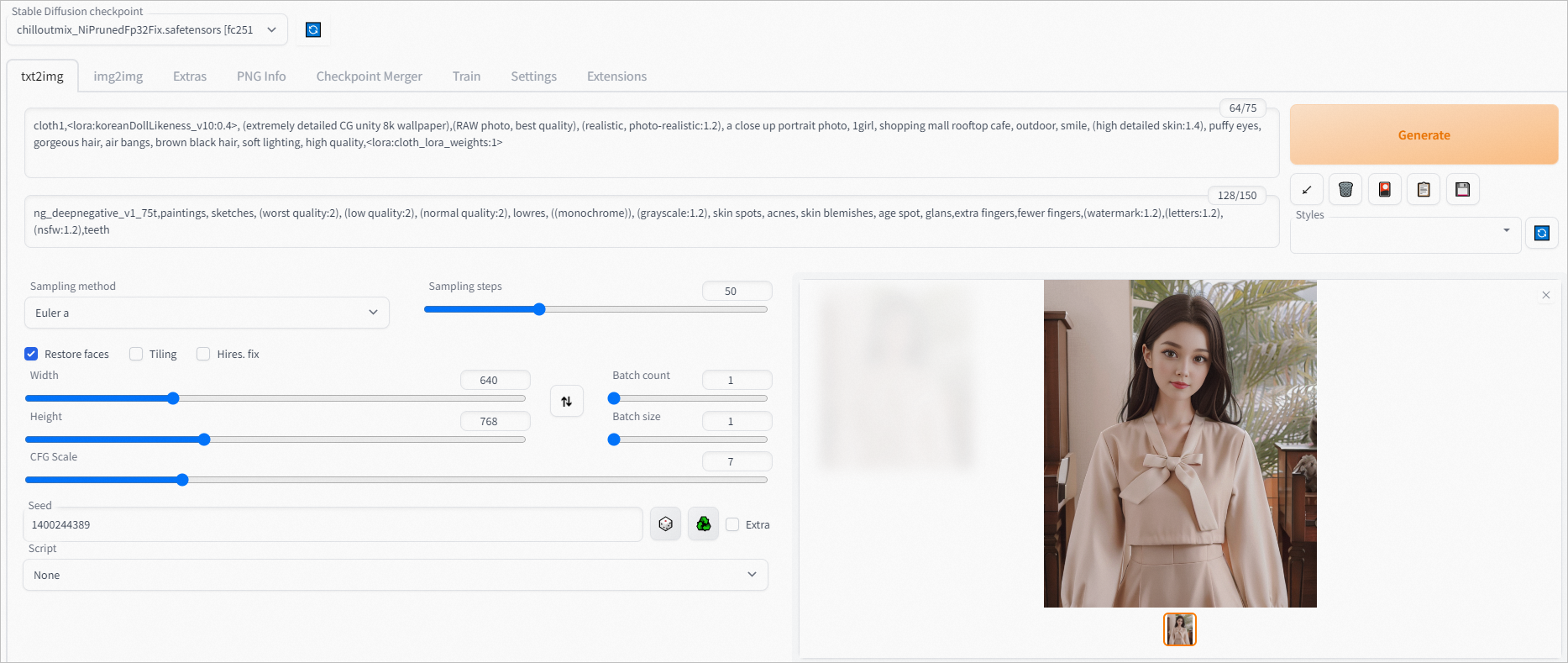
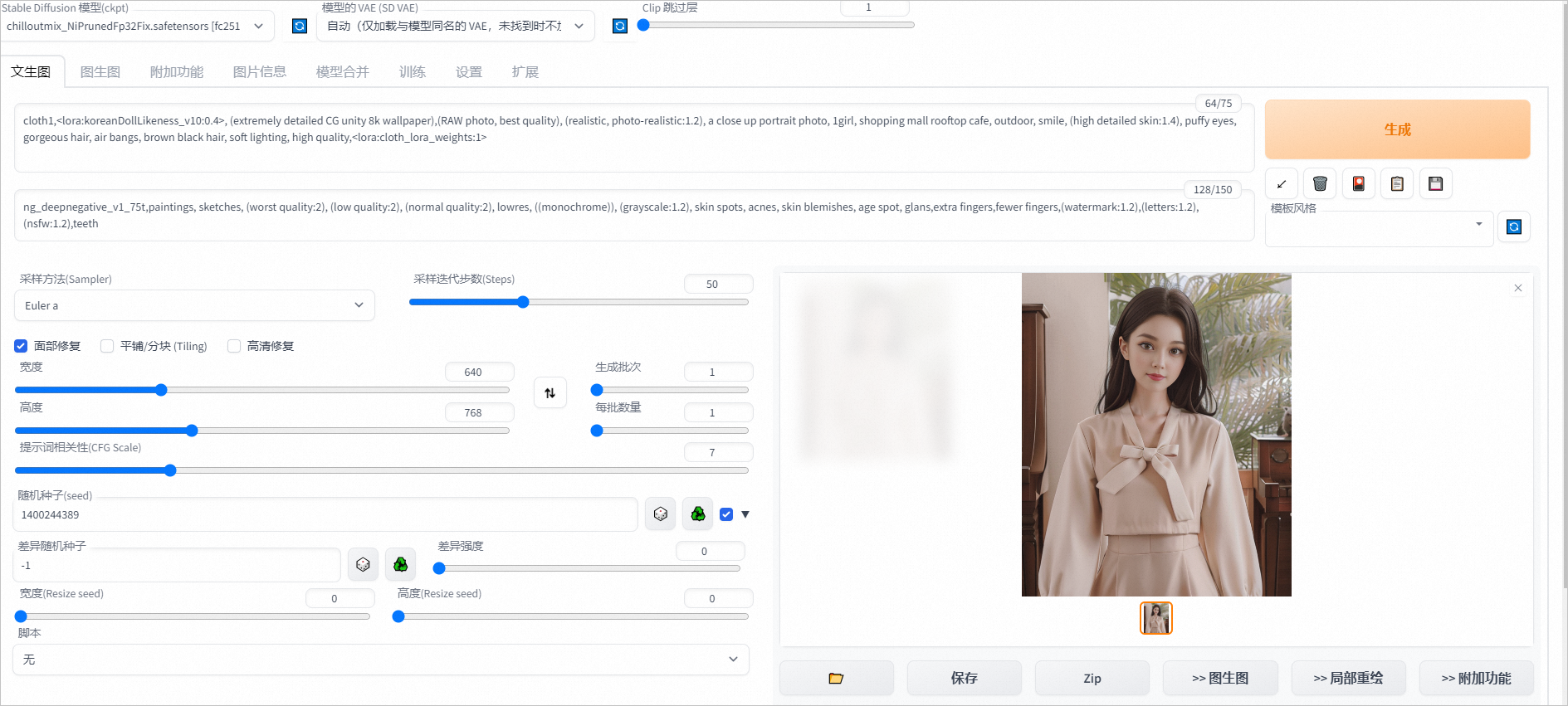
在文生图页签通过下方设置可从示例衣服生成如下图片。
正向prompt:cloth1,, (extremely detailed CG unity 8k wallpaper),(RAW photo, best quality), (realistic, photo-realistic:1.2), a close up portrait photo, 1girl, shopping mall rooftop cafe, outdoor, smile, (high detailed skin:1.4), puffy eyes, gorgeous hair, air bangs, brown black hair, soft lighting, high quality,
负向prompt:ng_deepnegative_v1_75t,paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), (grayscale:1.2), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,(watermark:1.2),(letters:1.2),(nsfw:1.2),teeth
采样方法:Euler a
采样步数:50
宽高: 640,768
随机种子:1400244389
CFG Scale:7
使用面部修复
单击Generate,输出如图推理结果。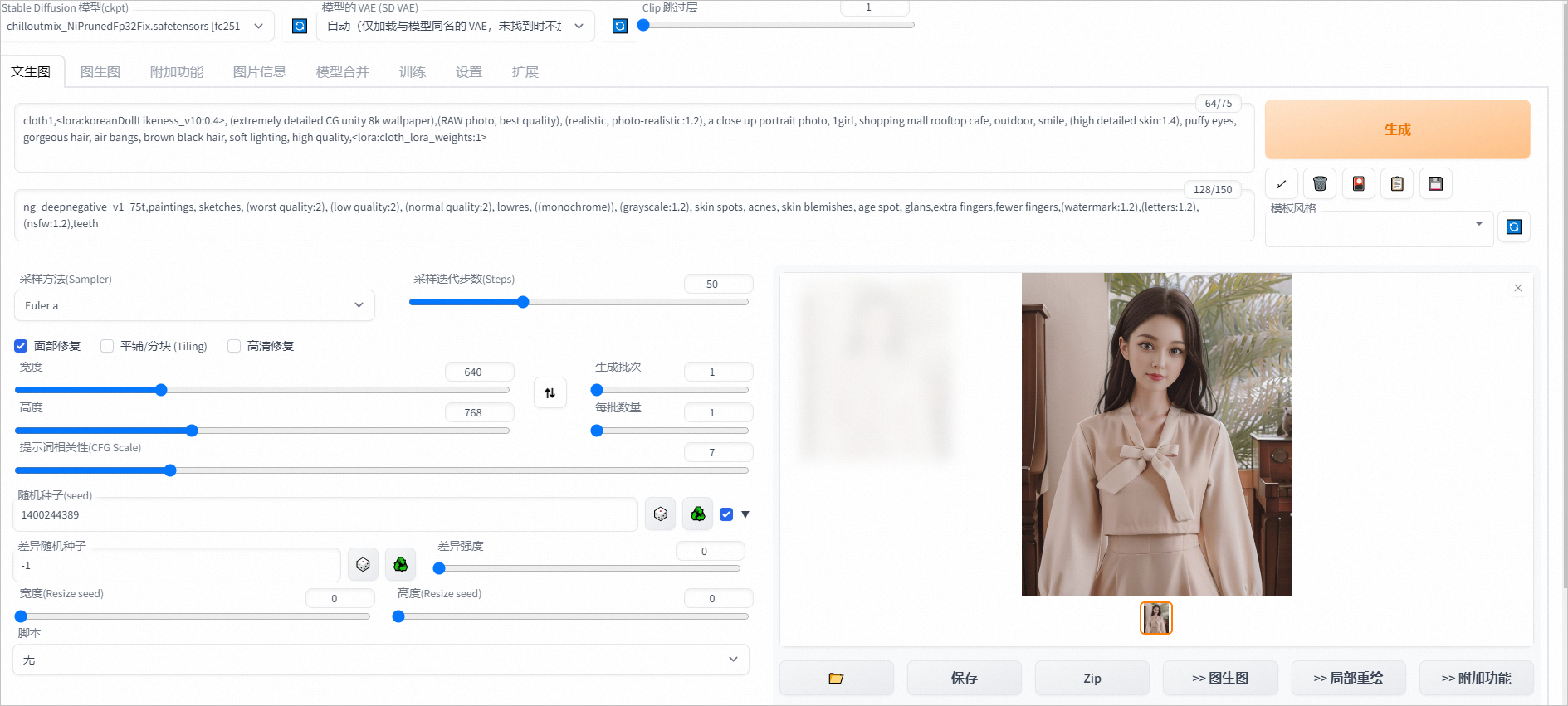
清理
如果无需继续使用DSW实例,您可以按照以下操作步骤停止DSW实例。
登录PAI控制台。
在页面左上方,选择DSW实例的地域。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击默认工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择模型开发与训练>交互式建模(DSW),进入交互式建模(DSW)页面。
单击目标实例操作列下的停止,成功停止后即停止资源消耗。
领取免费资源包后,请在免费额度和有效试用期内使用。如果免费额度用尽或试用期结束后,继续使用计算资源,会产生后付费账单。
请前往资源实例管理页面,查看免费额度使用量和过期时间,如下图所示。
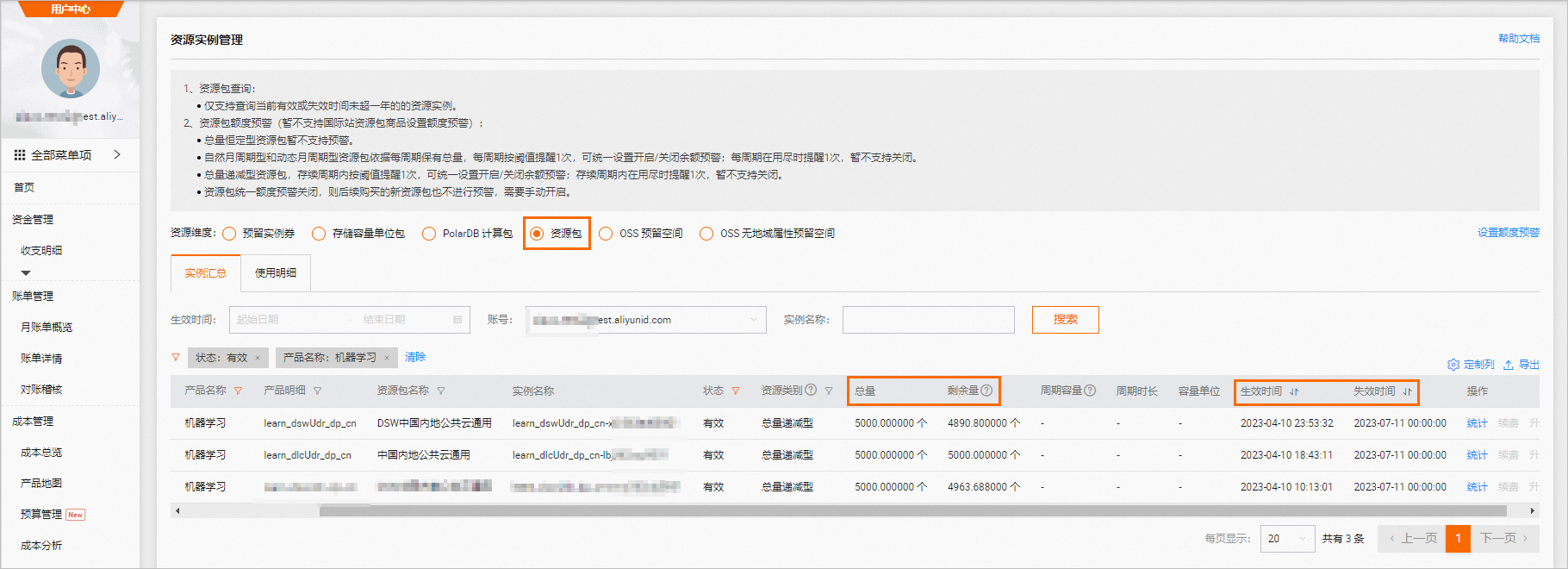
如果需要继续使用DSW实例,请务必至少在试用到期1小时前为您的阿里云账号充值,到期未续费的DSW实例会因欠费而被自动停止。
打造一个定制化的文生图工具(AI动手)是将人工智能与图形设计相结合的创新应用。这个工具旨在通过自然语言处理技术和图像生成技术,实现从文字描述到图像创作的自动化。
首先,用户可以输入详细的文字描述,包括主题、风格、色彩等要求。AI系统会通过深度学习模型理解文本内容,并生成符合描述的图像。例如,描述一个“温馨的家庭聚会”可以自动生成相应的场景图,满足用户的需求。
其次,定制化文生图工具支持多种风格和风格混搭。用户可以选择不同的艺术风格,如水彩、素描或油画等,也可以结合多种风格,创建出独特的图像。这种灵活性满足了用户在创作上的个性化需求。
此外,工具还可以集成图像编辑功能,允许用户对生成的图像进行进一步的调整和优化。这种交互式的设计使得用户能够更精确地实现他们的创意构想。
最后,通过不断优化的算法和丰富的训练数据,工具可以不断提升生成图像的质量和准确性,使用户获得更高水平的图像创作体验。这个定制化文生图工具不仅提升了创作效率,也为个人和企业提供了更多创意表达的可能性。
打造一个定制化的AI文生图工具,能够帮助用户将文字描述转化为生动的图像,这是一个结合自然语言处理和计算机视觉的创新项目。这个工具的核心在于理解用户的文字输入,并通过深度学习模型生成与描述相符的高质量图像。以下是构建该工具的一些关键步骤:
需求分析:首先,明确目标用户和使用场景。例如,是为设计师提供创意支持,还是为社交媒体用户生成视觉内容。根据需求确定工具的功能和性能要求。
模型选择:选择合适的生成模型,如基于生成对抗网络(GAN)或扩散模型的架构。这些模型能够在训练后,接收文字描述并生成对应图像。
数据准备:收集并清洗大量的图文配对数据,用于训练模型。数据质量直接影响生成效果,因此需要多样化、准确性高的训练集。
模型训练:利用高性能计算资源,训练模型使其能够从文字描述中提取出核心信息并生成图像。训练过程中需调整超参数以优化生成质量。
界面设计:开发直观的用户界面,允许用户输入文本描述、选择风格、调整细节。实时预览功能可以帮助用户看到图像生成的过程和结果。
测试与优化:通过多轮测试,优化生成效果,确保工具在不同输入情况下都能稳定输出高质量图像。
部署与维护:将工具部署到云端或本地,确保用户可以随时访问和使用。同时,定期更新模型以提升生成效果。
【AI动手】:打造个性化文生图神器
在创意无限的数字时代,我们自豪地推出“AI动手”——一款革命性的定制化文生图工具。通过先进的自然语言处理与深度学习技术,“AI动手”能精准捕捉您文字中的情感、细节与想象,瞬间转化为栩栩如生、独一无二的图像作品。
无论您是艺术家寻找灵感火花,作家希望视觉化故事场景,还是设计师渴望快速原型设计,“AI动手”都能满足您的需求。它提供丰富的风格模板与个性化设置选项,从细腻的水彩画到前卫的数字艺术,从复古海报到未来科幻场景,一键切换,让创意无限延伸。
更重要的是,“AI动手”支持持续学习与用户反馈优化,随着每一次使用,它将更加懂您,为您打造更加贴合心意的视觉盛宴。现在就加入我们,用“AI动手”开启您的定制化文生图之旅,让想象触手可及!
要使用阿里云交互式建模(PAI-DSW),基于Diffusers开源库进行AIGC Stable Diffusion模型的微调训练,我们可以遵循以下步骤进行配置、训练和部署,并分享整个过程中的体验。请注意,由于直接访问和操作链接可能因时间或权限问题而有所变化,以下步骤基于一般流程和阿里云PAI服务的常见特性。
1.访问链接:首先,访问提供的链接https://developer.aliyun.com/adc/scenario/45863d6684d04656b1553478d9147b61),这应该会引导你进入阿里云PAI-DSW的页面。如下图所示:
2.登录与领取使用:使用你的阿里云账号登录,本次体验使用到阿里云交互式建模(PAI-DSW),如果你是新用户,则可以先领取产品试用。点击前往,领取试用。如下图所示:
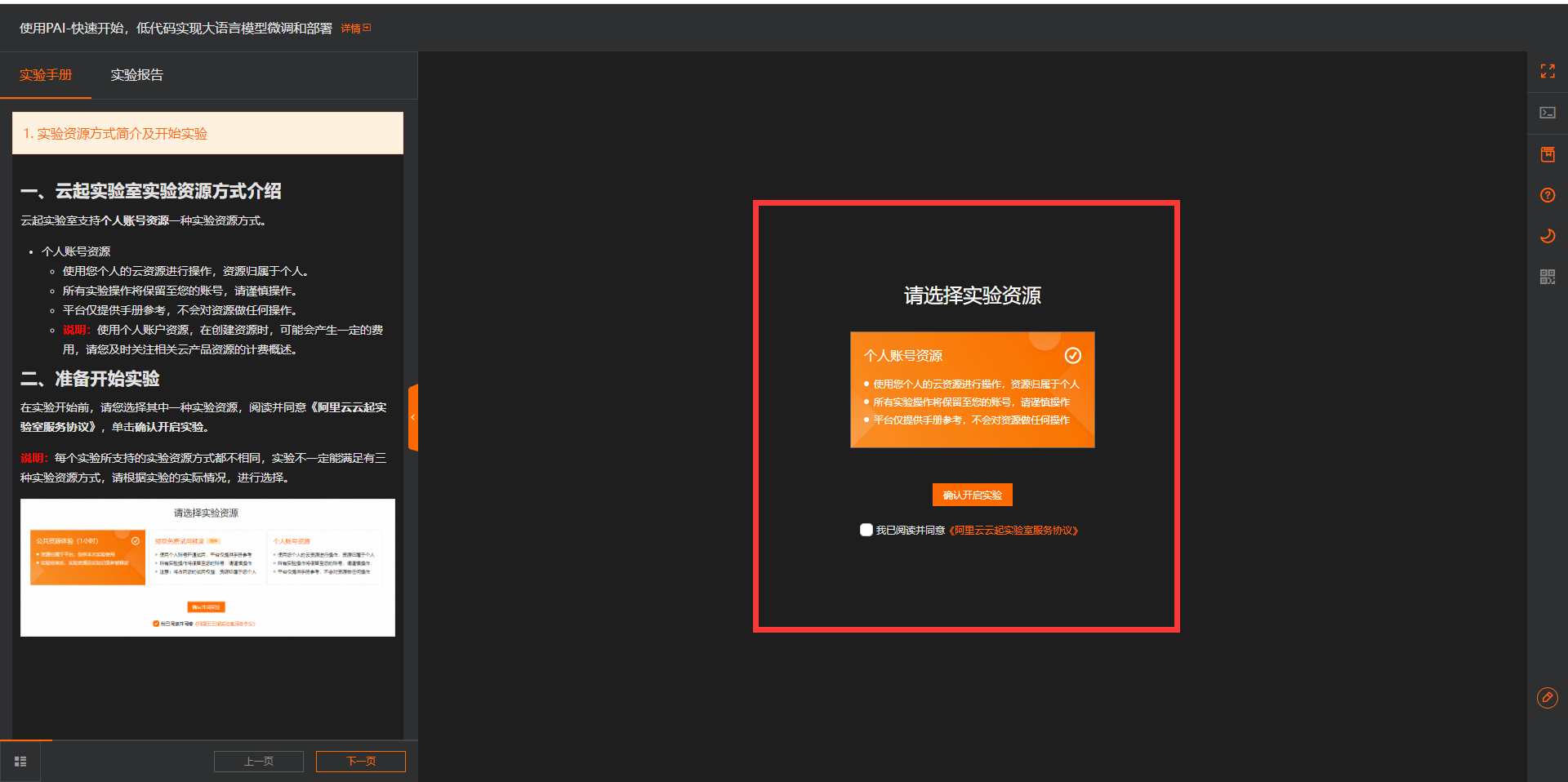
1.登录PAI控制台,如果你是首次使用PAI,会需要先开通个默认的工作空间。如下:
2.为了方便,这里地域就直接选择了杭州。如下: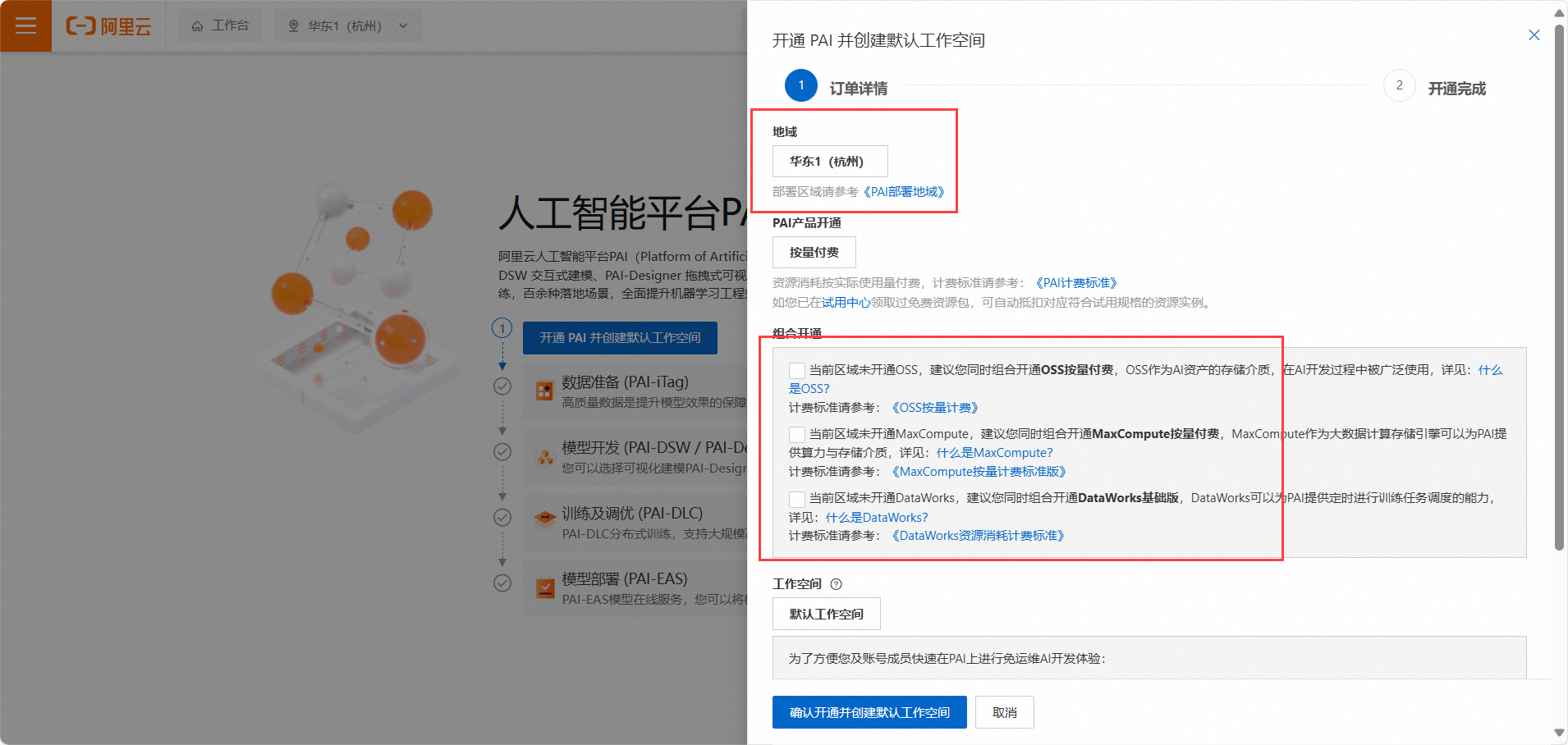
3.由于本次体验不需要开通其他产品,所以组合服务这里取消默认的组合服务勾选,以免产生不必要的费用。首次开通需要授权,点击授权前往RAM访问控制。如下所示:
4.点击同意授权即可。如下图所示: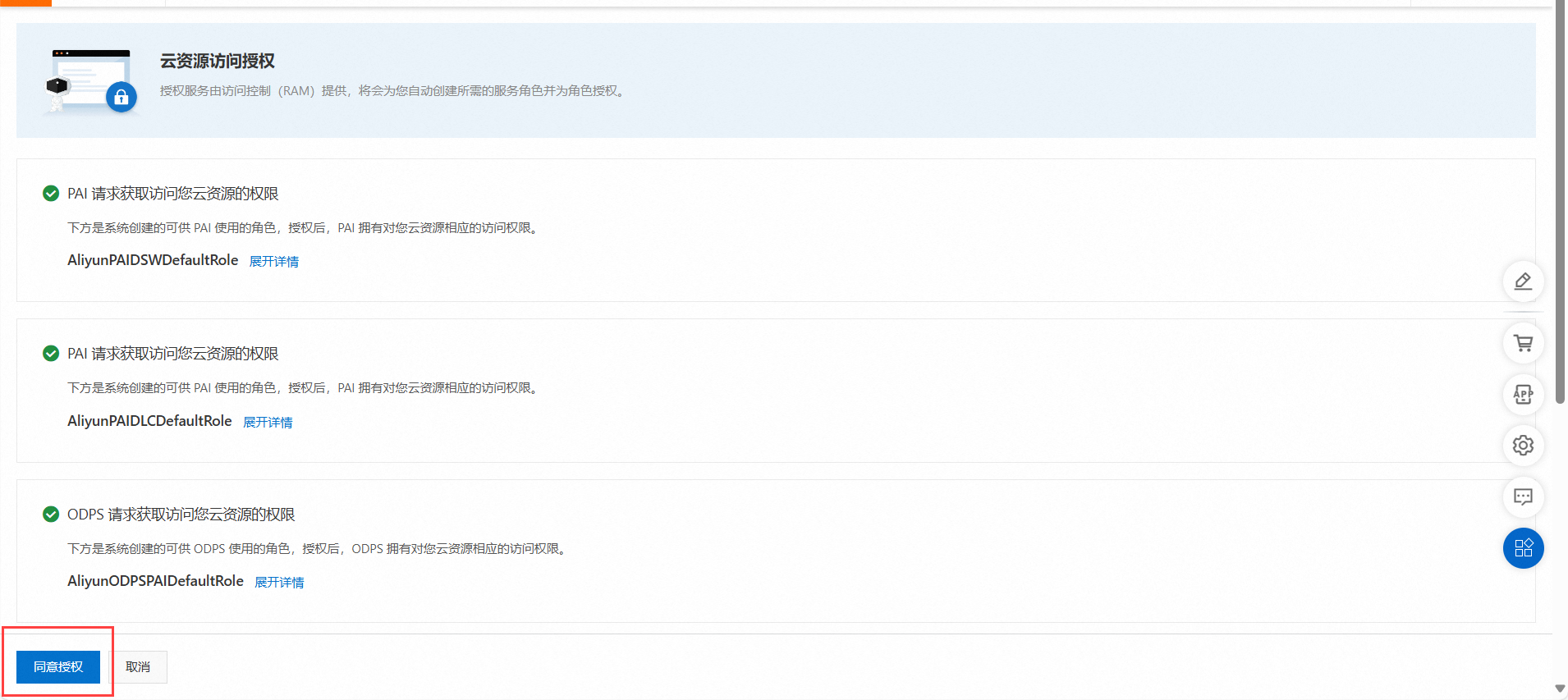
5.完成授权后返回点击刷新,继续点击“确认开通并创建默认工作空间”。稍等一会完成工作空间的开通。如下图所示:
进入PAI控制台,在左侧导航栏中单击工作空间列表,选择交互式建模(DSW),点击新建实例。如下图所示:
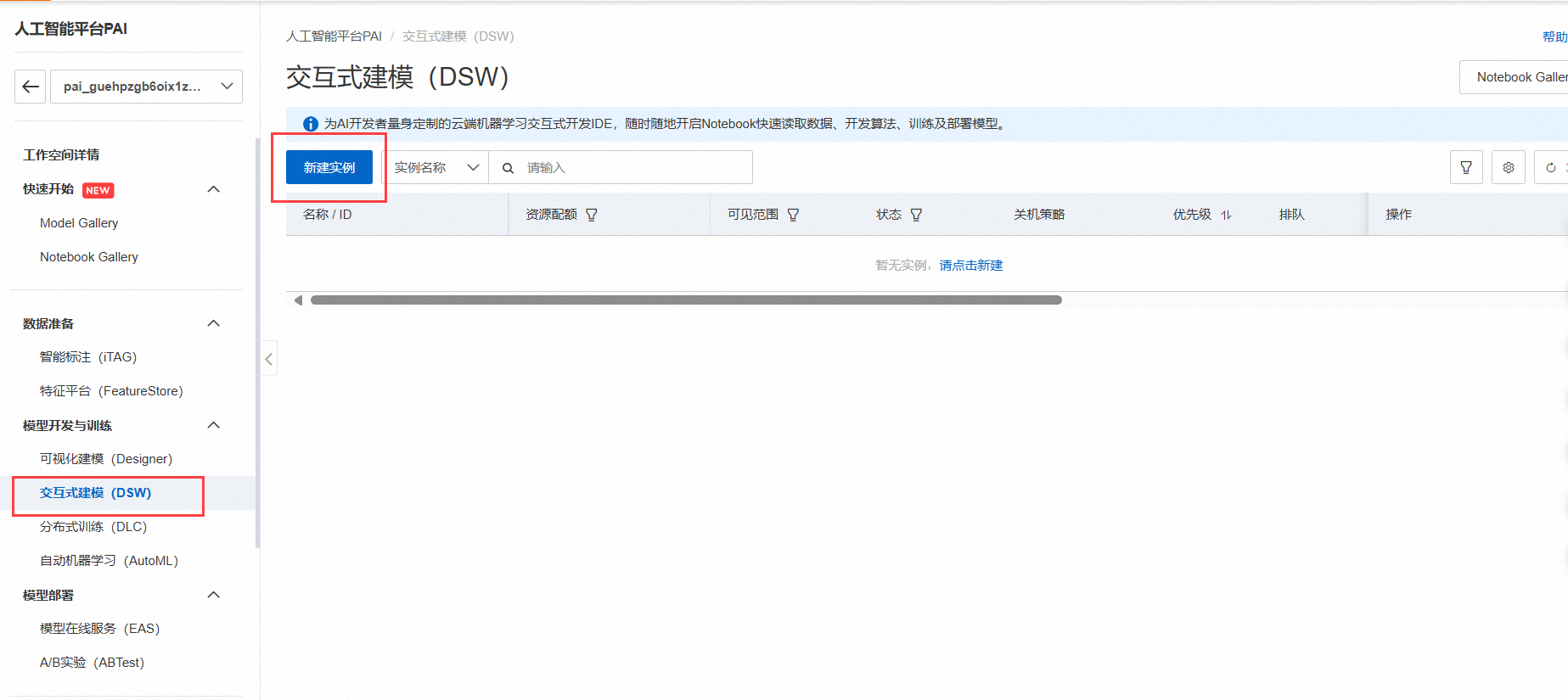
单击快速开始区域Notebook下的Python 3(ipykernel),如下图所示: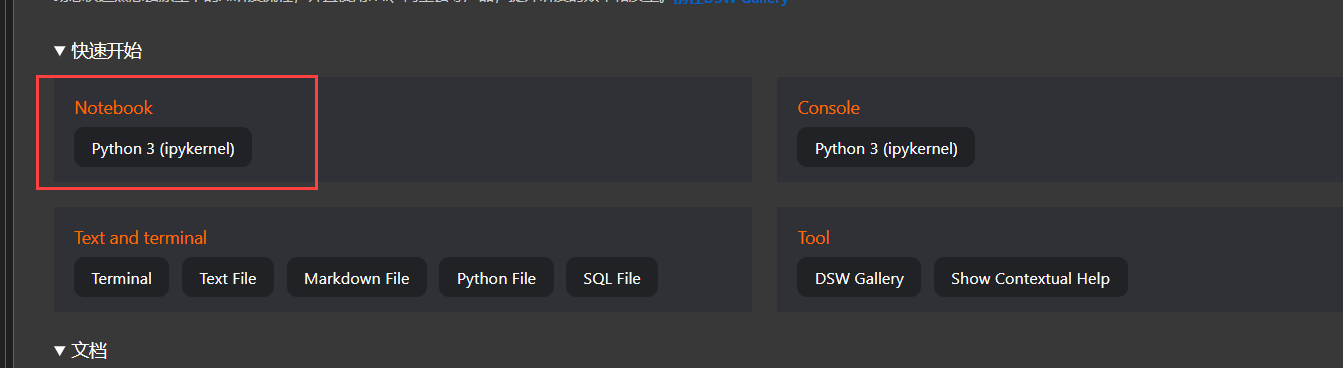
从GitHub下载Diffusers开源库,并安装相关依赖:
! git clone https://github.com/huggingface/diffusers
! cd diffusers && git checkout e126a82cc5d9afbeb9b476455de24dd3e7dd358a
! cd diffusers && pip install .
按照操作说明文档即可!
示例代码片段:
from diffusers import StableDiffusionPipeline
from transformers import CLIPProcessor
# 加载预训练模型和处理器
model_id = "CompVis/stable-diffusion-v1-4"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
processor = CLIPProcessor.from_pretrained(model_id)
# 假设已有加载和预处理数据的函数
train_dataset = load_and_preprocess_dataset()
# 微调模型(此处仅为示意,具体实现需根据数据集和需求编写)
# train_model(pipe, train_dataset, epochs=10)
可视化:虽然本例中未直接展示WebUI的详细配置,但基于PAI-DSW的Web服务部署功能,可以方便地构建用户友好的Web界面,实现文本到图像的即时转换和展示。
文档与支持:阿里云提供了详尽的文档和强大的技术支持,帮助开发者在使用过程中遇到的问题得到及时解决。
总的来说,基于阿里云PAI-DSW平台打造定制化文生图工具是一次非常愉快且高效的体验,为AI内容生成领域的研究和应用提供了强有力的支持。
配置过程非常直观,PAI-DSW提供了强大的GPU资源,这使得模型训练速度非常快。阿里云提供的文档清晰易懂,有助于快速上手。
AIGC是指通过人工智能技术自动生成内容的生产方式,已经成为继互联网时代的下一个产业时代风口。其中文生图也有了飞速的发展,这里将介绍如何自己部署基于PAI-DSW部署Stable Diffusion文生图Lora模型,来体验AIGC的魅力。
再开始实验之前,我们需要先开通交互式建模PAI-DSW 的服务,趁着阿里云推出的免费试用的机会,赶快来体验吧,试用中心地址:阿里云免费试用 找到机器学习平台PAI的类别,点击【立即试用】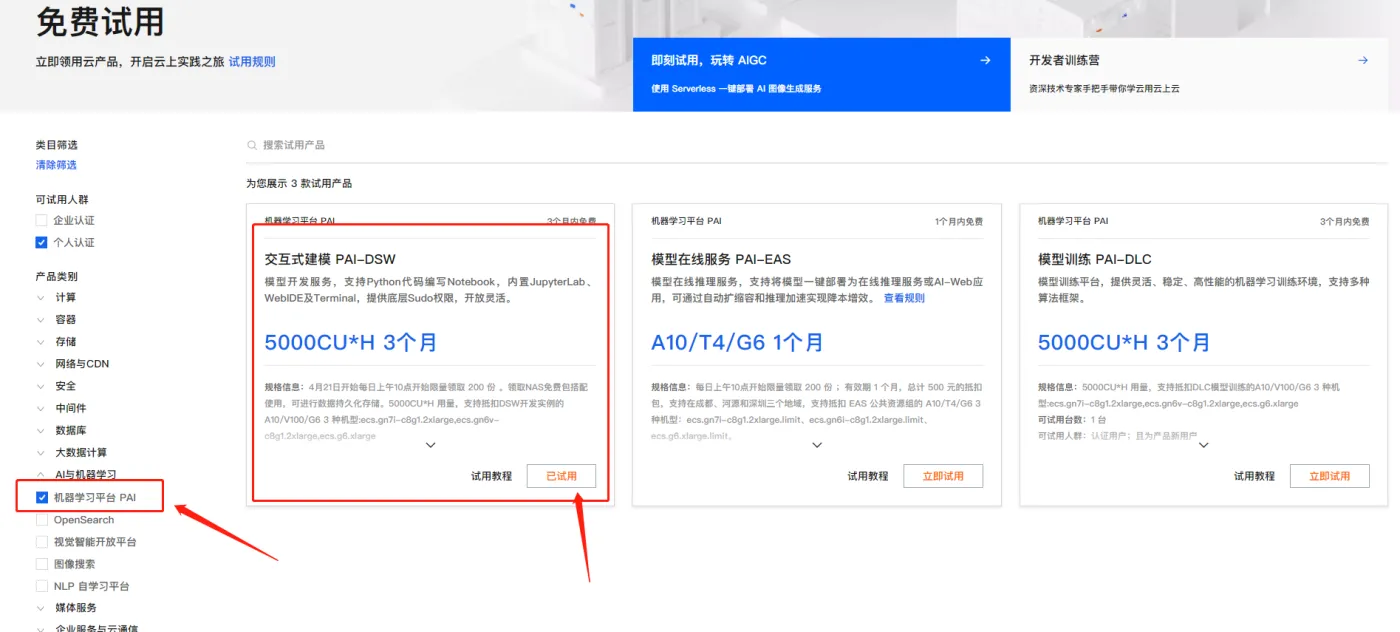
如果没有试用资格,那么你可以直接进行后面的操作。
开通交互式建模PAI-DSW服务之后,需要创建默认工作空间,
创建默认工作空间,官方文档地址:开通并创建默认工作空间,比如选择地域杭州
点击【开通PAI并创建默认工作空间】,完成授权及勾选操作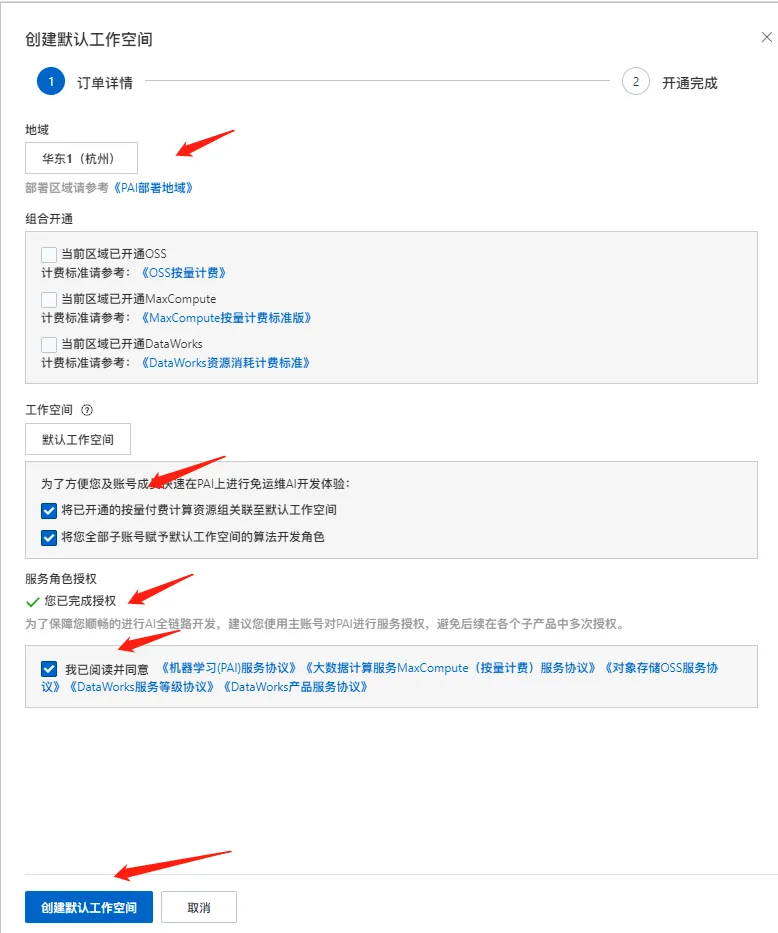
点击【确认开通并创建默认工作空间】完成默认工作空间的创建。
回到PAI控制台首页,可以在工作空间列表中看到我们刚才创建的默认工作空间信息,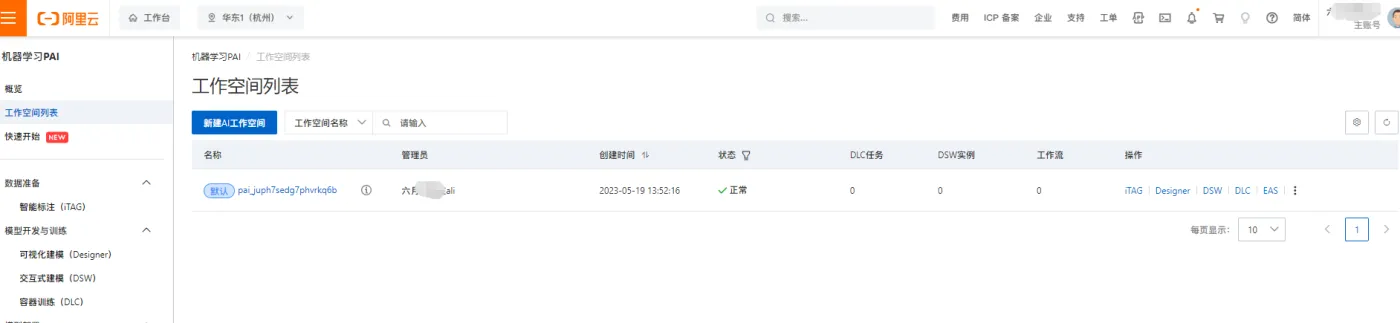
在控制台选择菜单【交互式建模(DSW)】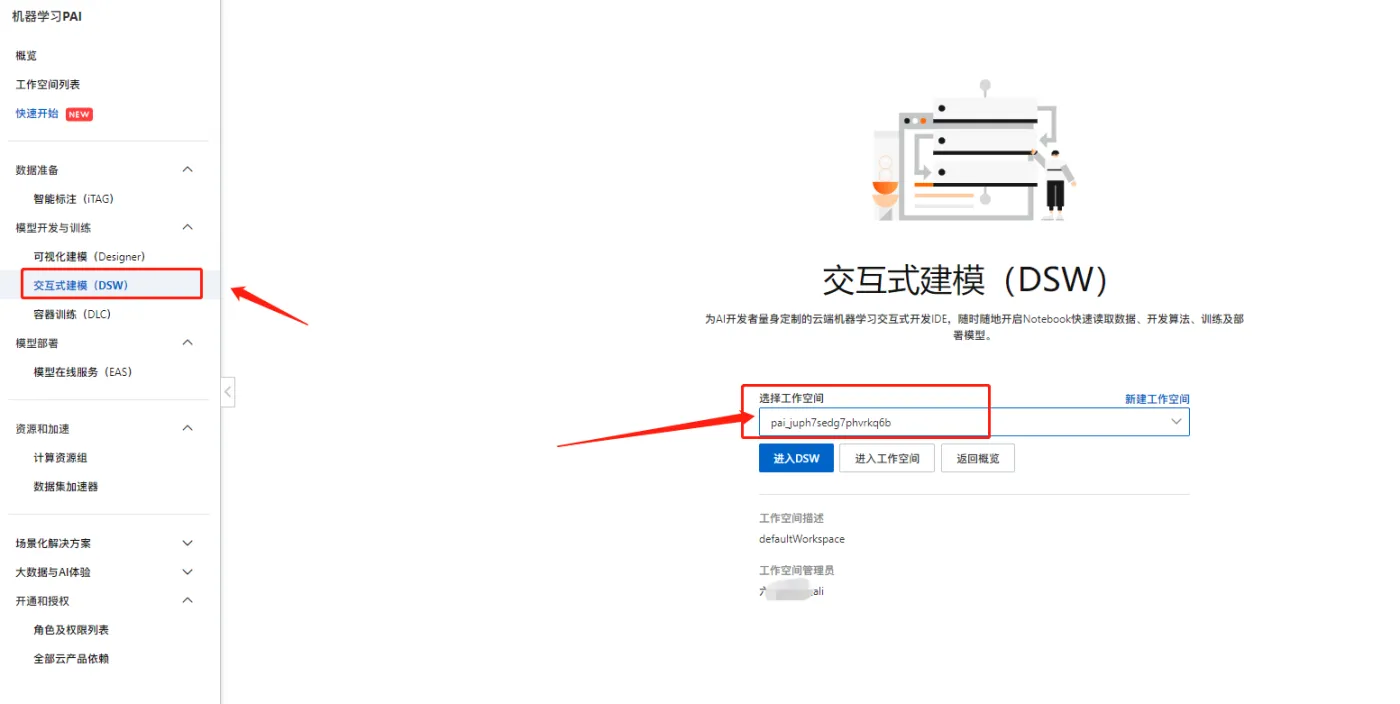
这里会默认选中我们刚才创建的工作空间,点击【进入DSW】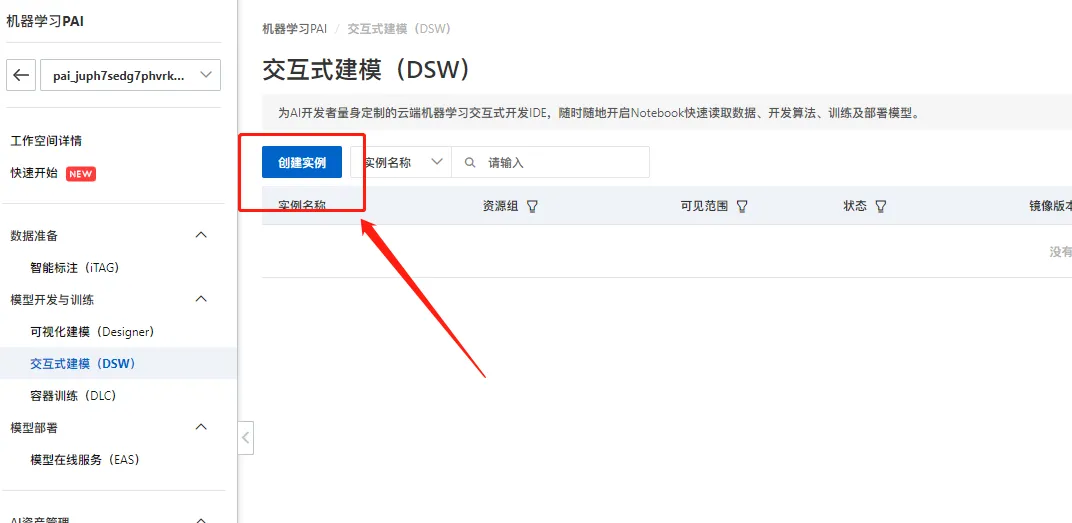
点击【创建实例】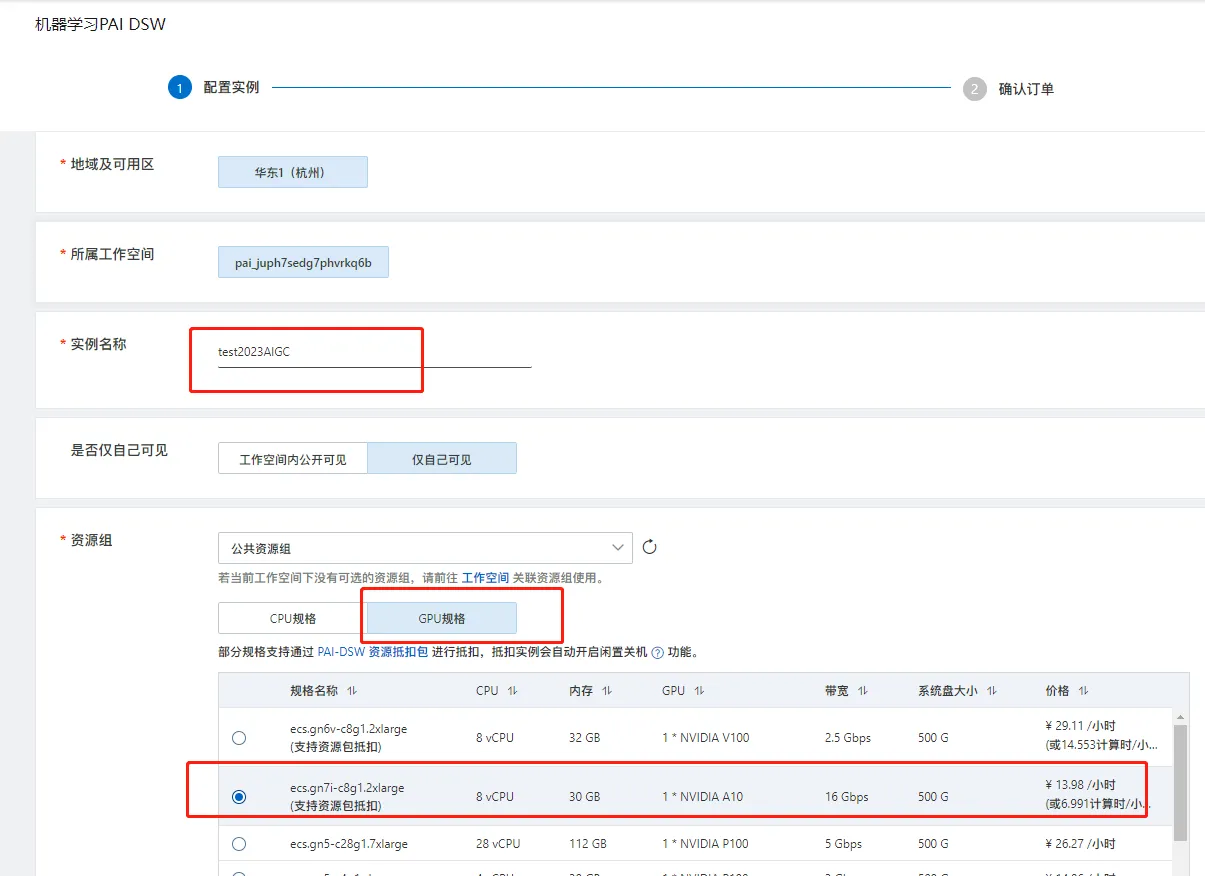
输入实例名称,点击tab 【GPU规格】,选择规格【ecs.gn7i-c8g1.2xlarge】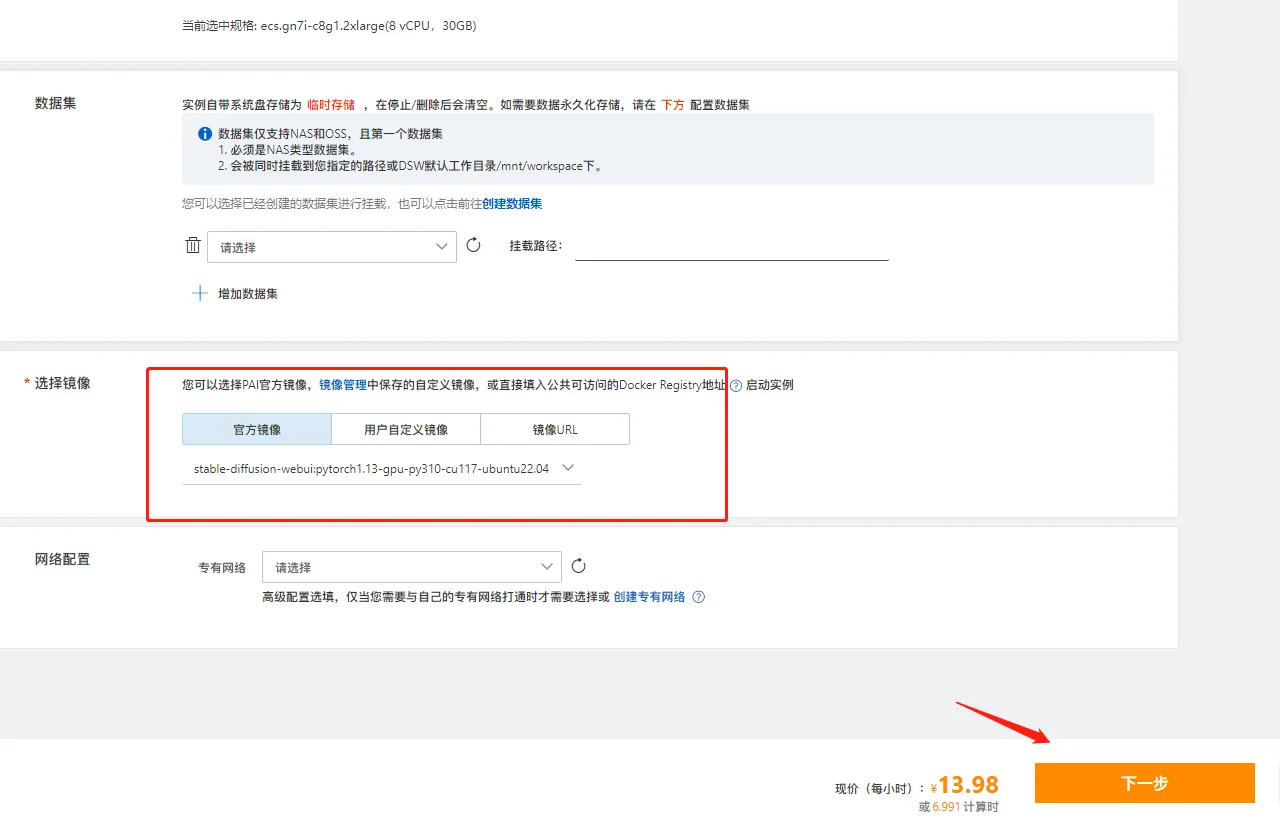
继续选择镜像【stable-diffusion-webui-env:pytorch1.13-gpu-py310-cu117-ubuntu22.04】点击【下一步】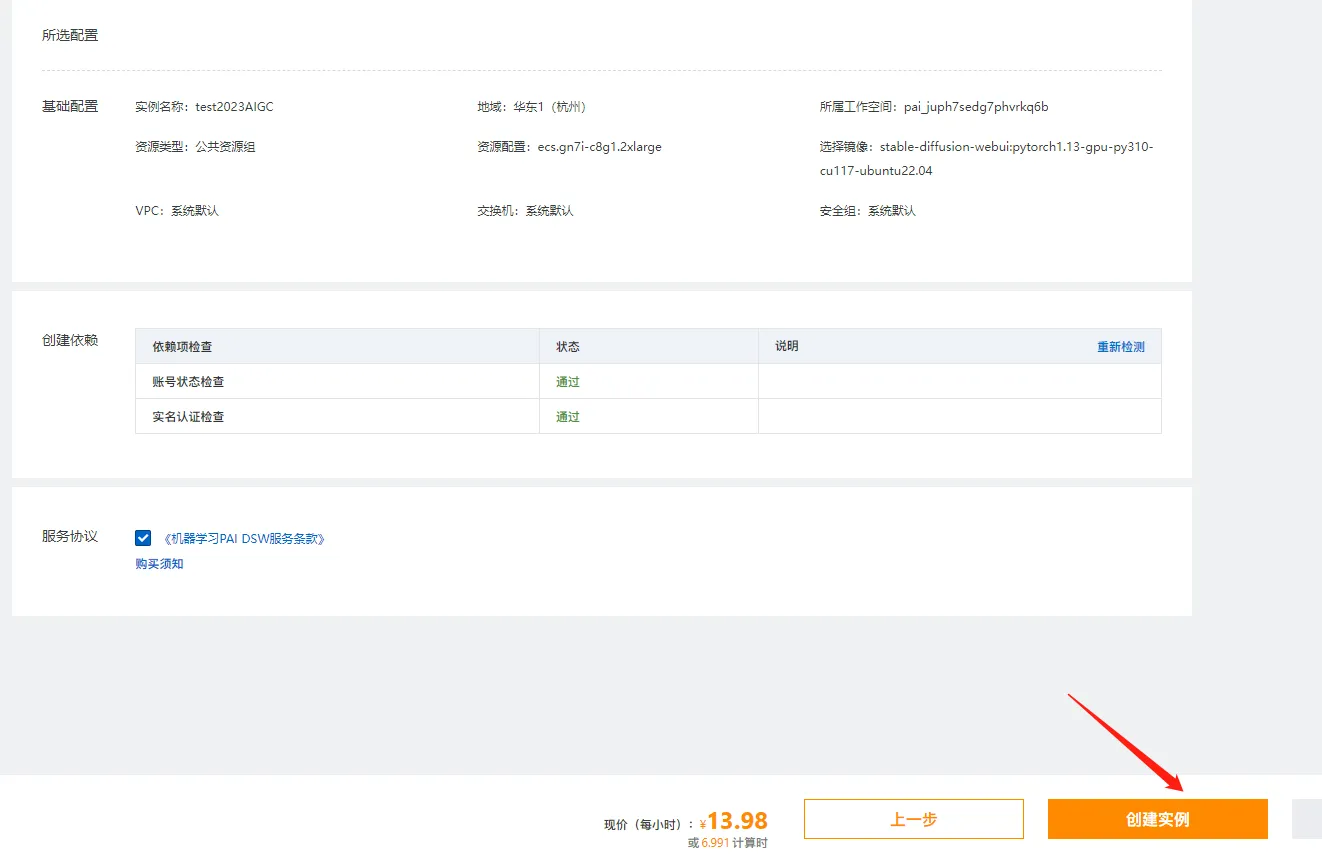
确认完信息之后点击【创建实例】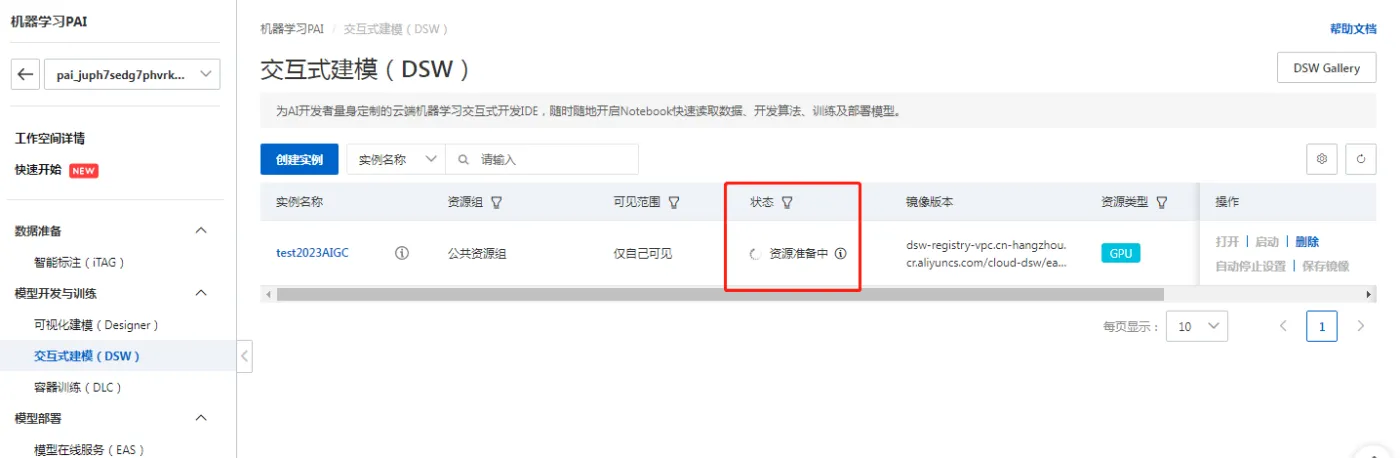
等待实例资源准备后启动成功。
下载Diffusers开源库并安装,为后续下载stable-diffusion-webui开源库做准备。
点击【打开】
打开在线编辑工具Notebook,选择【Python3】如图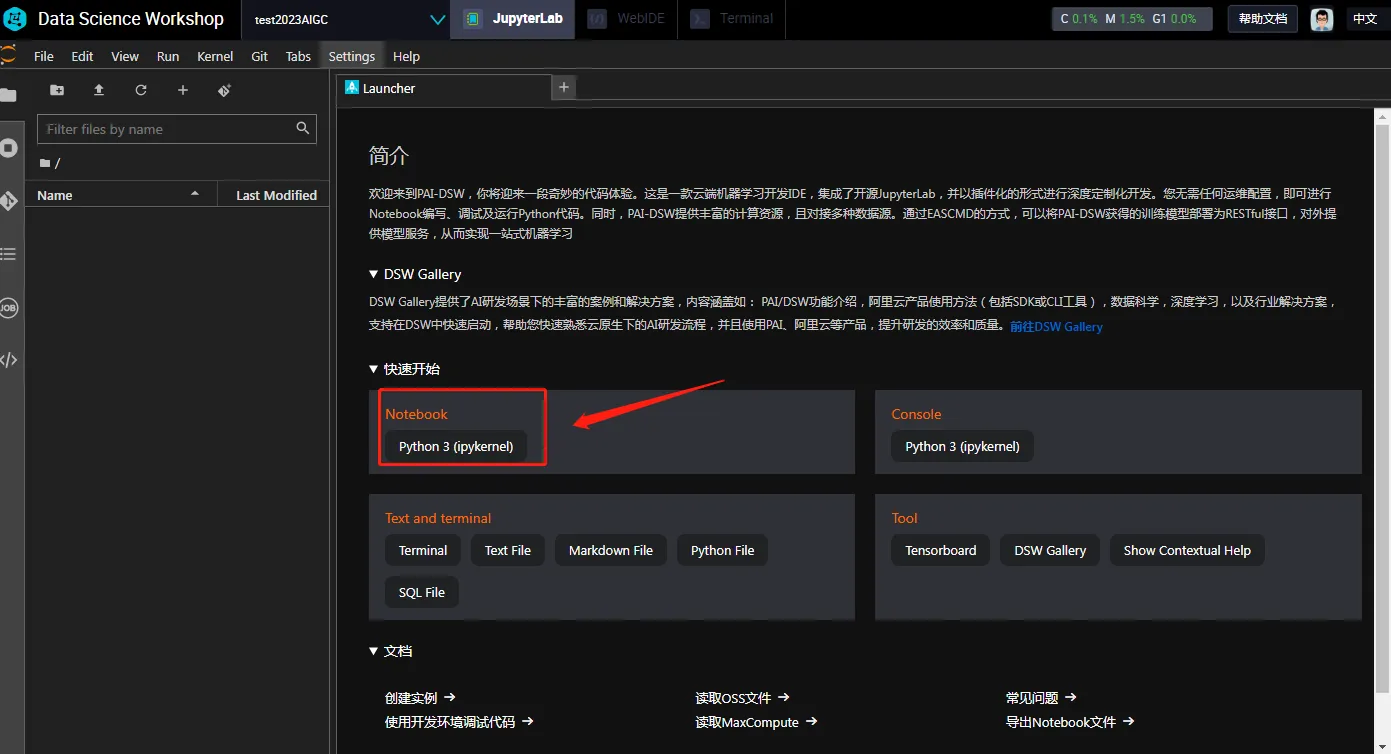
输入命令下载Diffusers开源库
! git clone https://github.com/huggingface/diffusers
下载开源库过程中,如果遇到超时的情况可以再次执行下载即可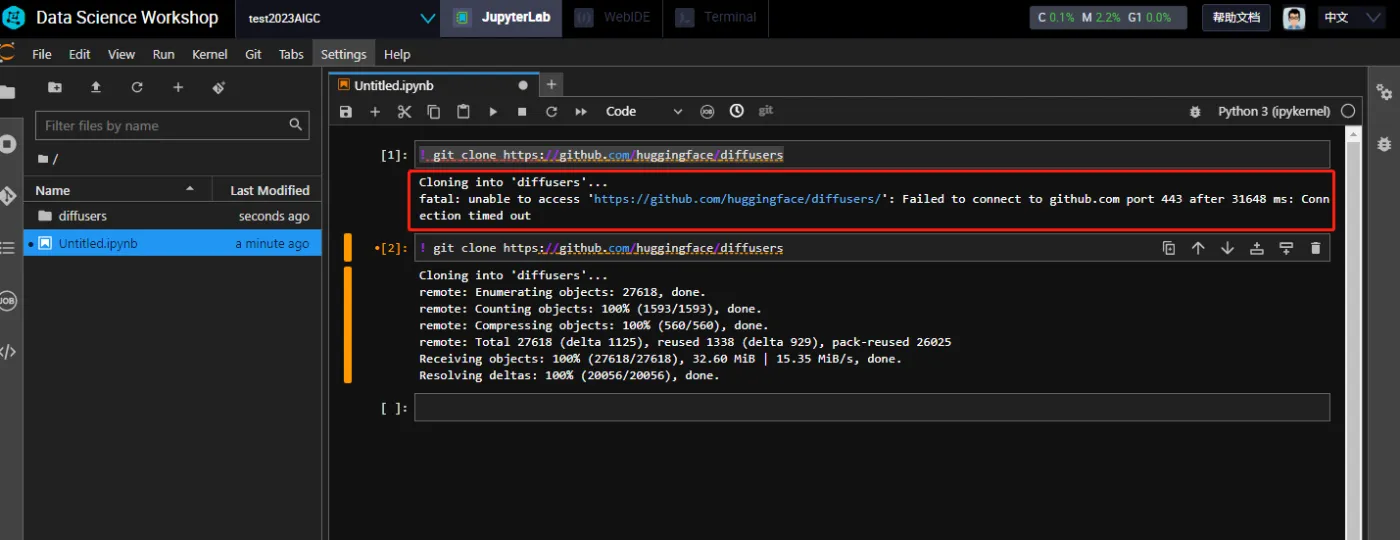
验证一下是否安装成功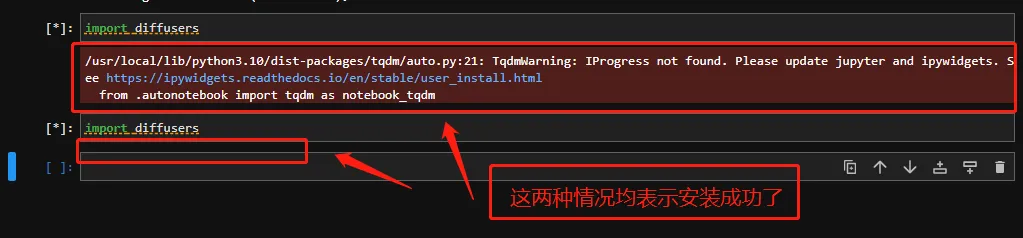
配置accelerate,选择Terminal输入配置命令,确认之后,通过键盘上下键选中This machine并确认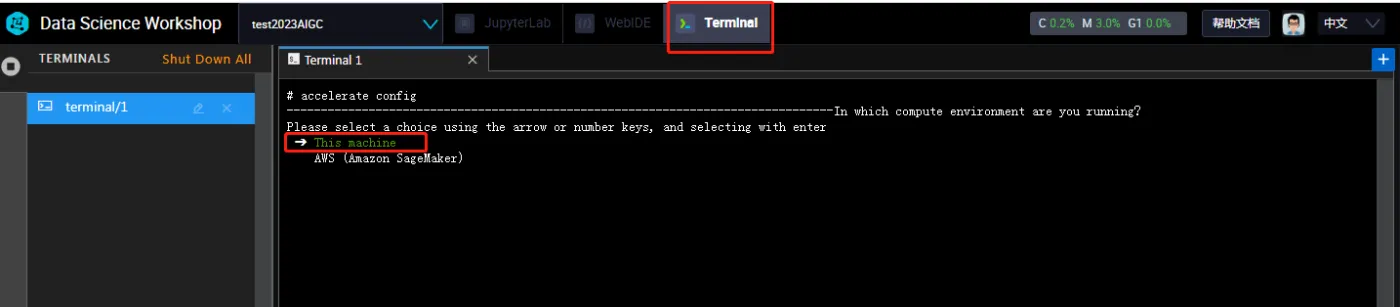
然后在选择multi-GPU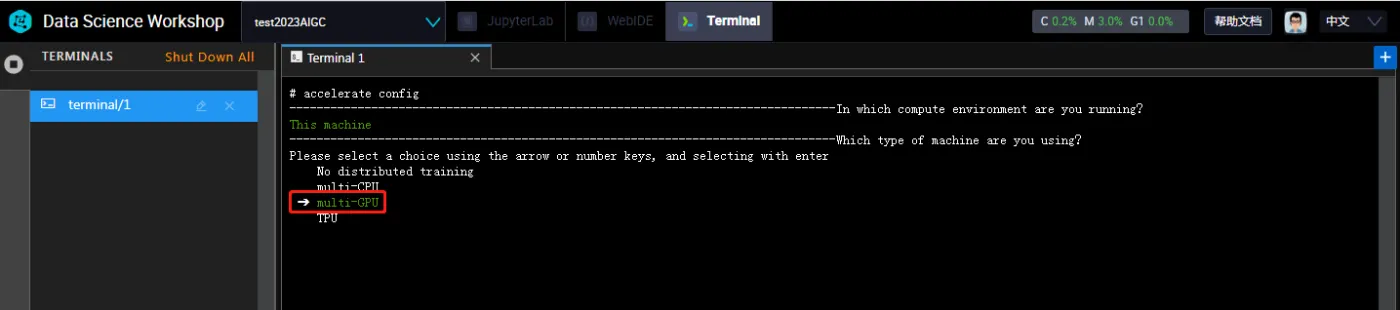
选中之后确认,后面的一次按截图的内容选择即可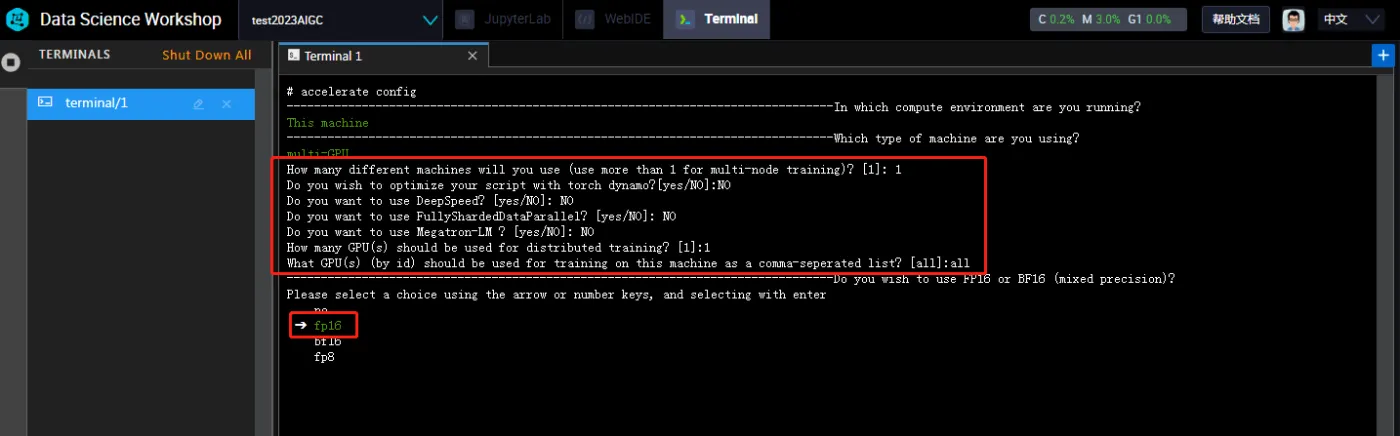
最后选中fp16 点击确认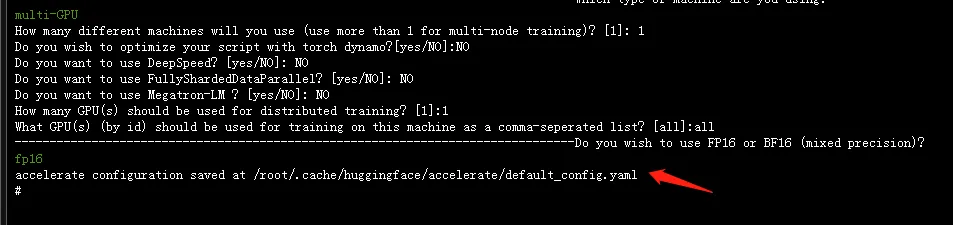
此时可以看到accelerate配置完成了。下面继续回到python3页面安装文生图算法相关依赖库
! cd diffusers/examples/text_to_image && pip install -r requirements.txt
下面开始下载stable-diffusion-webui开源库,执行命令
! git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git && \
cd stable-diffusion-webui && \
git checkout a9fed7c364061ae6efb37f797b6b522cb3cf7aa2
! cd stable-diffusion-webui && mkdir -p repositories && cd repositories && \
git clone https://github.com/sczhou/CodeFormer.git
下载过程中如果遇到这种情况,再次执行以下命令就可以了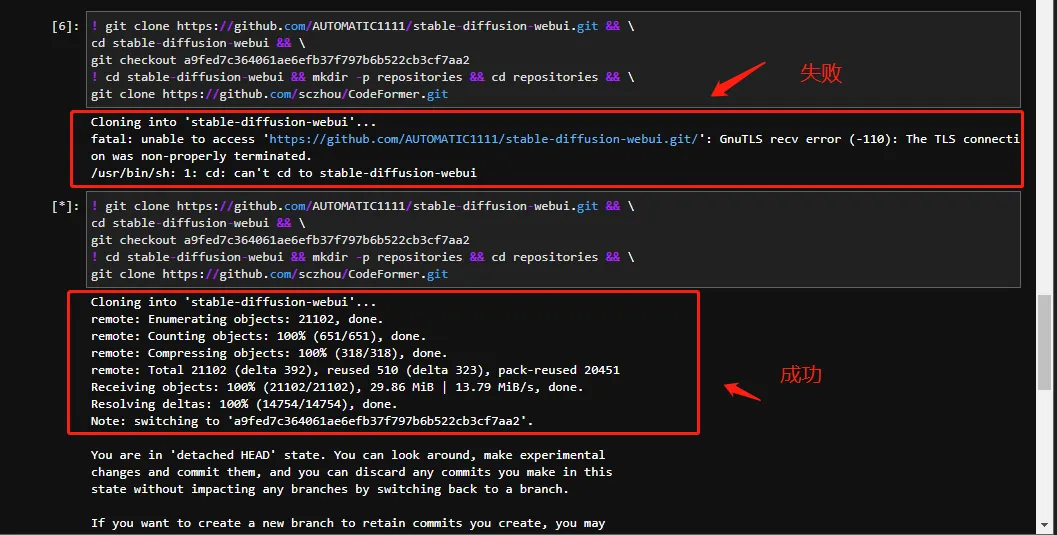
最后下载完成。继续下载示例数据集,后续会使用该数据集进行模型训练。执行如下命令
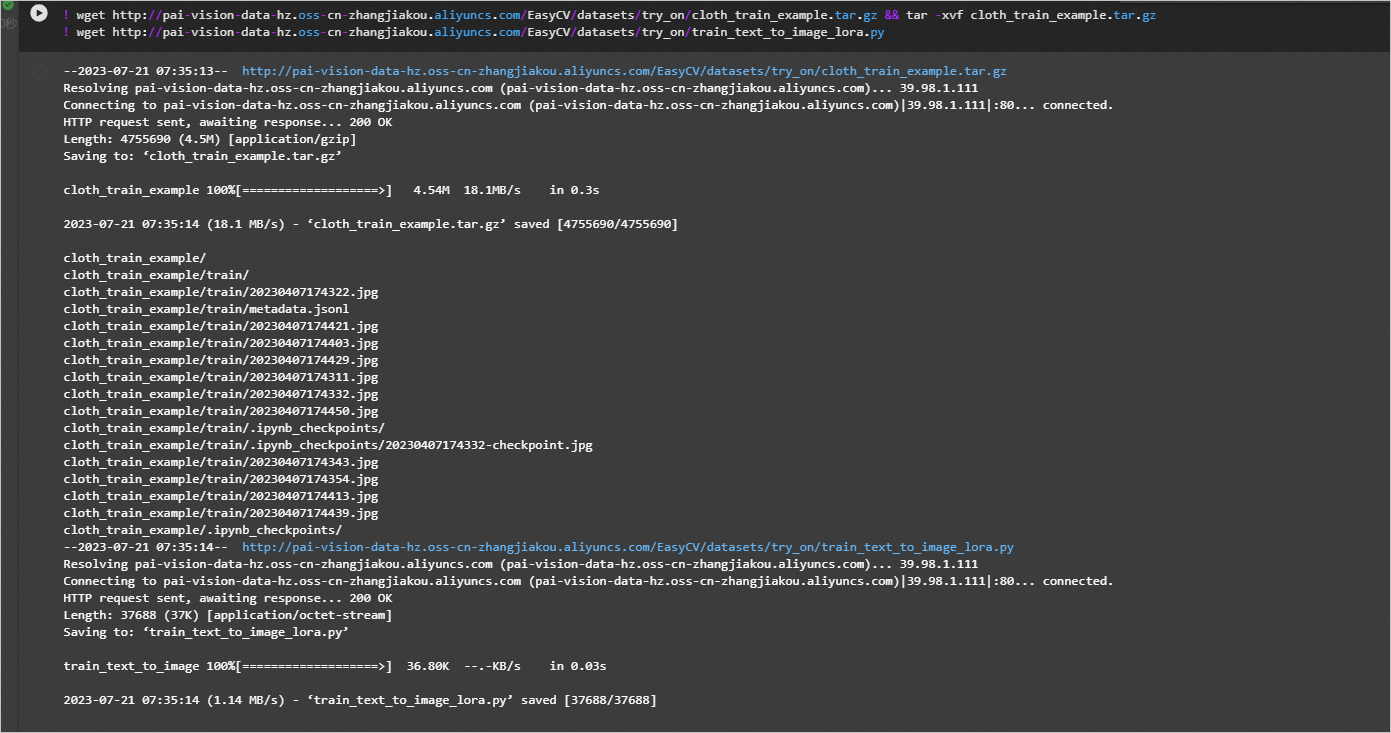
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/cloth_train_example.tar.gz && tar -xvf cloth_train_example.tar.gz
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/train_text_to_image_lora.py
数据集下载完成之后可以看到
查看一下示例服装,执行命令
from PIL import Image
display(Image.open("cloth_train_example/train/20230407174450.jpg"))
执行结果可以看到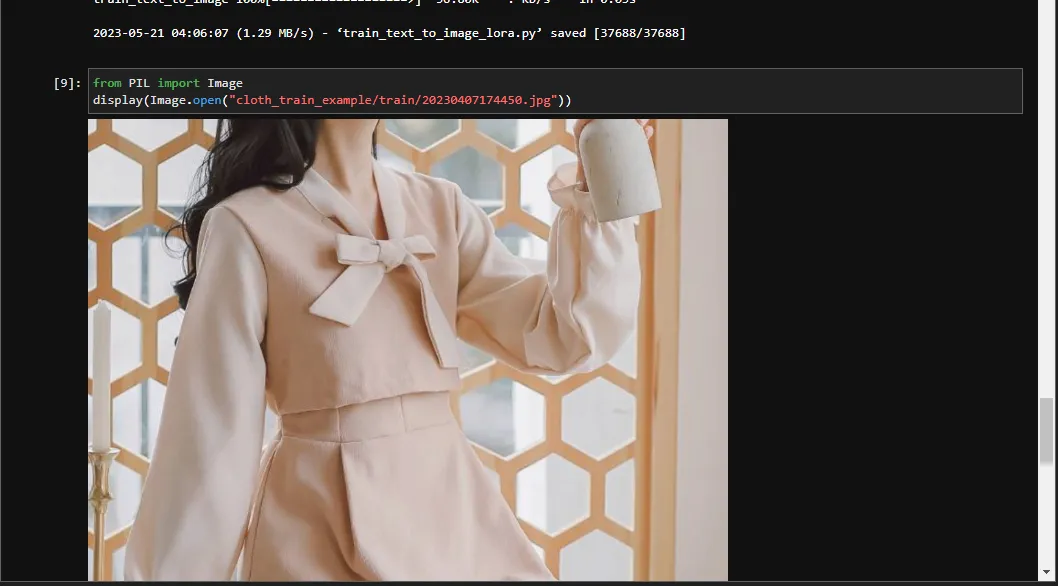
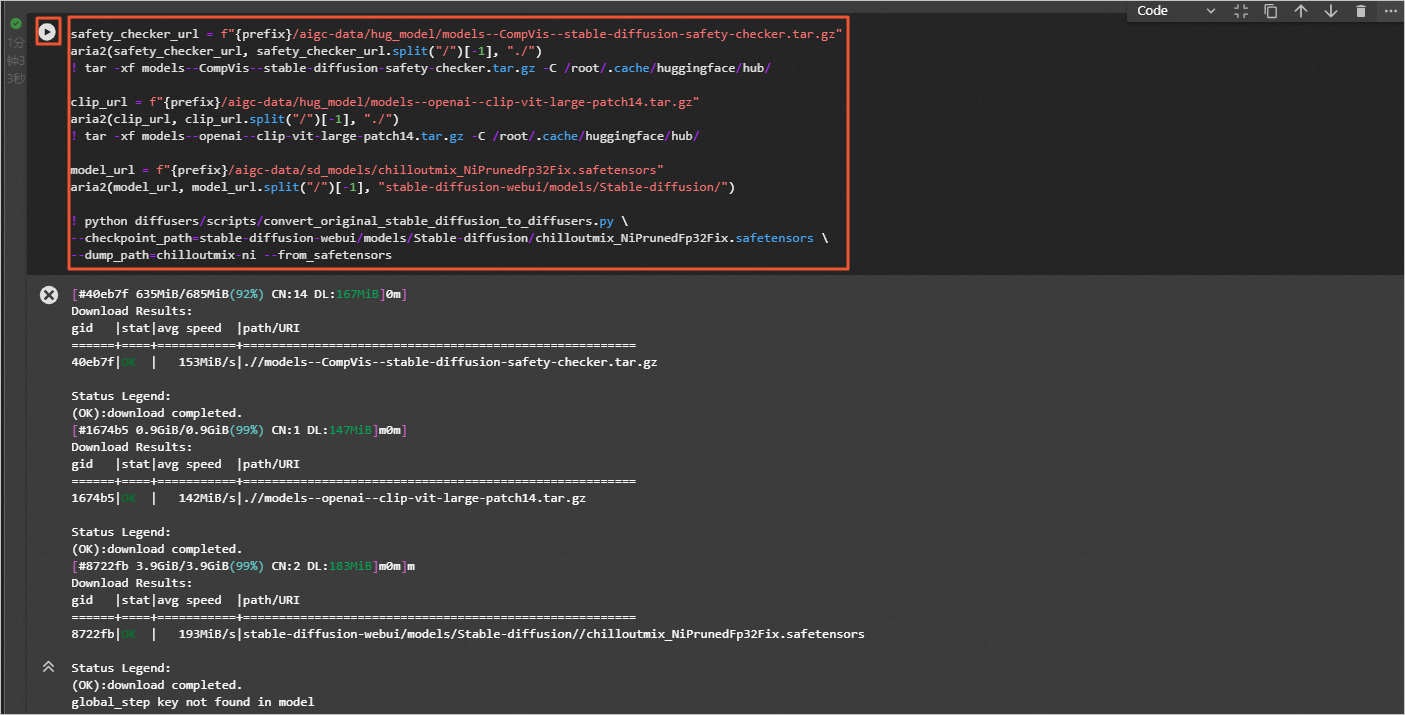
继续下载预训练模型并转化成diffusers格式,执行命令
! cd stable-diffusion-webui/models/Stable-diffusion && wget -c https://huggingface.co/naonovn/chilloutmix_NiPrunedFp32Fix/resolve/main/chilloutmix_NiPrunedFp32Fix.safetensors -O chilloutmix_NiPrunedFp32Fix.safetensors
! python diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py \
--checkpoint_path=stable-diffusion-webui/models/Stable-diffusion/chilloutmix_NiPrunedFp32Fix.safetensors \
--dump_path=chilloutmix-ni --from_safetensors
执行结果如图
执行命令,设置num_train_epochs为200,进行lora模型的训练
! export MODEL_NAME="chilloutmix-ni" && \
export DATASET_NAME="cloth_train_example" && \
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--width=640 --height=768 --random_flip \
--train_batch_size=1 \
--num_train_epochs=200 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="cloth-model-lora" \
--validation_prompt="cloth1" --validation_epochs=100
训练完成之后可以看到
然后将lora模型转化成WebUI支持格式并拷贝到WebUI所在目录
! wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/convert-to-safetensors.py
! python convert-to-safetensors.py --file='cloth-model-lora/pytorch_lora_weights.bin'
! mkdir stable-diffusion-webui/models/Lora
! cp cloth-model-lora/pytorch_lora_weights_converted.safetensors stable-diffusion-webui/models/Lora/cloth_lora_weights.safetensors
执行结果如图
准备其他模型文件
! mkdir stable-diffusion-webui/models/Codeformer
! cd stable-diffusion-webui/repositories/CodeFormer/weights/facelib/ && \
wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/detection_Resnet50_Final.pth && \
wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/parsing_parsenet.pth
! cd stable-diffusion-webui/models/Codeformer && wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/codeformer-v0.1.0.pth
! cd stable-diffusion-webui/embeddings && wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/ng_deepnegative_v1_75t.pt
! cd stable-diffusion-webui/models/Lora && wget -c https://huggingface.co/Kanbara/doll-likeness-series/resolve/main/koreanDollLikeness_v10.safetensors
执行结果如图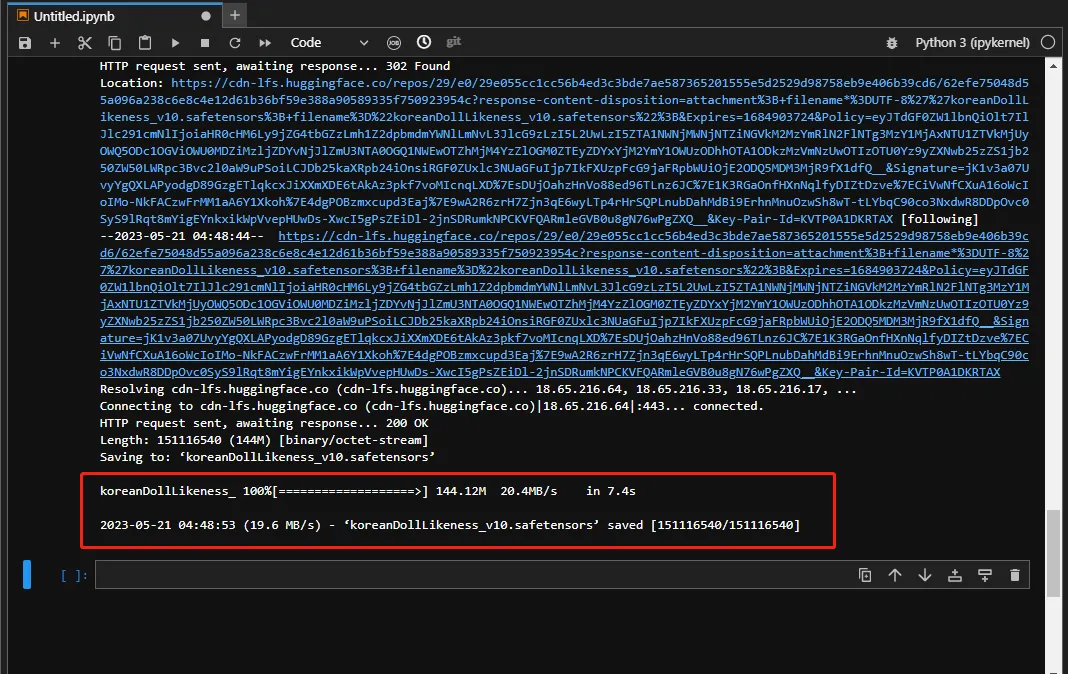
在Notebook中,执行如下命令,启动WebUI
! cd stable-diffusion-webui && python -m venv --system-site-packages --symlinks venv
! cd stable-diffusion-webui && \
sed -i 's/can_run_as_root=0/can_run_as_root=1/g' webui.sh && \
./webui.sh --no-download-sd-model --xformers
这个命令执行过程中可能会遇到多种情况的错误,每次遇到错误情况时重新执行命令即可,错误情况比如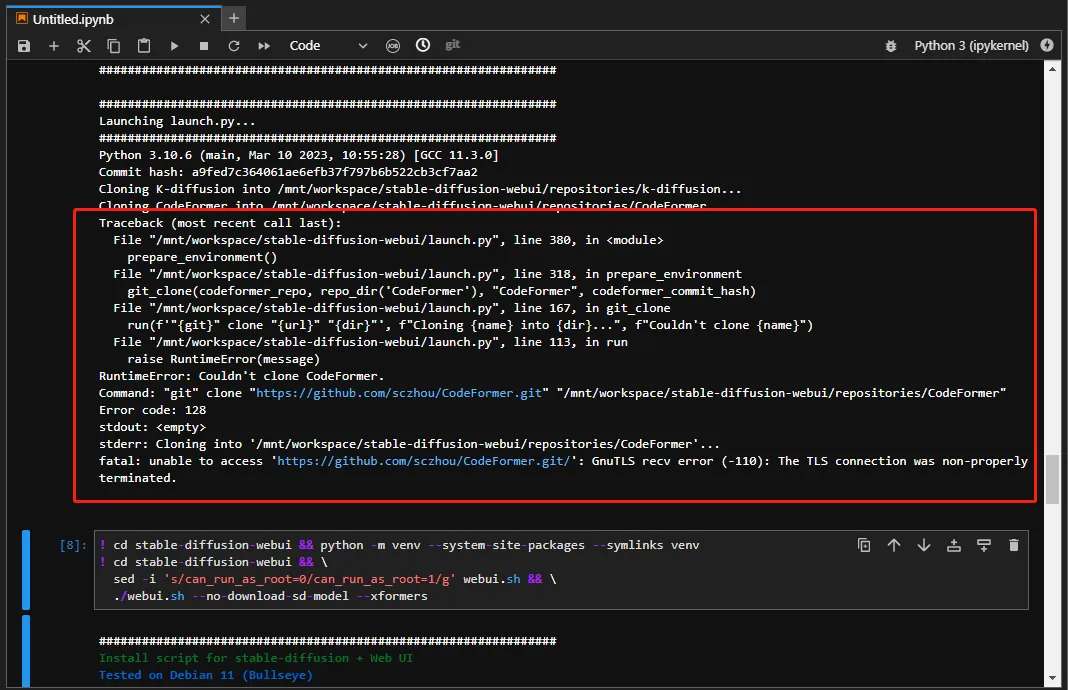
或者是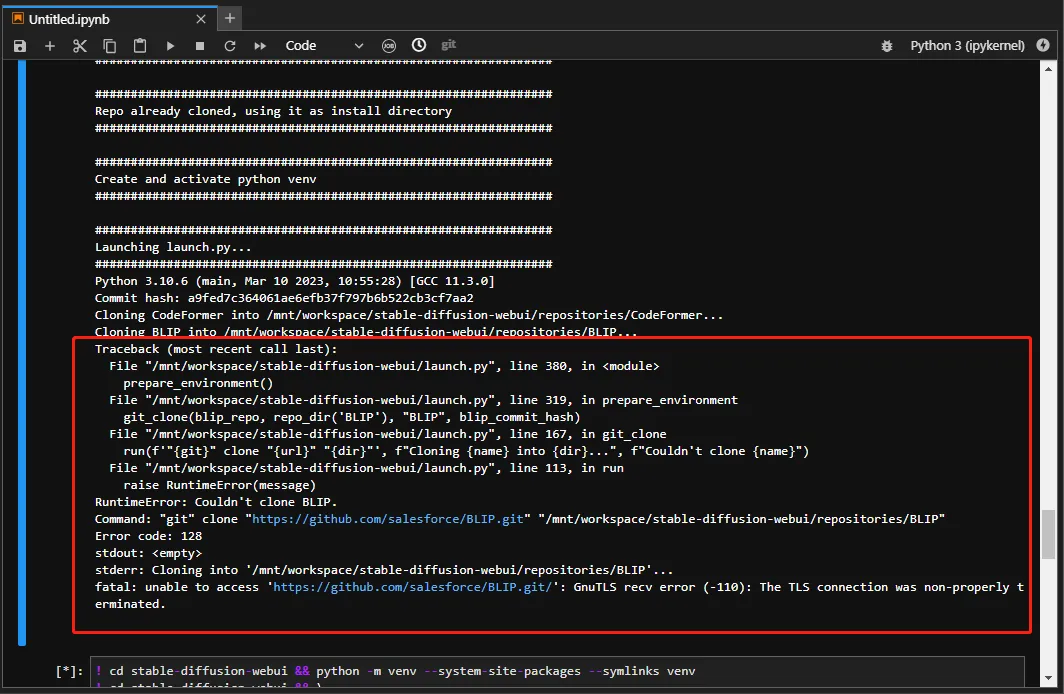
最后执行成功的界面如下
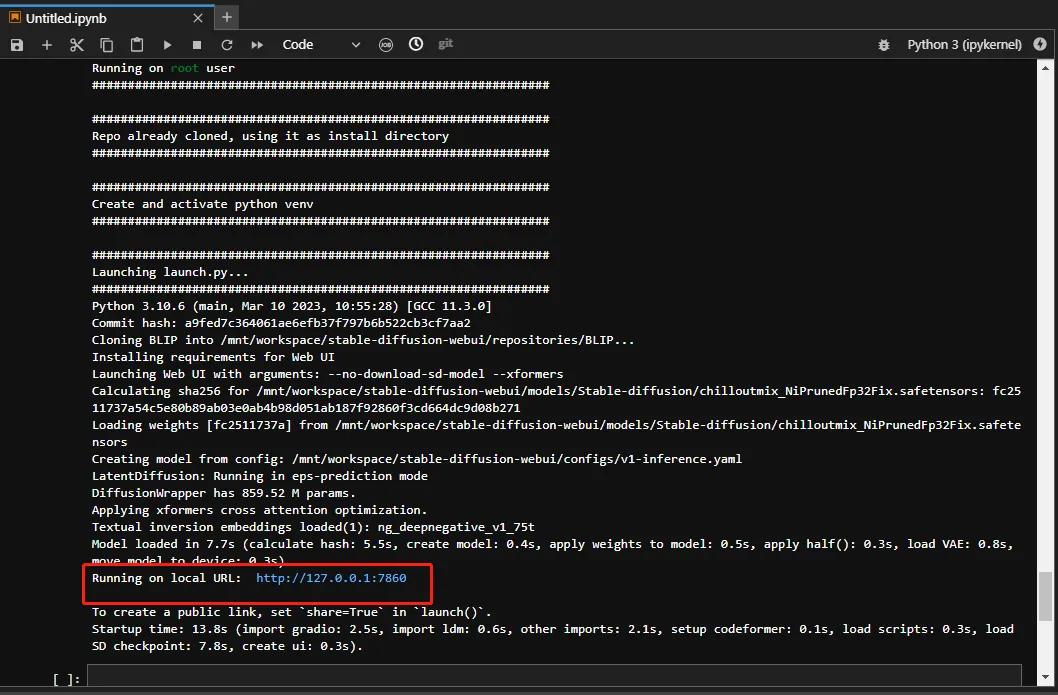
启动成功之后单机链接地址进入模型训练页面,输入待生成模型文本等待生成结果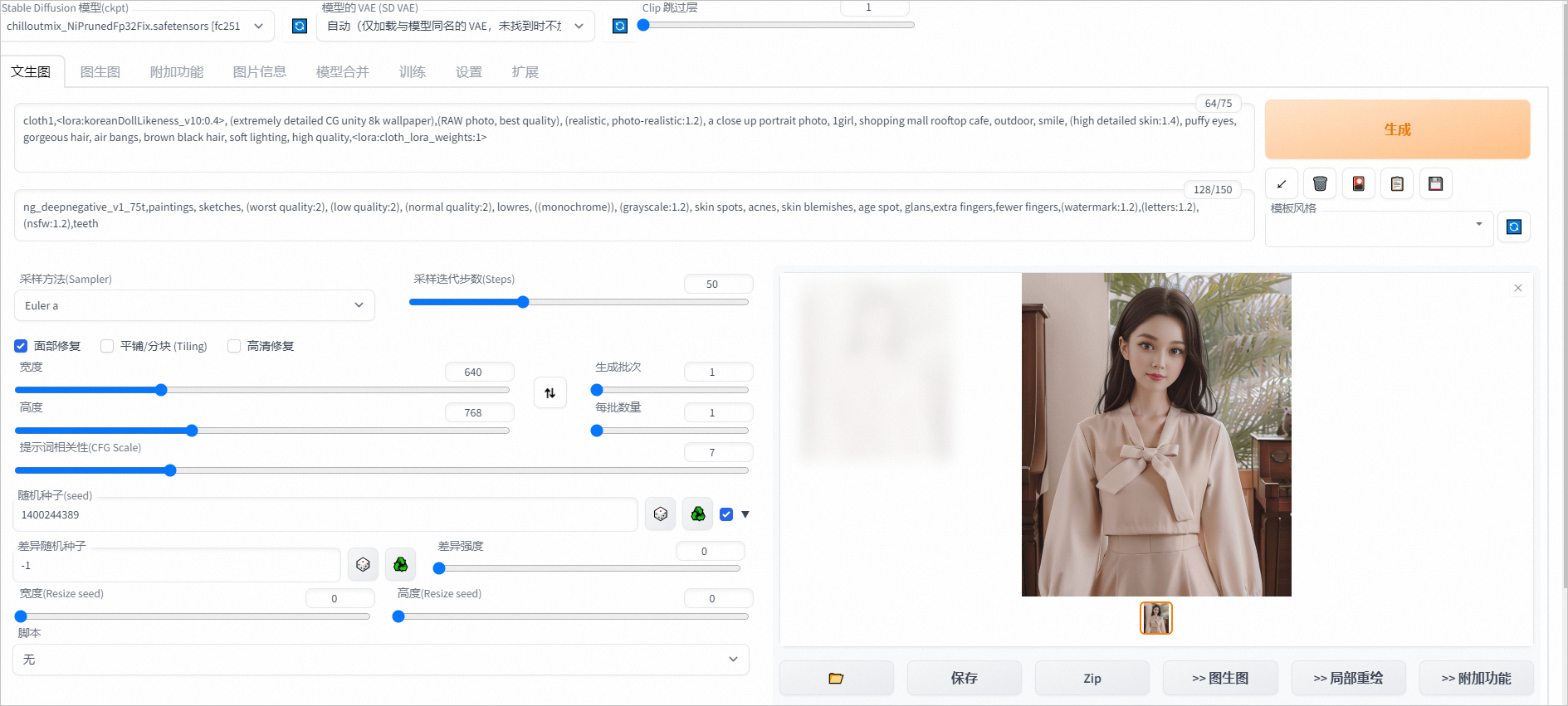
整体来说,本次操作的时间会耗时比较久,两个多小时左右,在部署过程中可能会遇到各种不成功的情况,不用担心,再次执行命令即可。
另外,对于AIGC文生图的操作,对于生成图像与文字描述是否匹配,这个主要还是取决于你当前使用的文生图模型的训练程度,模型训练的结果直接决定了AIGC文生图的准确度,由此及彼的来看,对于AIGC文生图、图生文、文生视频、文生音频等的操作,随着模型训练的不断丰富话,后续想要生成更加准确的切合文字内容的图片及视频都是很有可能的。
本次体验使用到阿里云交互式建模(PAI-DSW),如果你是新用户,则可以先领取产品试用。点击前往,领取试用。如下: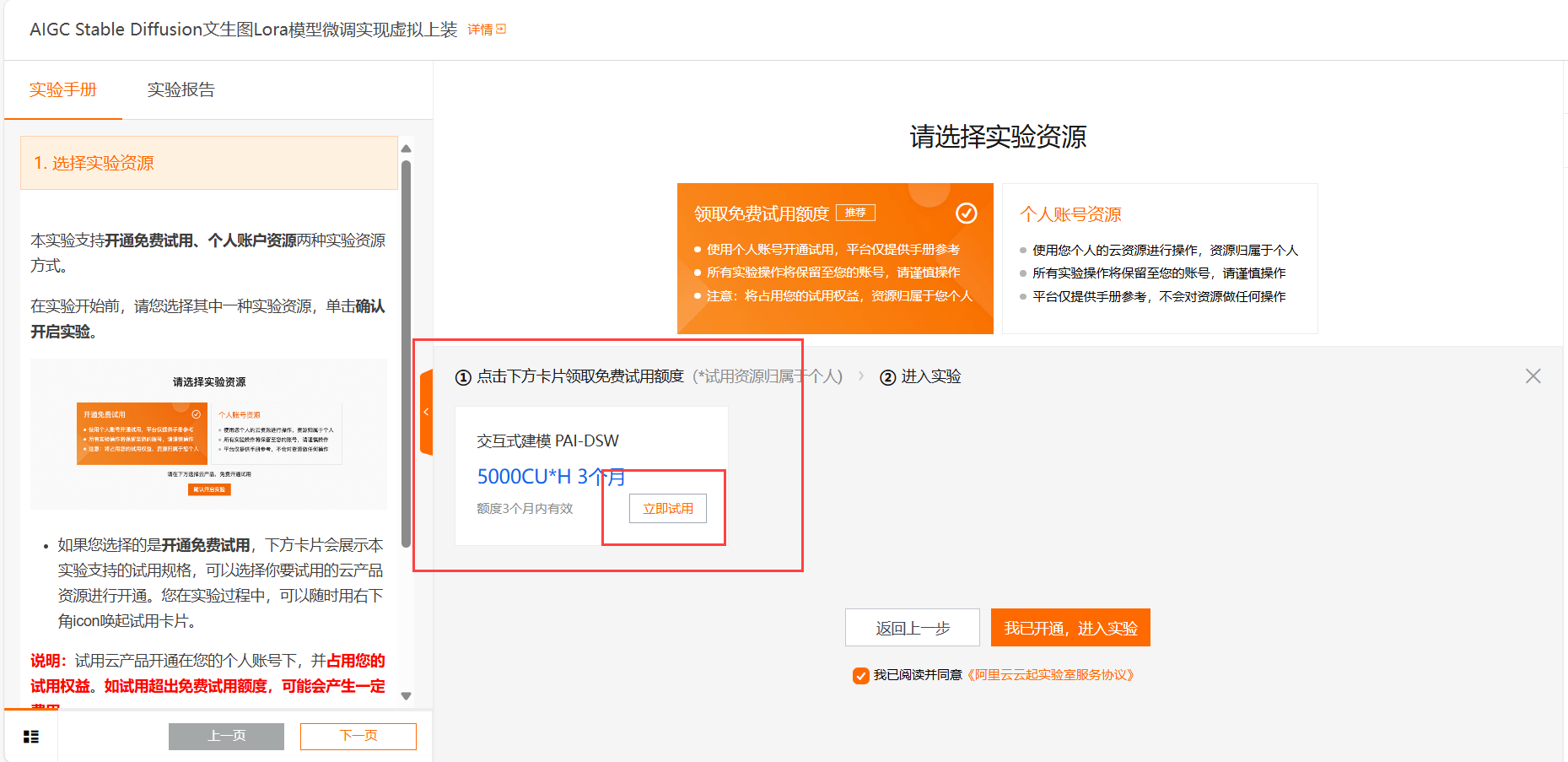
领取试用时认真阅读试用说明,确认后点击立即试用。如下: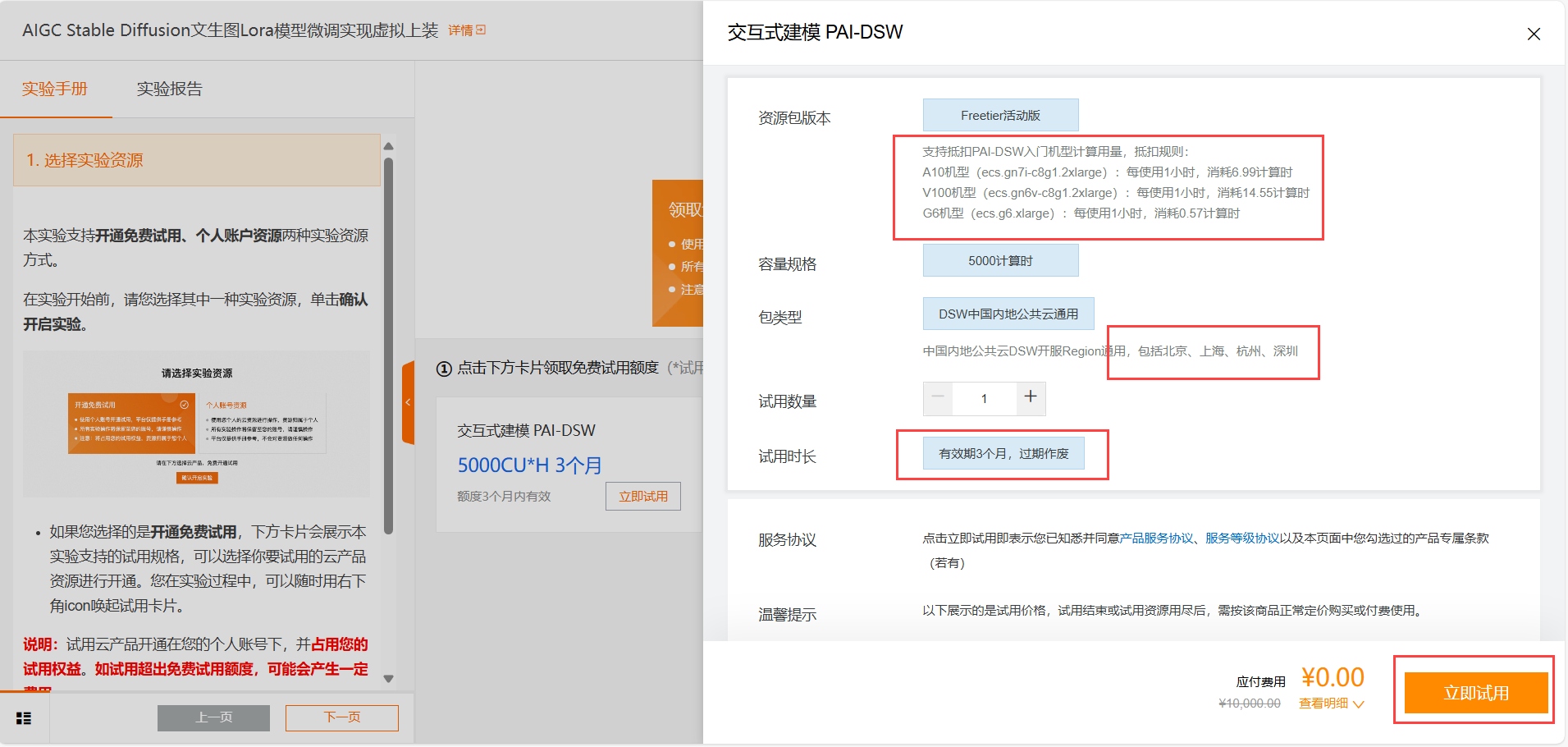
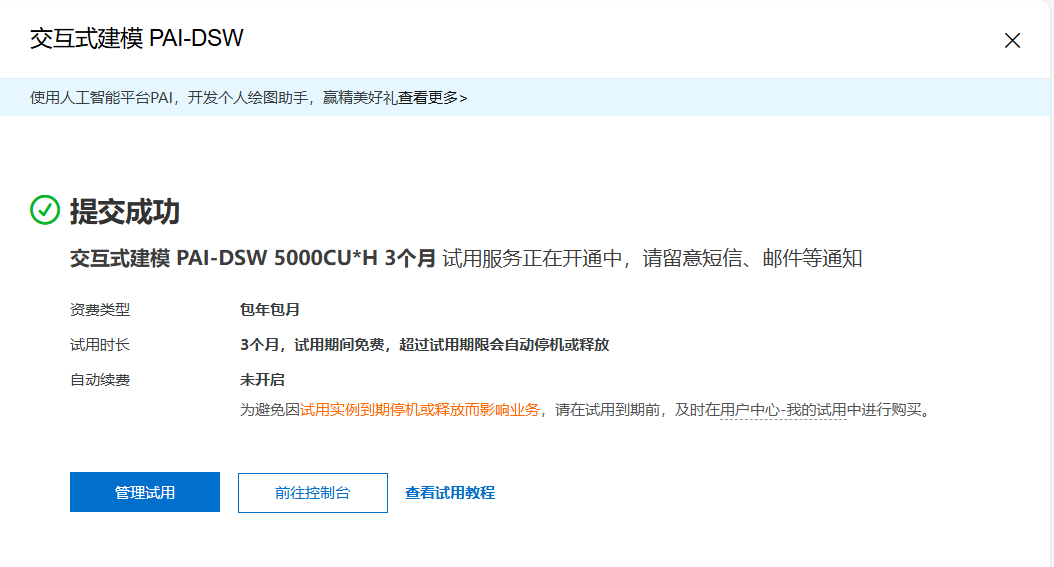
领取试用后,可在我的账单中查看到具体的明细,如下: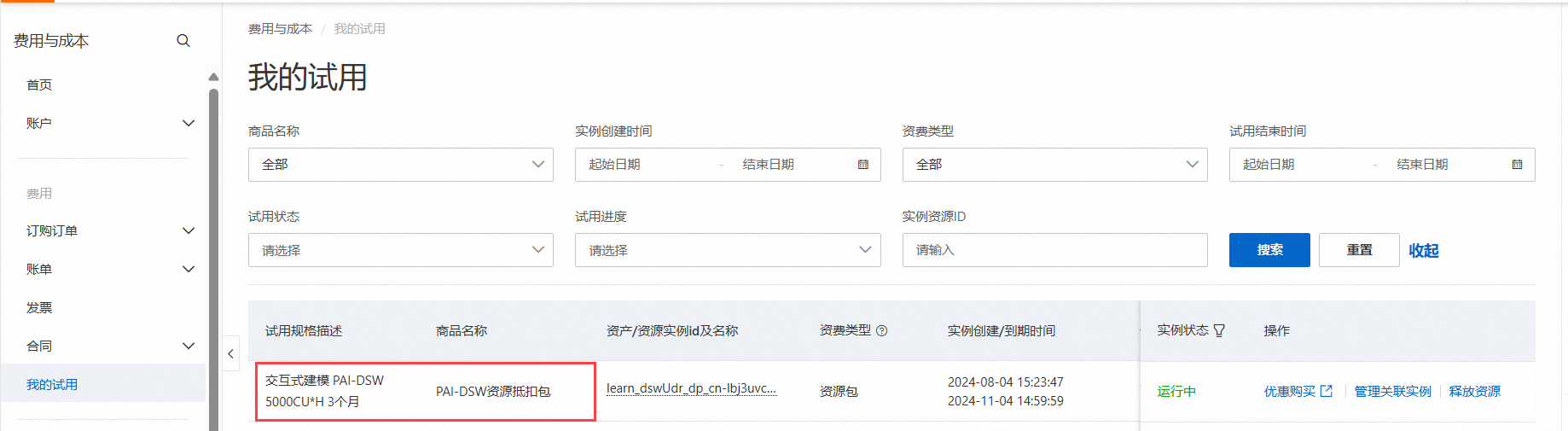
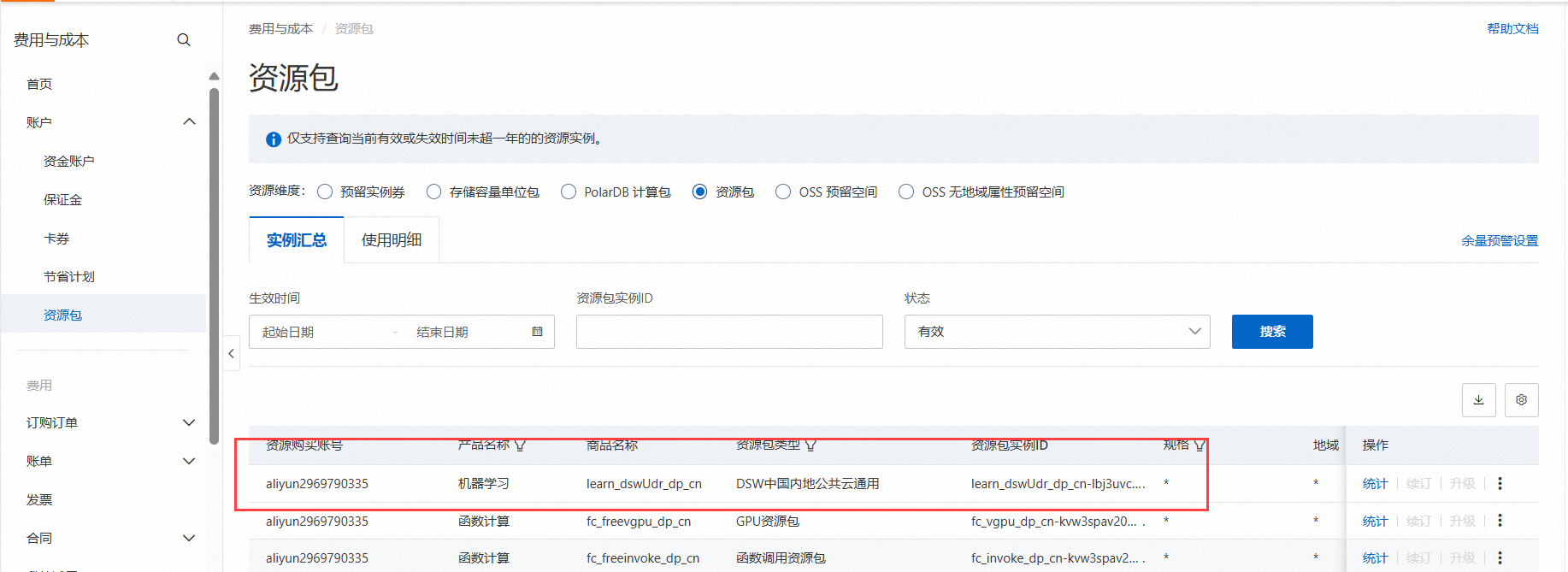
登录PAI控制台,如果你是首次使用PAI,会需要先开通个默认的工作空间。如下:
为了方便,这里地域就直接选择了杭州。如下:
由于本次体验不需要开通其他产品,所以组合服务这里取消默认的组合服务勾选,以免产生不必要的费用。首次开通需要授权,点击授权前往RAM访问控制。如下:
点击同意授权即可。如下:
完成授权后返回点击刷新,继续点击“确认开通并创建默认工作空间”。如下:
这里需要等待一小会,即可完成服务的开通。如下: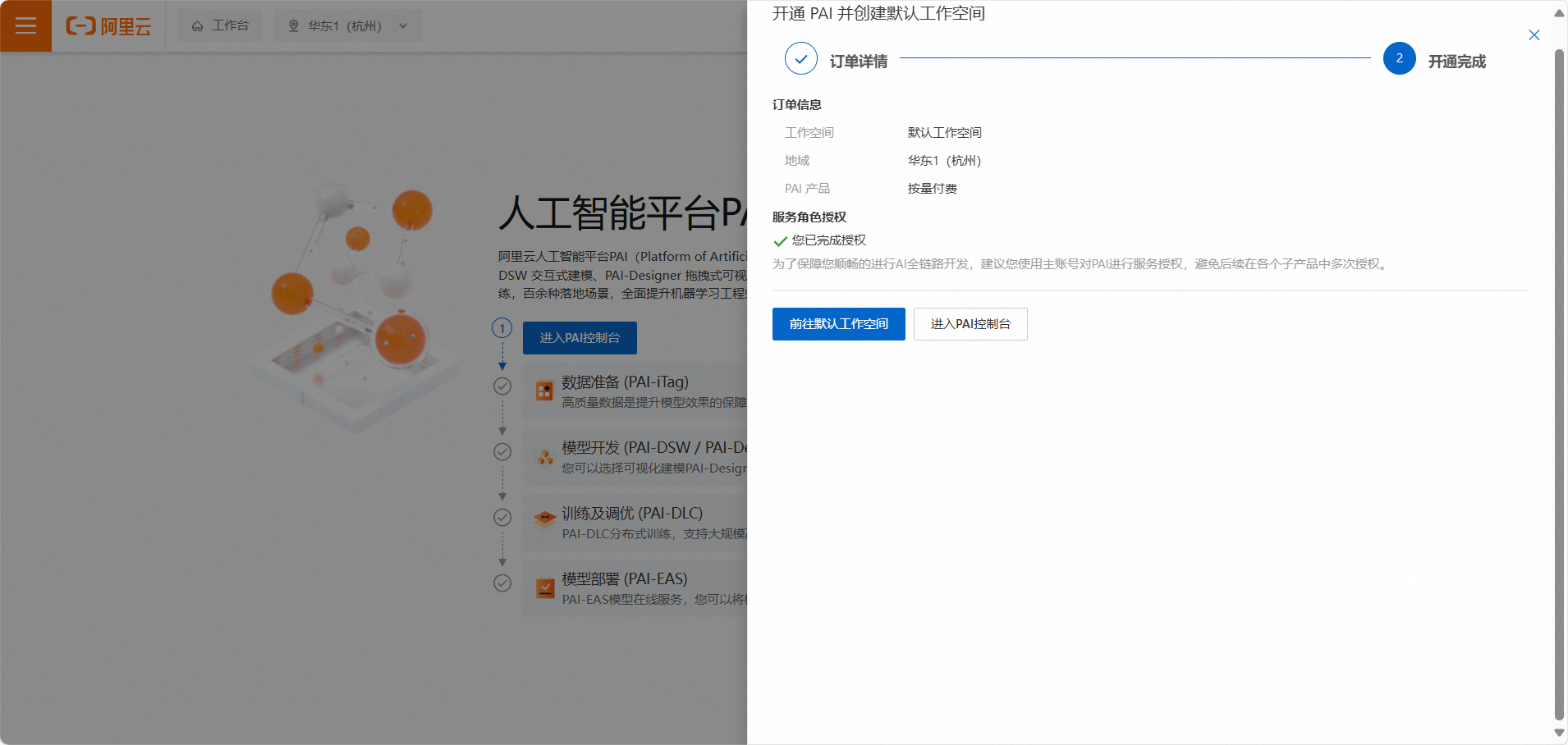
进入PAI控制台,在左侧导航栏中单击工作空间列表,选择交互式建模(DSW),点击新建实例。
配置参数
区域这里选择华东1(杭州)
实例名称为AIGC_test
资源规则选择GPU类别中的ecs.gn7i-c8g1.2xlarge (8 vCPU, 30 GiB, NVIDIA A10 * 1),这也是试用的规格之一,支持资源包抵扣的。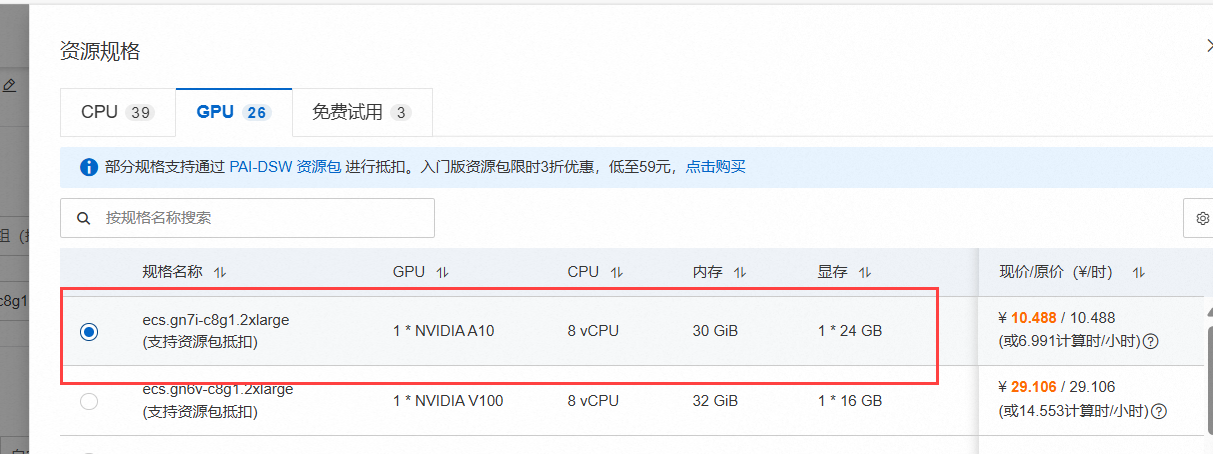
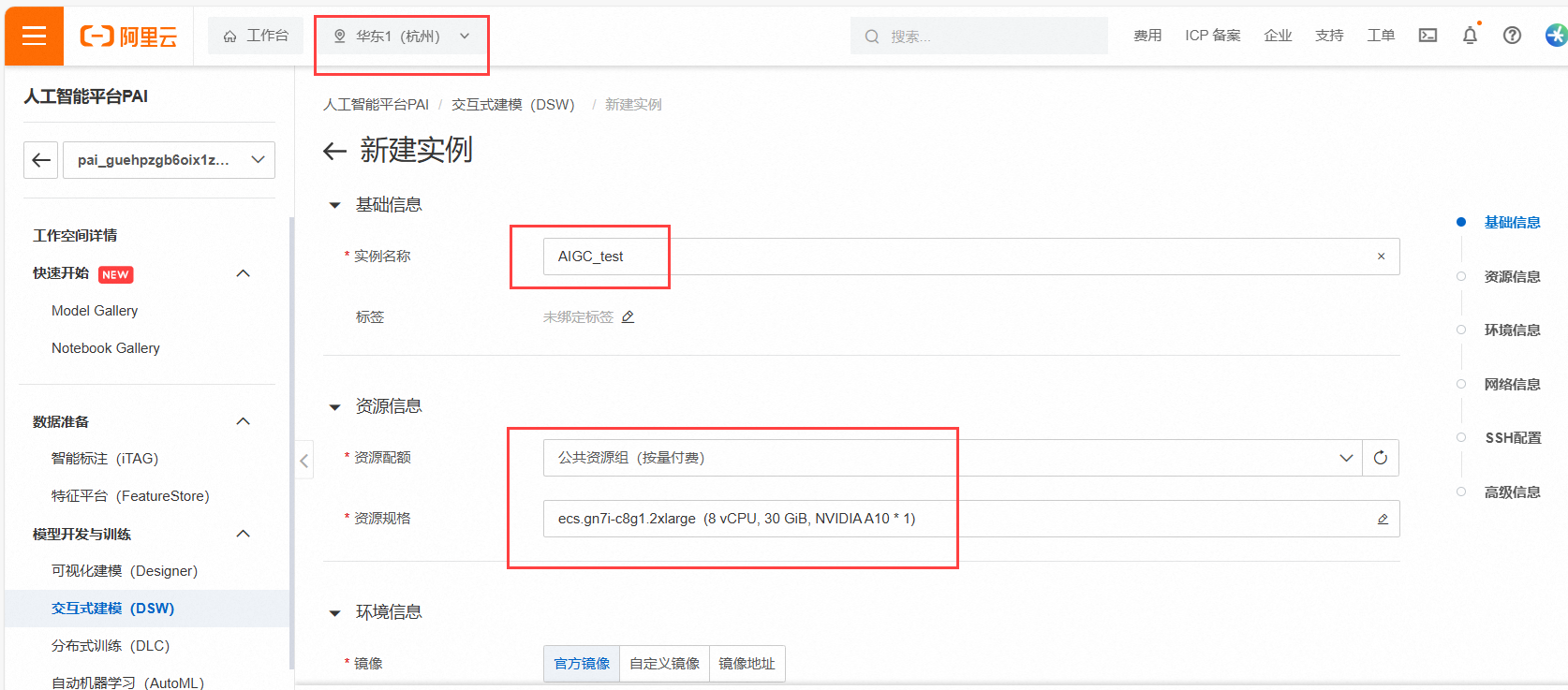
镜像这里我们选择stable-diffusion-webui-develop:1.0-pytorch1.13-gpu-py310-cu117-ubuntu22.04,专用于DSW实例环境的。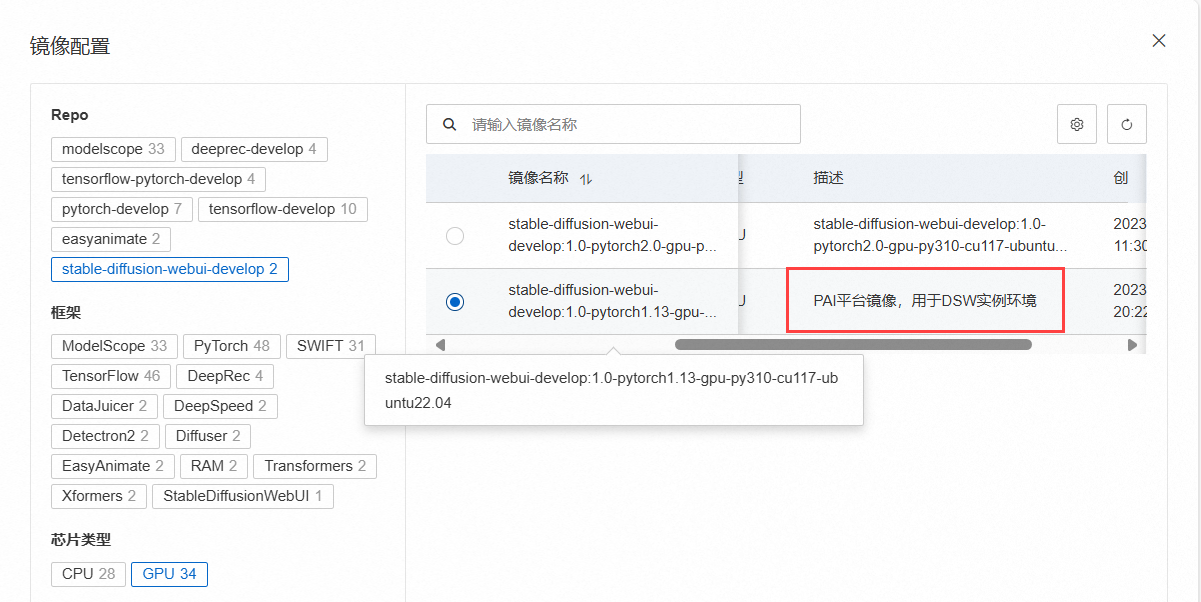
在点击确定开始创建时会遇到如下异常,是因为所在区域的可用资源不足导致的,需要更换到其他可用区域重新提交。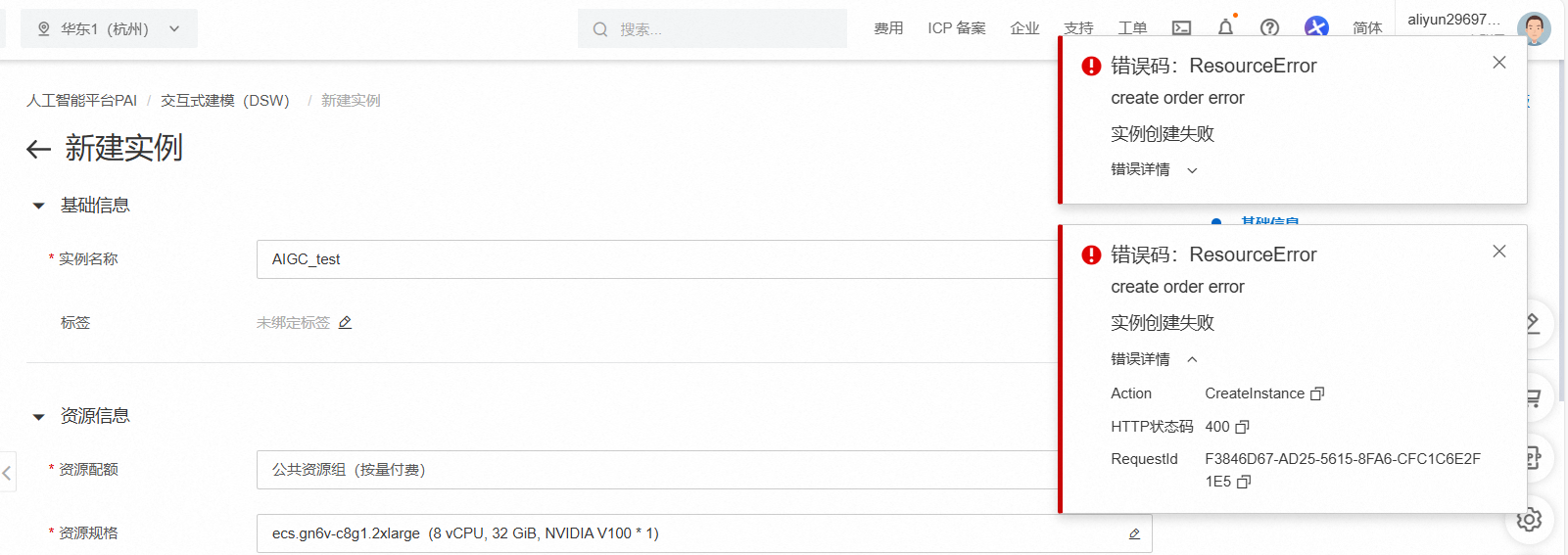
其他配置保持默认,点击左下角的确定,开始创建。
创建过程中,可以通过事件查看到创建时的日志记录。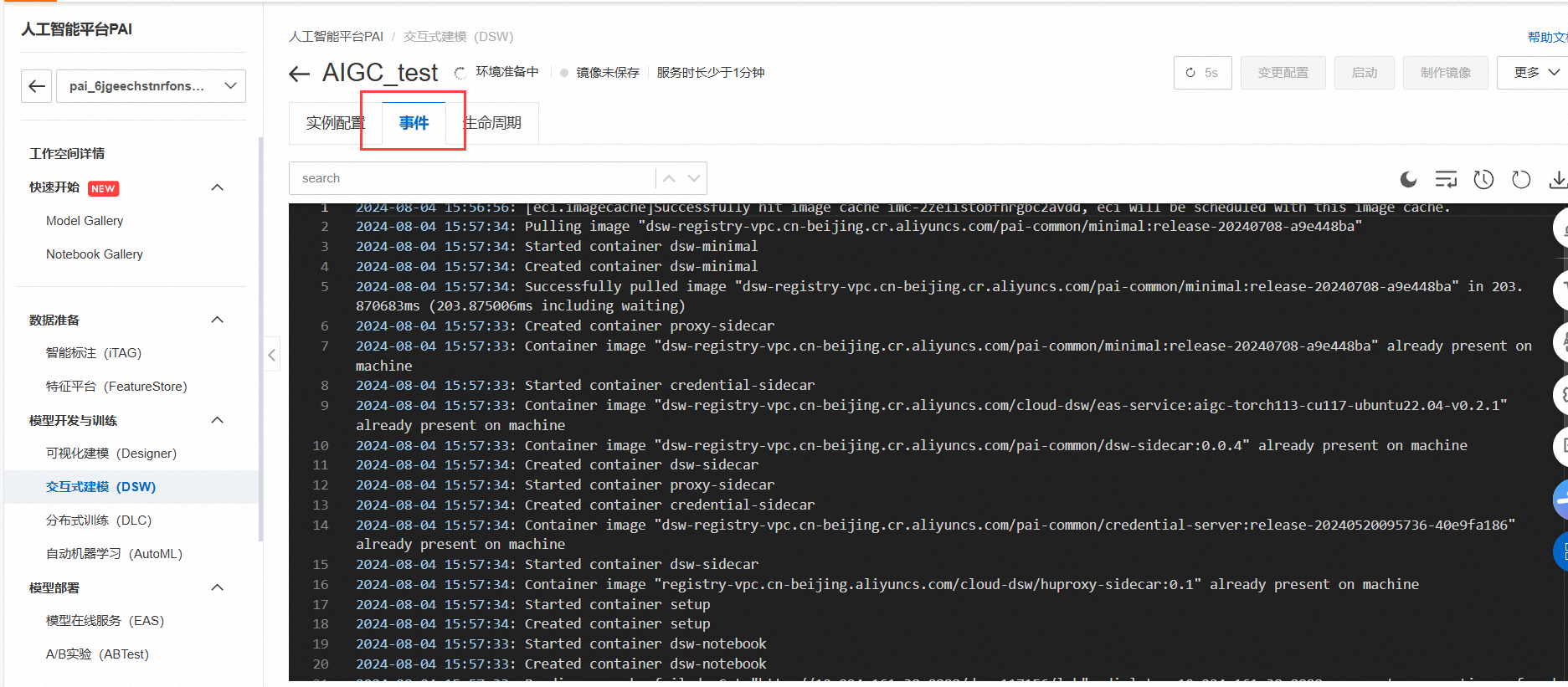
2分钟后,可以看到状态显示运行中,此时就表明实例创建成功。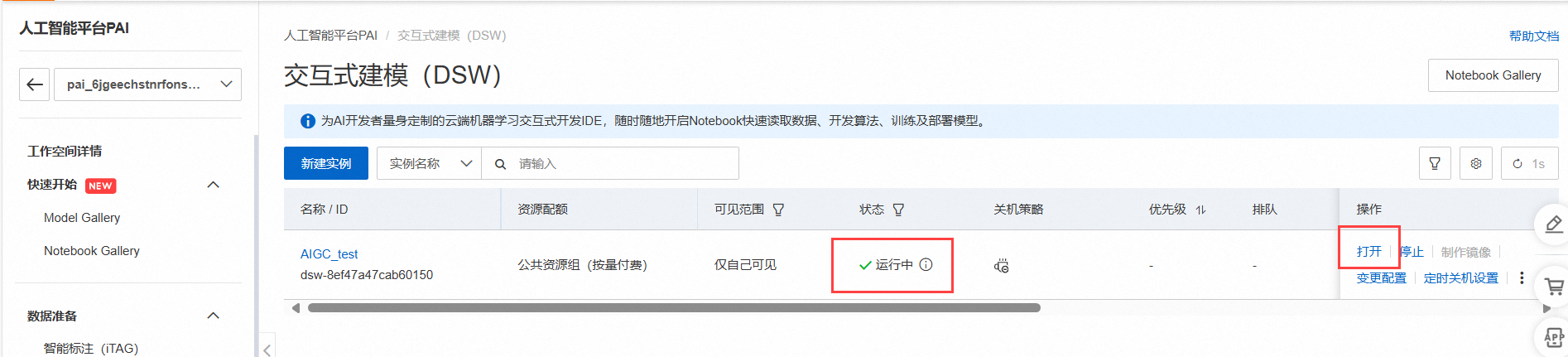
点击操作项的打开,即可进入PAI-DSW实例开发环境。
单击快速开始区域Notebook下的Python 3(ipykernel)
从GitHub下载Diffusers开源库,并安装相关依赖:
! git clone https://github.com/huggingface/diffusers
! cd diffusers && git checkout e126a82cc5d9afbeb9b476455de24dd3e7dd358a
! cd diffusers && pip install .
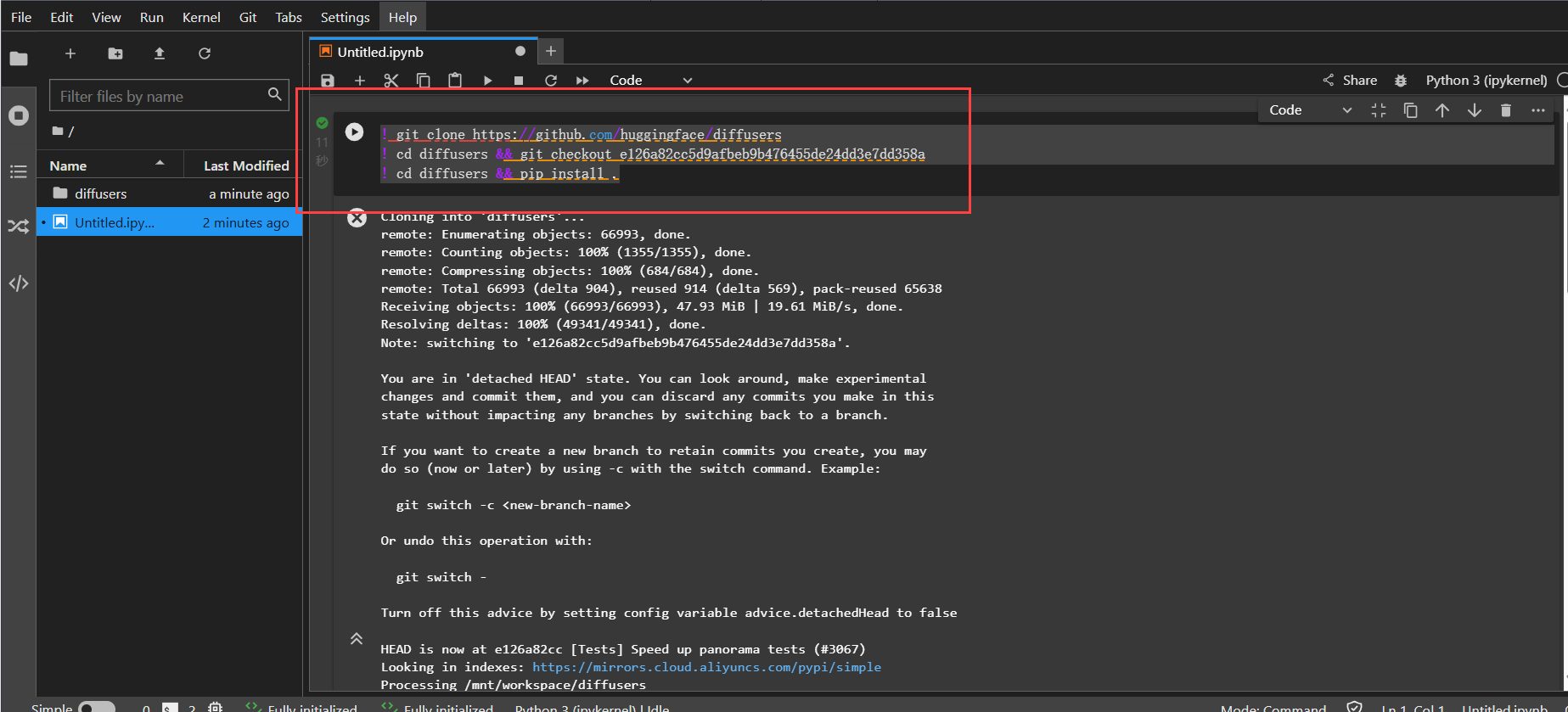
可以通过如下命令验证环境是否完成安装,如下:
import diffusers

执行如下命令,下载默认配置文件,配置accelerate。
! mkdir -p /root/.cache/huggingface/accelerate/
! wget -c http://pai-vision-data-sh.oss-cn-shanghai.aliyuncs.com/aigc-data/accelerate/default_config.yaml -O /root/.cache/huggingface/accelerate/default_config.yaml
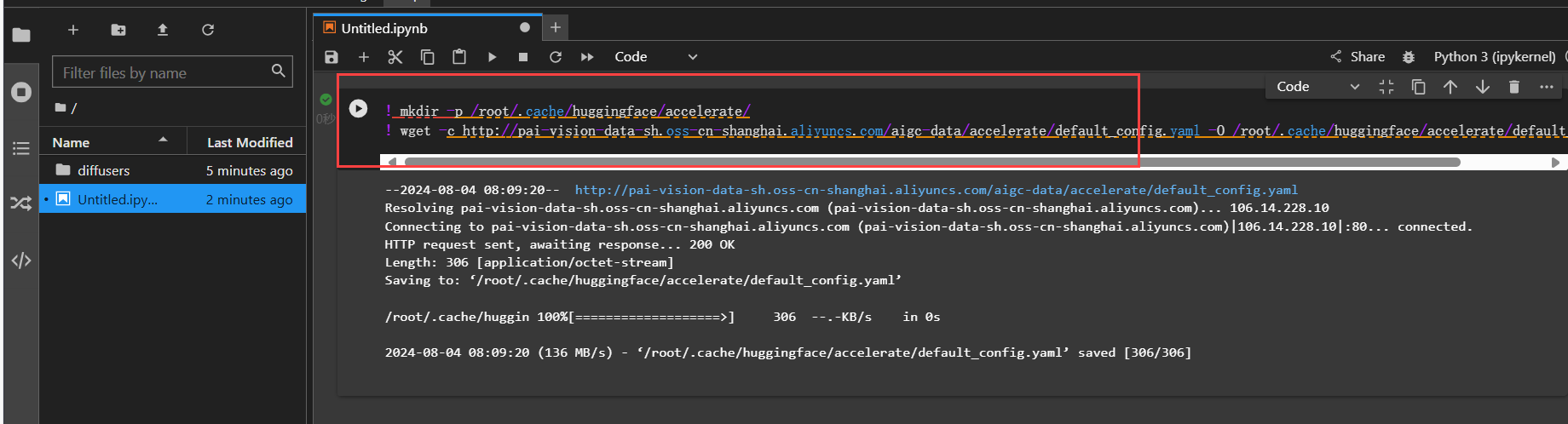
接下来,安装文生图算法相关依赖库。
! cd diffusers/examples/text_to_image && pip install -r requirements.txt
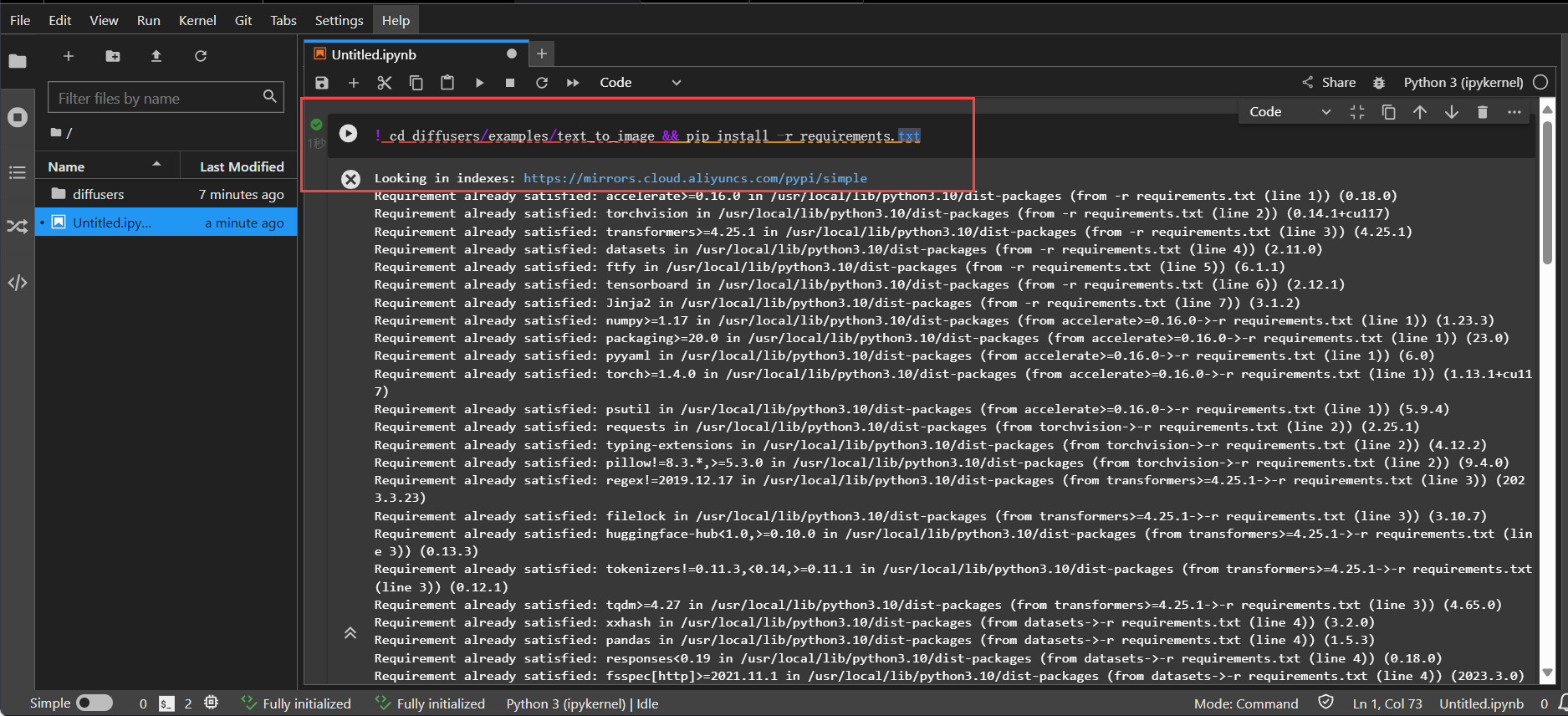
接着最重要的一步,就是下载stable-diffusion-webui开源库。
import os
! apt update
! apt install -y aria2
def aria2(url, filename, d):
!aria2c --console-log-level=error -c -x 16 -s 16 {url} -o {filename} -d {d}
url_prefix = {
"cn-shanghai": "http://pai-vision-data-sh.oss-cn-shanghai-internal.aliyuncs.com",
"cn-hangzhou": "http://pai-vision-data-hz2.oss-cn-hangzhou-internal.aliyuncs.com",
"cn-shenzhen": "http://pai-vision-data-sz.oss-cn-shenzhen-internal.aliyuncs.com",
"cn-beijing": "http://pai-vision-data-bj.oss-cn-beijing-internal.aliyuncs.com",
}
dsw_region = os.environ.get("dsw_region")
prefix = url_prefix[dsw_region] if dsw_region in url_prefix else "http://pai-vision-data-sh.oss-cn-shanghai.aliyuncs.com"
! git clone https://gitcode.net/mirrors/AUTOMATIC1111/stable-diffusion-webui.git
%cd stable-diffusion-webui
! git checkout a9fed7c364061ae6efb37f797b6b522cb3cf7aa2
repositories_url = f"{prefix}/aigc-data/code/repositories.tar.gz"
aria2(repositories_url, repositories_url.split("/")[-1], "./")
! tar -xf repositories.tar.gz
%cd extensions
! git clone https://gitcode.net/mirrors/DominikDoom/a1111-sd-webui-tagcomplete.git
! git clone https://gitcode.net/ranting8323/stable-diffusion-webui-localization-zh_CN
%cd ..
! wget -c http://pai-vision-data-sh.oss-cn-shanghai.aliyuncs.com/aigc-data/webui_config/config_tryon.json -O config.json
%cd ..
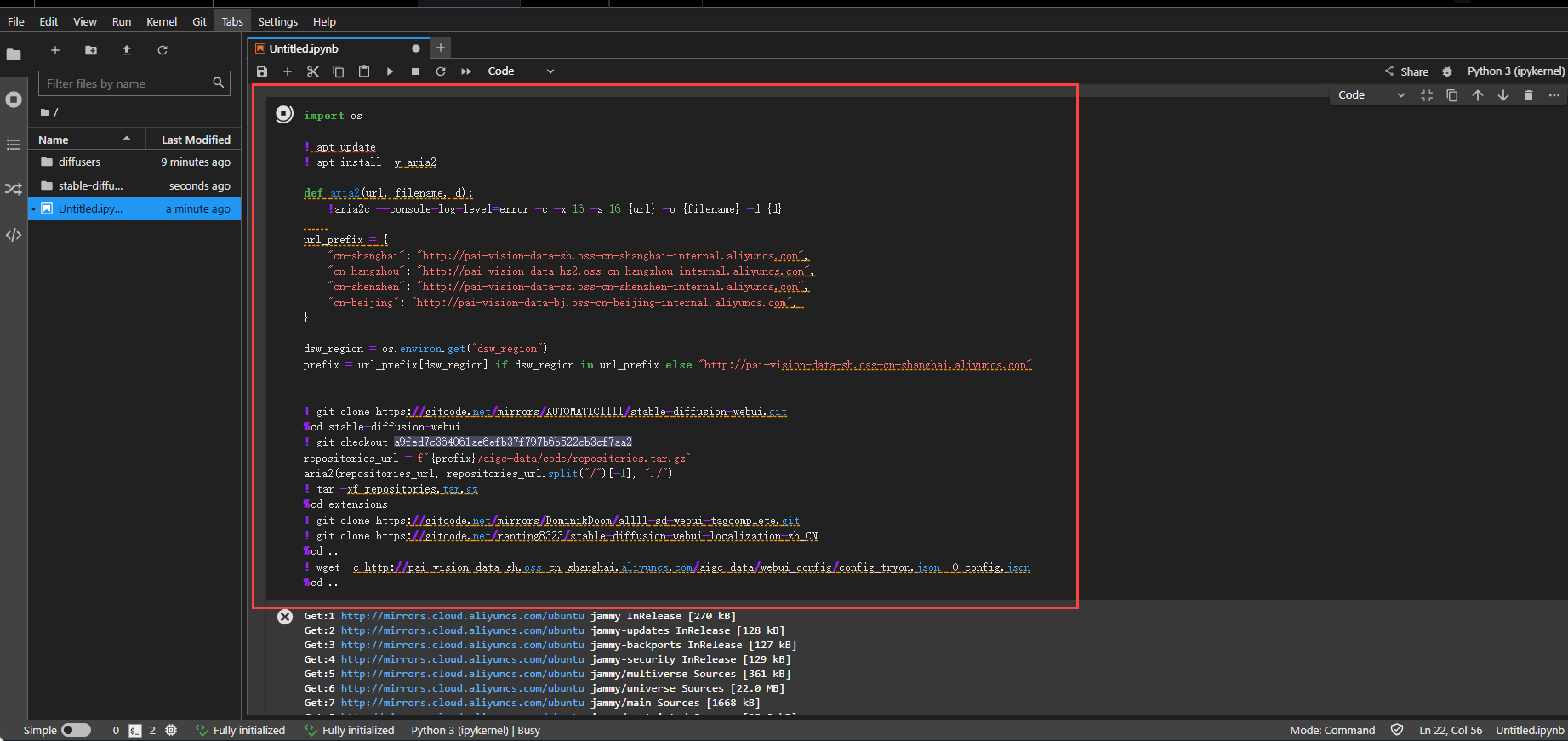
若需更新最新版本,你可以点击下面的开源链接前往进行下载。
stable-diffusion-webui
stablediffusion
taming-transformers
k-diffusion
CodeFormer
blip
通过命令运行窗口可以直观看到当前进度。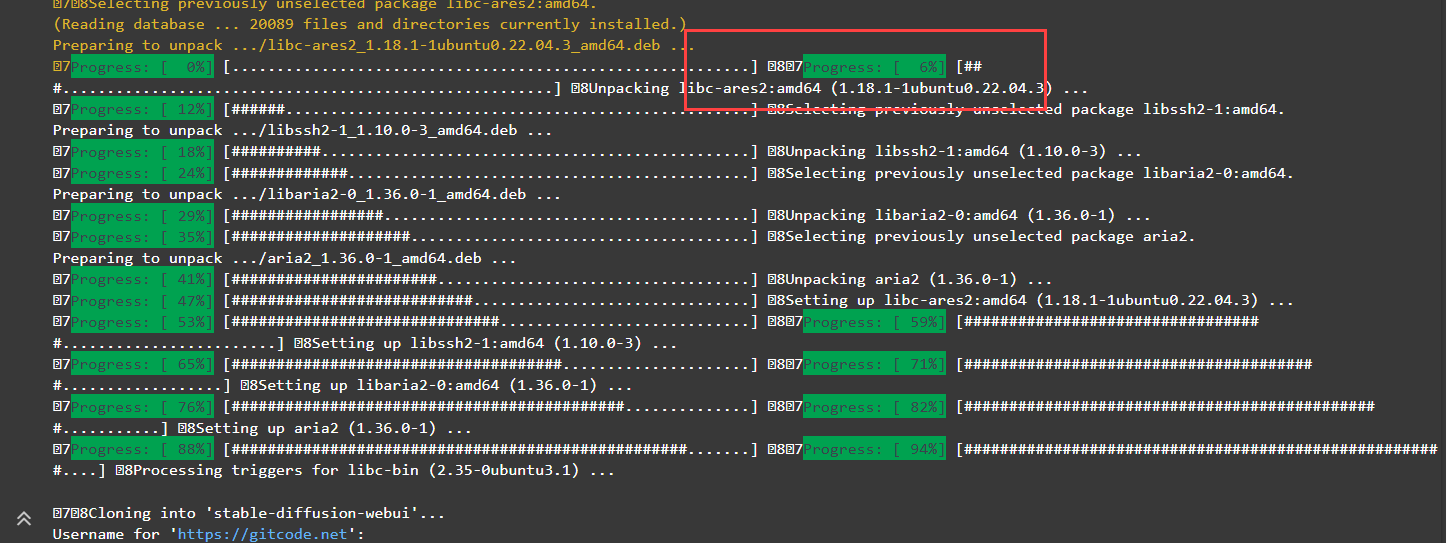
这个资源包有点大,需要耐心等待一下。
完成后,下载示例数据集及训练代码。
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/cloth_train_example.tar.gz && tar -xvf cloth_train_example.tar.gz
! wget http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/try_on/train_text_to_image_lora.py
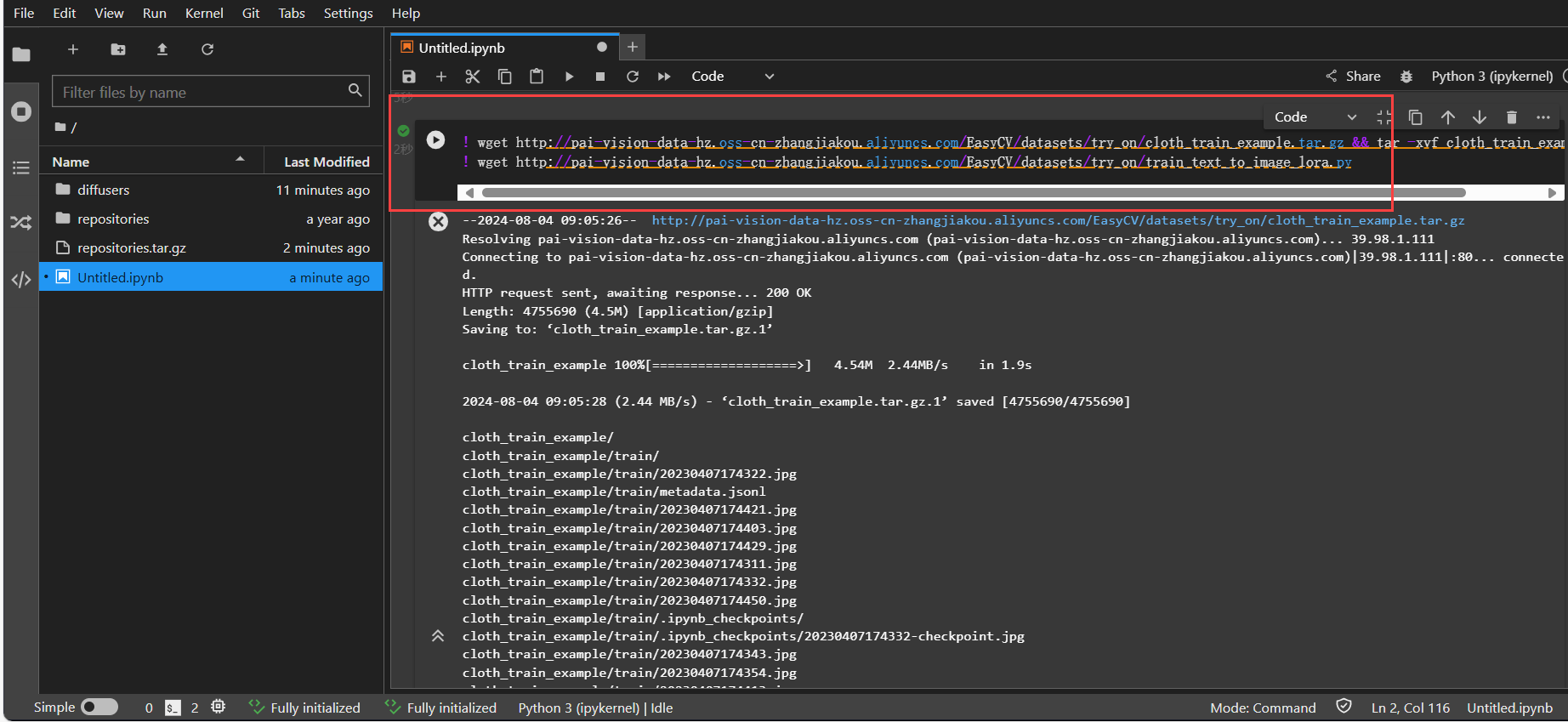
可以通过执行下述代码查看实例服装。
from PIL import Image
display(Image.open("cloth_train_example/train/20230407174450.jpg"))
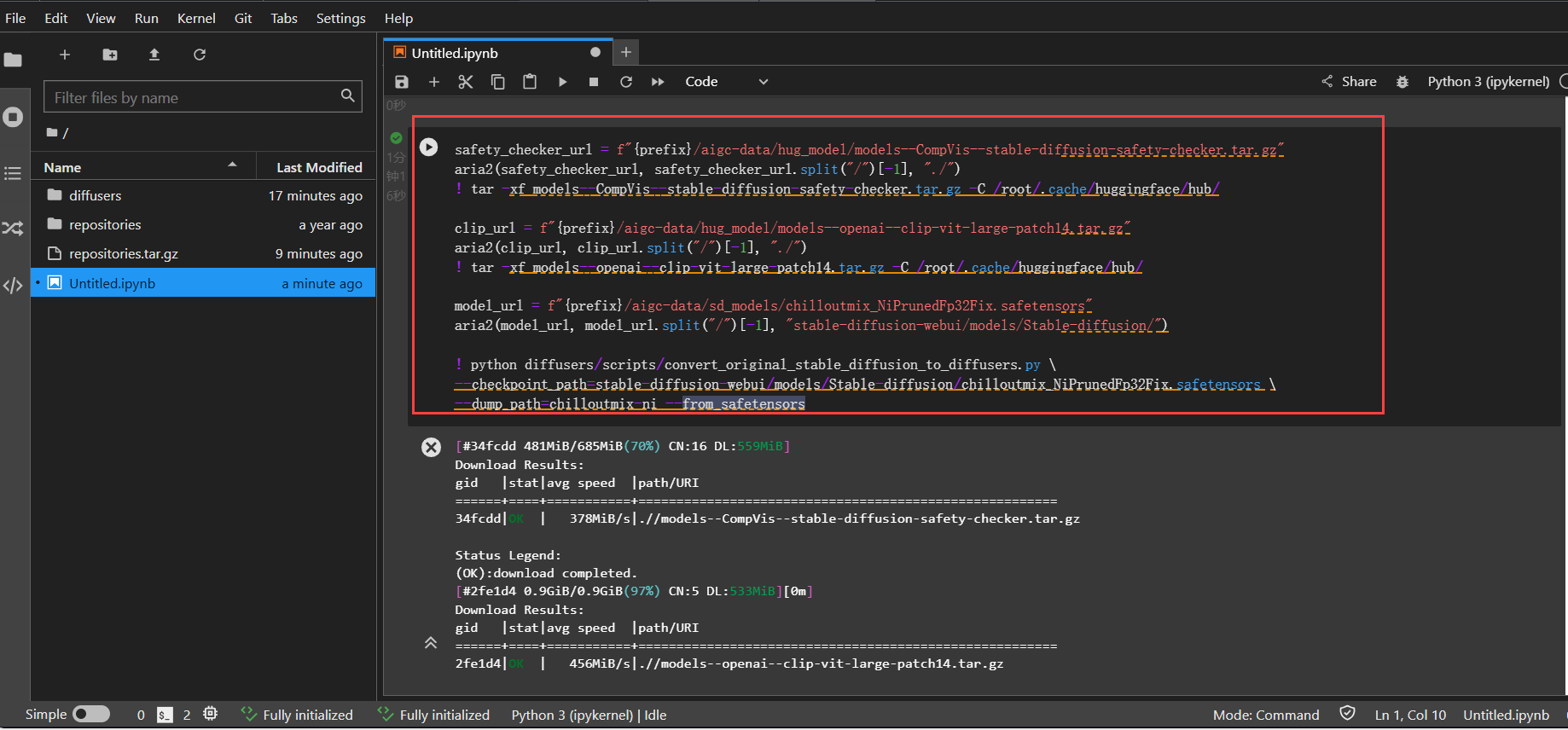
下载预训练模型并转化成diffusers格式。
safety_checker_url = f"{prefix}/aigc-data/hug_model/models--CompVis--stable-diffusion-safety-checker.tar.gz"
aria2(safety_checker_url, safety_checker_url.split("/")[-1], "./")
! tar -xf models--CompVis--stable-diffusion-safety-checker.tar.gz -C /root/.cache/huggingface/hub/
clip_url = f"{prefix}/aigc-data/hug_model/models--openai--clip-vit-large-patch14.tar.gz"
aria2(clip_url, clip_url.split("/")[-1], "./")
! tar -xf models--openai--clip-vit-large-patch14.tar.gz -C /root/.cache/huggingface/hub/
model_url = f"{prefix}/aigc-data/sd_models/chilloutmix_NiPrunedFp32Fix.safetensors"
aria2(model_url, model_url.split("/")[-1], "stable-diffusion-webui/models/Stable-diffusion/")
! python diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py \
--checkpoint_path=stable-diffusion-webui/models/Stable-diffusion/chilloutmix_NiPrunedFp32Fix.safetensors \
--dump_path=chilloutmix-ni --from_safetensors
设置num_train_epochs为200,进行lora模型的训练。
! export MODEL_NAME="chilloutmix-ni" && \
export DATASET_NAME="cloth_train_example" && \
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--width=640 --height=768 --random_flip \
--train_batch_size=1 \
--num_train_epochs=200 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="cloth-model-lora" \
--validation_prompt="cloth1" --validation_epochs=100

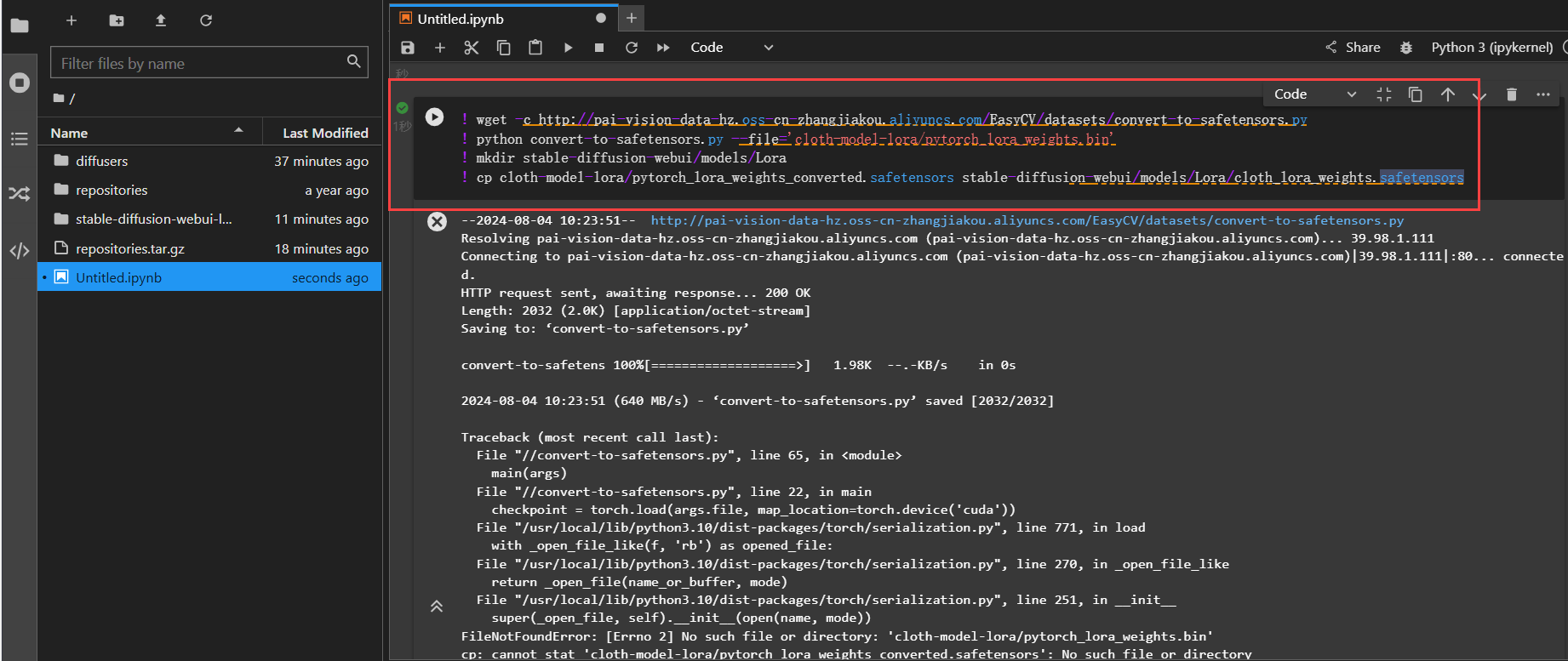
将lora模型转化成WebUI支持格式并拷贝到WebUI所在目录。
! wget -c http://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/EasyCV/datasets/convert-to-safetensors.py
! python convert-to-safetensors.py --file='cloth-model-lora/pytorch_lora_weights.bin'
! mkdir stable-diffusion-webui/models/Lora
! cp cloth-model-lora/pytorch_lora_weights_converted.safetensors stable-diffusion-webui/models/Lora/cloth_lora_weights.safetensors
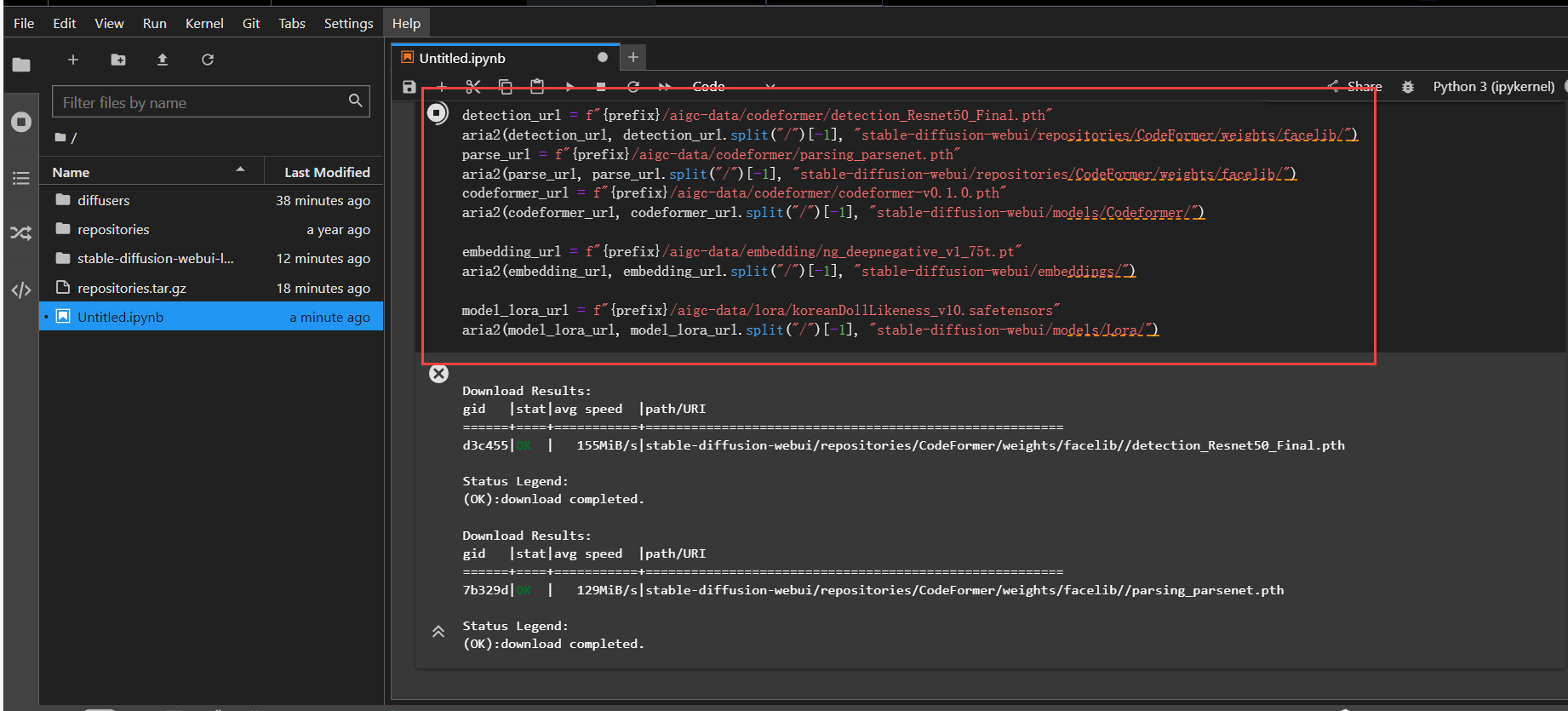
准备额外模型文件。
detection_url = f"{prefix}/aigc-data/codeformer/detection_Resnet50_Final.pth"
aria2(detection_url, detection_url.split("/")[-1], "stable-diffusion-webui/repositories/CodeFormer/weights/facelib/")
parse_url = f"{prefix}/aigc-data/codeformer/parsing_parsenet.pth"
aria2(parse_url, parse_url.split("/")[-1], "stable-diffusion-webui/repositories/CodeFormer/weights/facelib/")
codeformer_url = f"{prefix}/aigc-data/codeformer/codeformer-v0.1.0.pth"
aria2(codeformer_url, codeformer_url.split("/")[-1], "stable-diffusion-webui/models/Codeformer/")
embedding_url = f"{prefix}/aigc-data/embedding/ng_deepnegative_v1_75t.pt"
aria2(embedding_url, embedding_url.split("/")[-1], "stable-diffusion-webui/embeddings/")
model_lora_url = f"{prefix}/aigc-data/lora/koreanDollLikeness_v10.safetensors"
aria2(model_lora_url, model_lora_url.split("/")[-1], "stable-diffusion-webui/models/Lora/")
执行如下命令,启动WebUI。
! cd stable-diffusion-webui && python -m venv --system-site-packages --symlinks venv
! cd stable-diffusion-webui && \
sed -i 's/can_run_as_root=0/can_run_as_root=1/g' webui.sh && \
./webui.sh --no-download-sd-model --xformers --gradio-queue
在返回结果中,单击URL链接(http://127.0.0.1:7860),即可进入WebUI页面。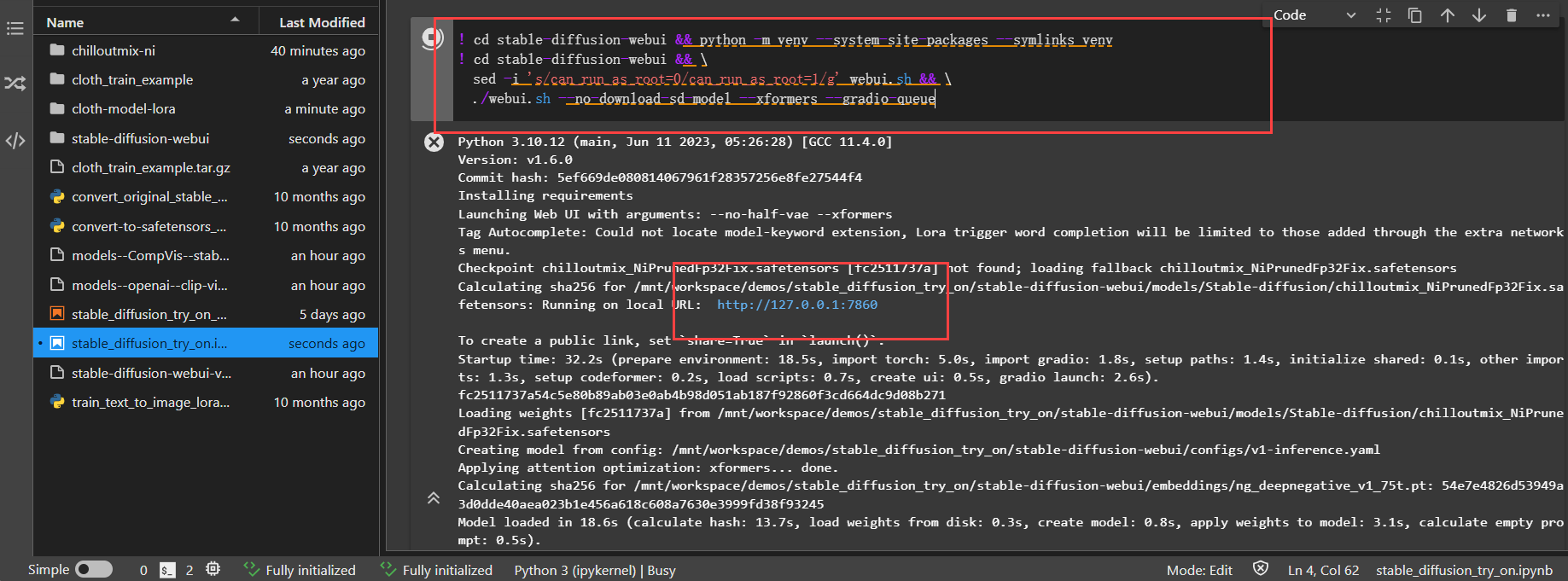
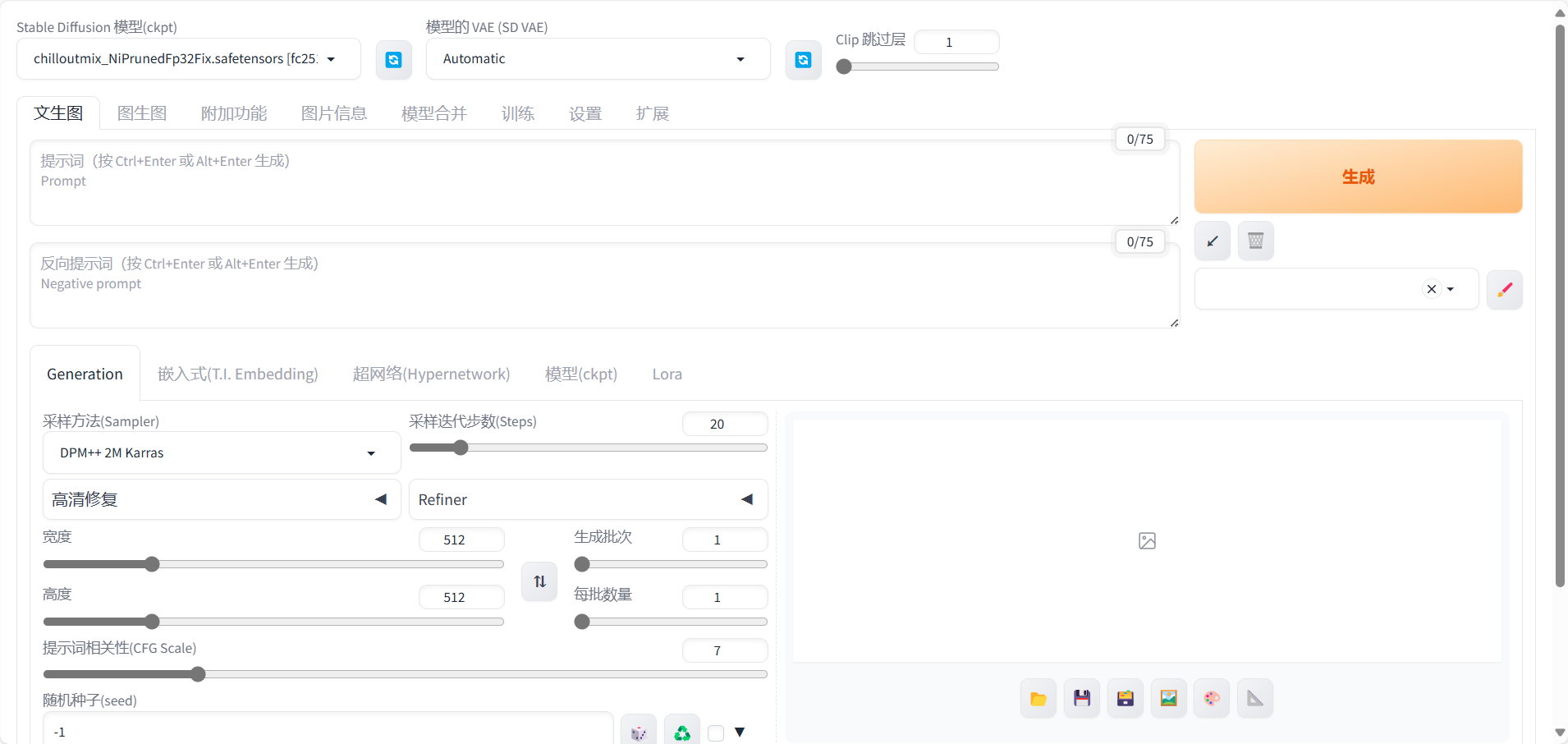
到这,我们已经完成了所有操作,成功完成了AIGC文生图模型微调训练及WebUI部署。接下来可以在WebUI页面,进行模型推理验证。
如果这个步骤因为拉取资源频繁失败,其实还有一种方法可以实施,那就是DSW Gallery。进入方式有两种,第一种: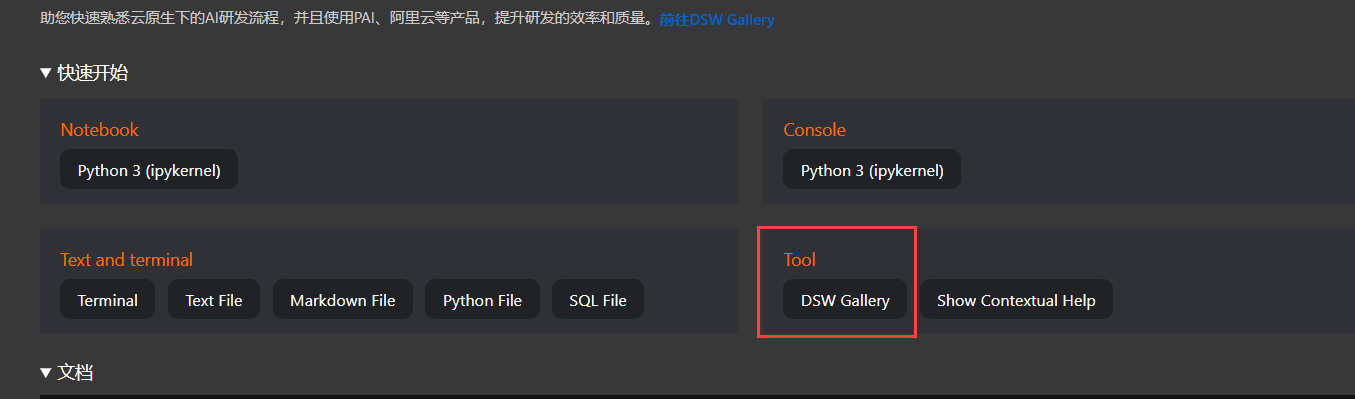
在页面中输入Lora搜索,找到“AIGC Stable Diffusion文生图Lora模型微调实现虚拟上装”。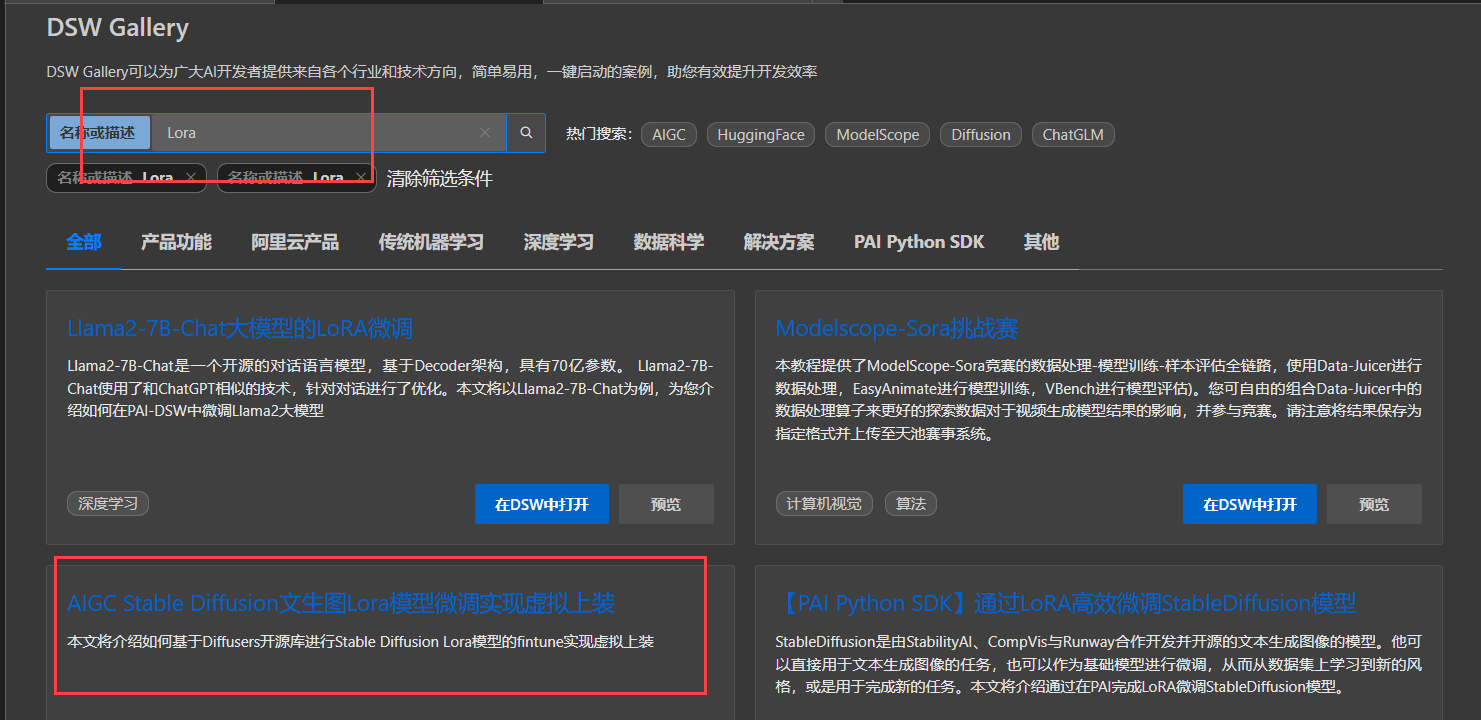
第二种,可以直接在工作空间左侧的快速开始——Notebook Gallery。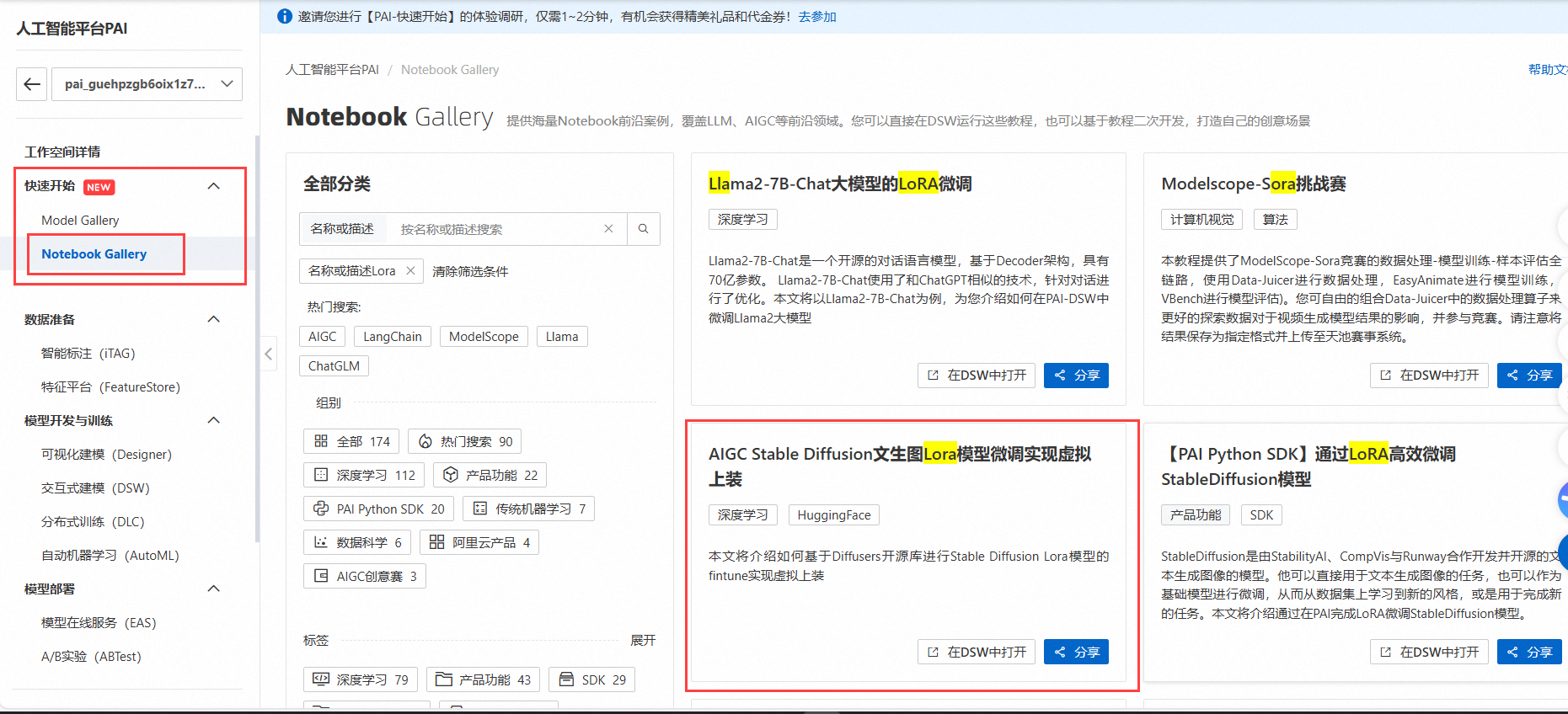
按照图示步骤挨个执行即可了,比起Notebook下的Python 3(ipykernel)要直观方便不少。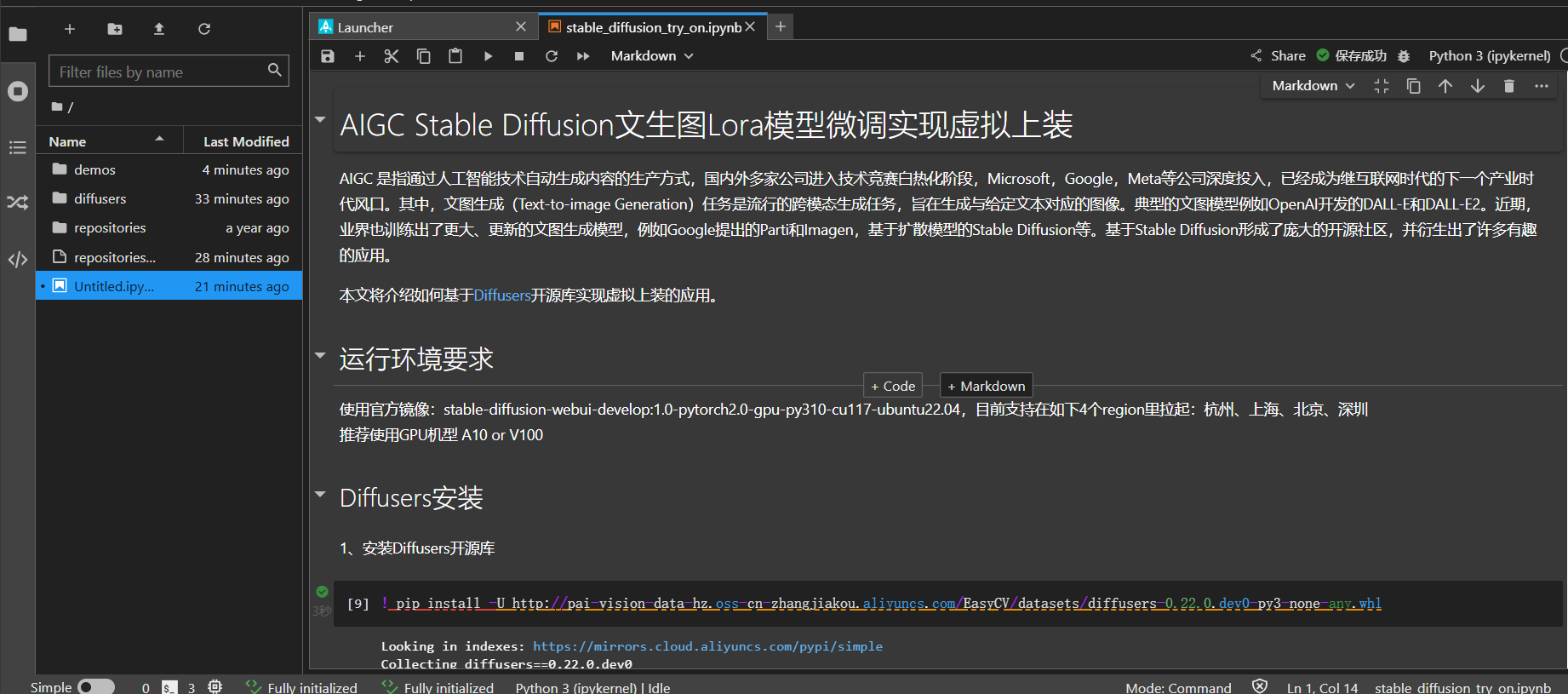
正向prompt:cloth1,, (extremely detailed CG unity 8k wallpaper),(RAW photo, best quality), (realistic, photo-realistic:1.2), a close up portrait photo, 1girl, shopping mall rooftop cafe, outdoor, smile, (high detailed skin:1.4), puffy eyes, gorgeous hair, air bangs, brown black hair, soft lighting, high quality,
负向prompt:ng_deepnegative_v1_75t,paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), (grayscale:1.2), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,(watermark:1.2),(letters:1.2),(nsfw:1.2),teeth
采样方法:Euler a
采样步数:50
宽高: 640,768
随机种子:1400244389
CFG Scale:7
使用高清修复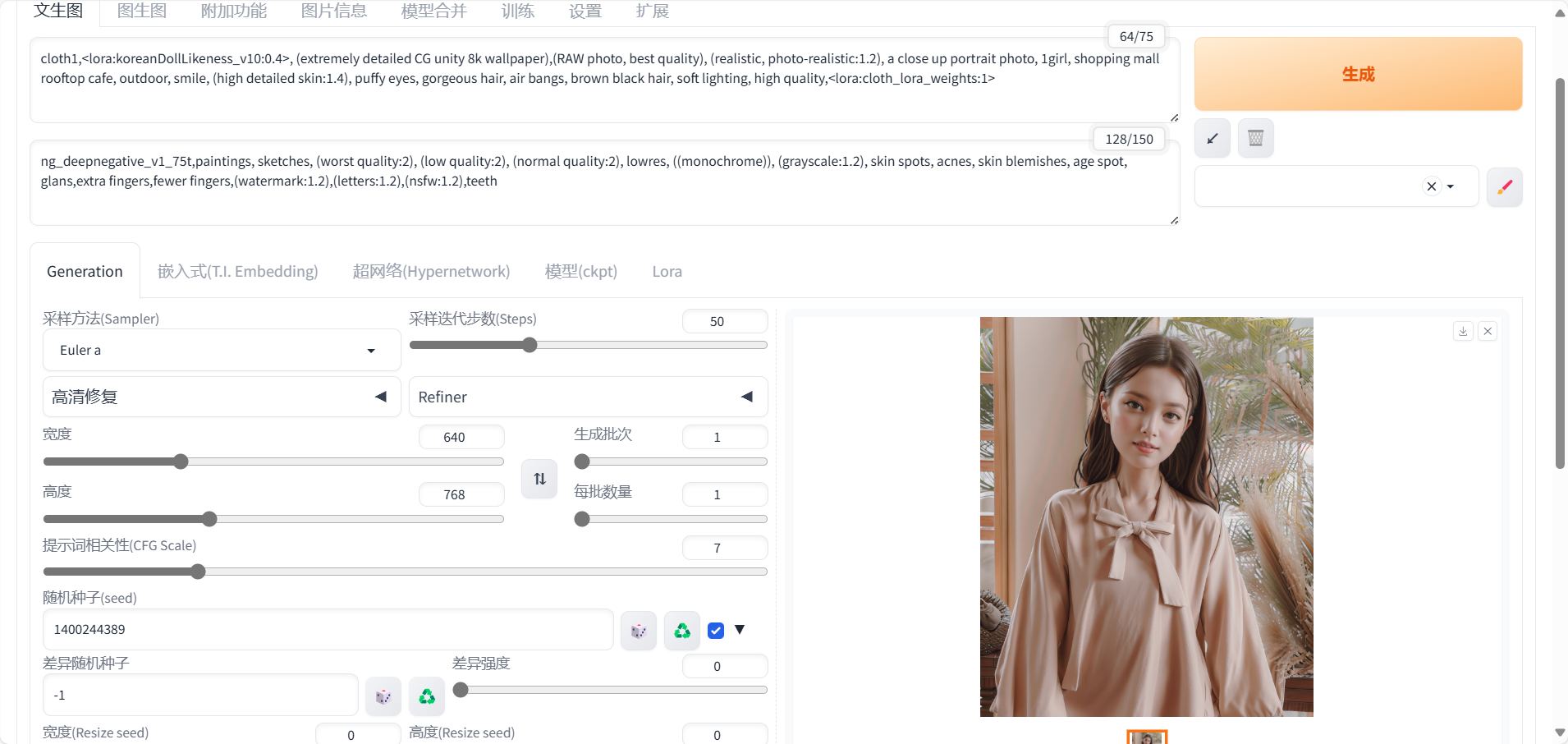
登录PAI控制台,在工作空间页面的左侧导航栏选择模型开发与训练>交互式建模(DSW),进入交互式建模(DSW)页面。单击目标实例操作列下的停止,成功停止后即可停止资源消耗。也就是达到了资源清理的效果。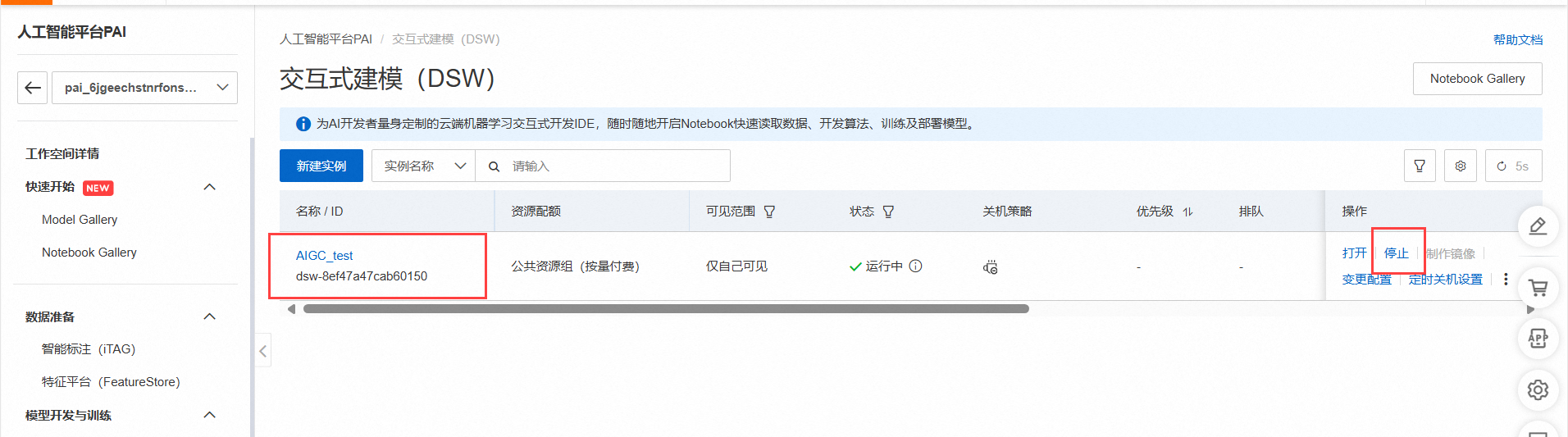
如果你不再使用这个实例,可以继续点击更多进行删除。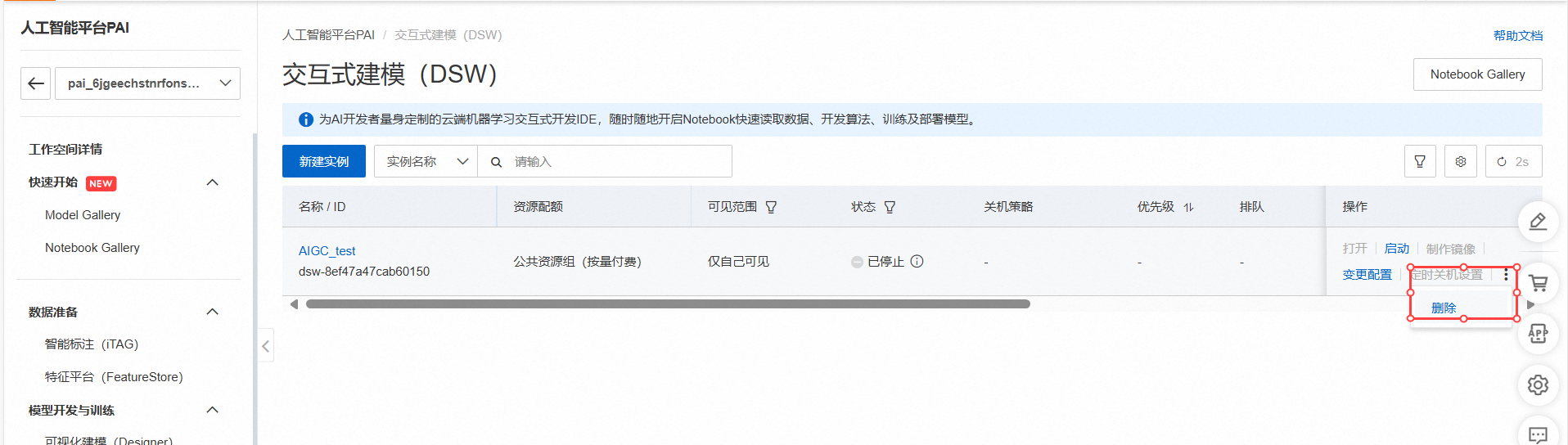
1、整个体验流程还是通畅的,但在某几个步骤时还是非常考验耐心的,由于需要从github拉取资源,而这个来源是存在网络时好时坏的,这块急需优化,非常影响体验。此外,由于参考的实验链接发布有点旧,里面使用到的资源链接都失效了,比如https://gitcode.net/mirrors/AUTOMATIC1111/stable-diffusion-webui.git,这个是404的。希望往后的体验能够及时修正这些细节。
2、如果有产品试用,其实整个体验的费用还是可以抵扣的。如果是老用户,这块的体验费用就非常高了,因为前面提到的拉取资源会非常耗时,这就从侧面增加了体验费用,此外,训练模型需要的耗时也是挺高的,所以如果你是整个流程都认真体验下来,这块的费用还是挺高的,可以达到30元以上。非常期待后期的体验可以缩减这块费用,让更多感兴趣的小伙伴前来体验。而不是现在的这个情况,从已经发布的话题内容来看,没一个朋友是实际购买实例进行体验的,都是直接挪用了实验中的图或者之前文章中的图稍作修改得来的。
3、非常建议类似这样需要搭建环境配置过程的话题,能否修改成一个专门的评测体验,一方面可以让更多优秀的作者加入体验,一方面可以很好地收集有关产品的建议和意见。
4、既然作为一个话题拿出来讨论,就应该让整个体验过程变得简约,比如魔塔社区模型体验那般就非常适合。建议往后的话题讨论能够简化整体的流程,比如无需部署基础环境,开箱即用。
5、加强与阿里云其他服务的整合,其实本次体验为了简化部署流程,是完全可以融合函数计算FC的。希望后期可以加强这方面的能力。
根据链接内容,以下是在阿里云DSW中基于Diffusers库进行AIGC Stable Diffusion模型微调及WebUI推理的配置过程、输出结果、使用体验截图和操作记录简述:
配置过程
环境准备:
登录阿里云PAI-DSW,选择或创建一个新的Notebook实例。
安装Diffusers和Stable-Diffusion-WebUI等必要库。
数据准备:
准备训练所需的文本和图像数据集,确保格式兼容。
模型微调:
在DSW Notebook中,编写代码加载Stable Diffusion模型。
使用Diffusers库对模型进行微调,输入训练数据和LoRA模型参数。
启动WebUI:
使用Stable-Diffusion-WebUI库配置并启动Web界面。
设置API接口,以便通过WebUI进行模型推理。
输出结果
微调训练完成后,输出模型性能评估指标,如损失值、生成图像质量评分等。
WebUI启动后,可通过界面输入文本查看实时生成的图像。
使用体验截图
截图包括DSW Notebook界面、训练过程日志、WebUI操作界面及生成的图像示例。
操作记录
记录了从环境搭建到模型训练、再到WebUI启动的全过程,包括每一步的代码执行和输出结果。
在阿里云的控制台上选择相应的服务,然后按照提示进行操作即可。在创建实例的过程中,可以选择不同的配置,包括CPU、内存和存储等。
创建好实例后,需要安装Diffusers开源库,这是进行AIGC Stable Diffusion模型微调训练所必需的。在实例中打开终端,然后使用pip命令安装Diffusers即可。
接下来,需要准备用于微调训练的数据集。在这个过程中,可以使用阿里云的对象存储服务(OSS)来存储和管理数据集。
准备好数据集后,就可以开始进行微调训练了。阿里云的交互式建模(PAI-DSW)提供了丰富的工具和框架,包括TensorFlow、PyTorch等,可以帮助轻松地进行模型的训练和调优。
在进行微调训练的过程中,可以使用阿里云的GPU加速服务来提高训练速度。阿里云提供了多种GPU实例,包括NVIDIA Tesla V100和NVIDIA A100等,可以满足不同规模和复杂度的训练需求。
经过一段时间的训练后,得到了一个微调后的AIGC Stable Diffusion模型。
训练好模型后,可以使用阿里云的WebUI服务来启动模型推理。阿里云的WebUI服务提供了一个简单易用的界面,可以帮助快速地进行模型的部署和推理。
在启动WebUI的过程中,需要将训练好的模型上传到阿里云的对象存储服务(OSS)中,然后在WebUI中配置相应的参数,包括模型路径、输入数据格式等。配置完成后,就可以启动模型推理了。
使用阿里云的交互式建模(PAI-DSW)进行AIGC Stable Diffusion模型的微调训练和推理,得到了非常满意的结果。微调后的模型在生成图像的质量和多样性方面都有了明显的提升,可以满足的实际需求。
此外,阿里云的交互式建模(PAI-DSW)还提供了丰富的工具和框架,可以帮助轻松地进行模型的训练和调优。同时,阿里云的GPU加速服务和WebUI服务也大大简化了模型的部署和推理过程。
通过实验领取免费资源或者使用个人资源
开通PAI-DSW服务
打开实例
在JupyterLab页签的Launcher页面,单击快速开始区域Notebook下的Python 3(ipykernel)。
根据实验手册完成操作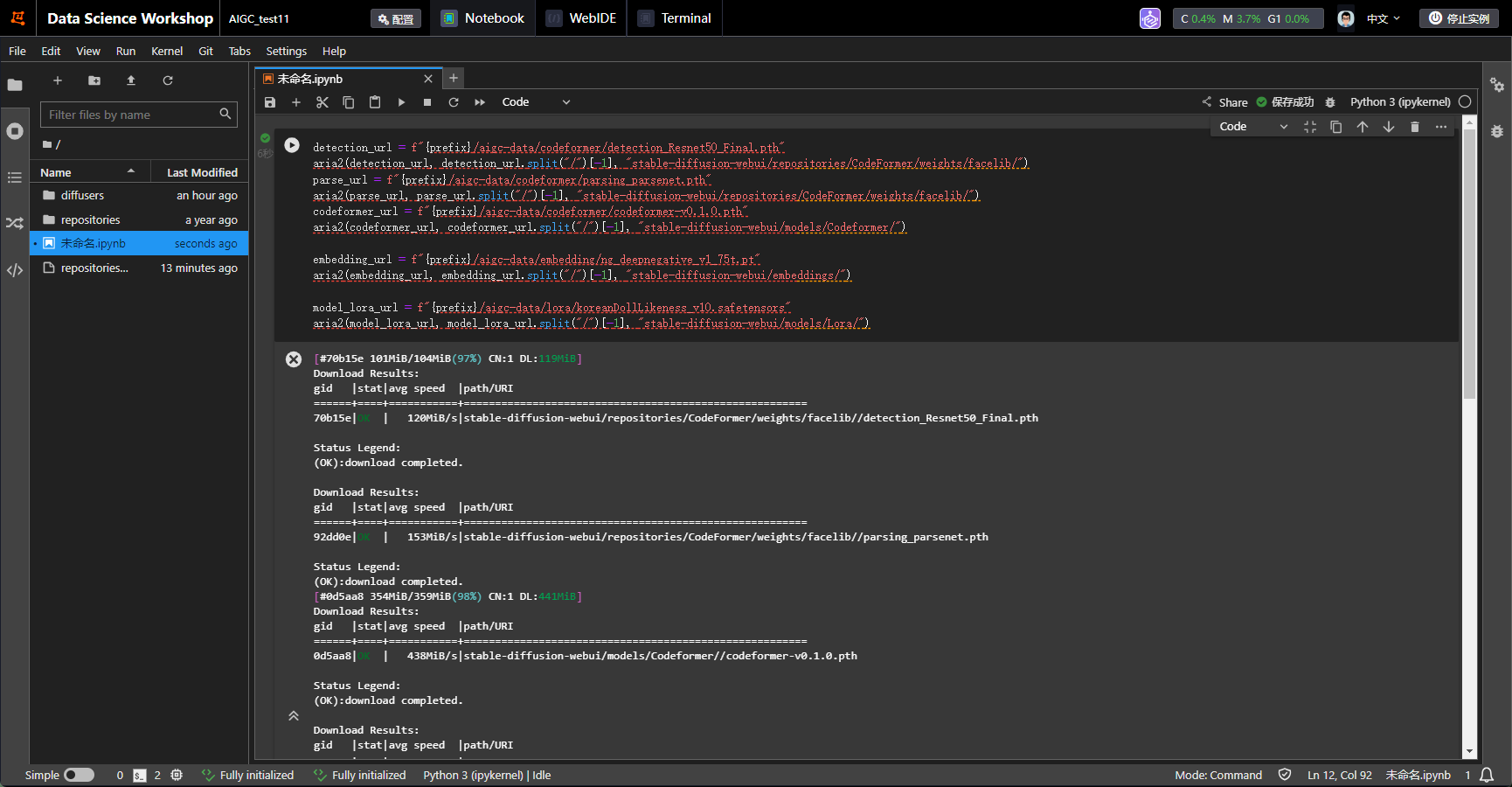
访问以上地址页面,进行模型推理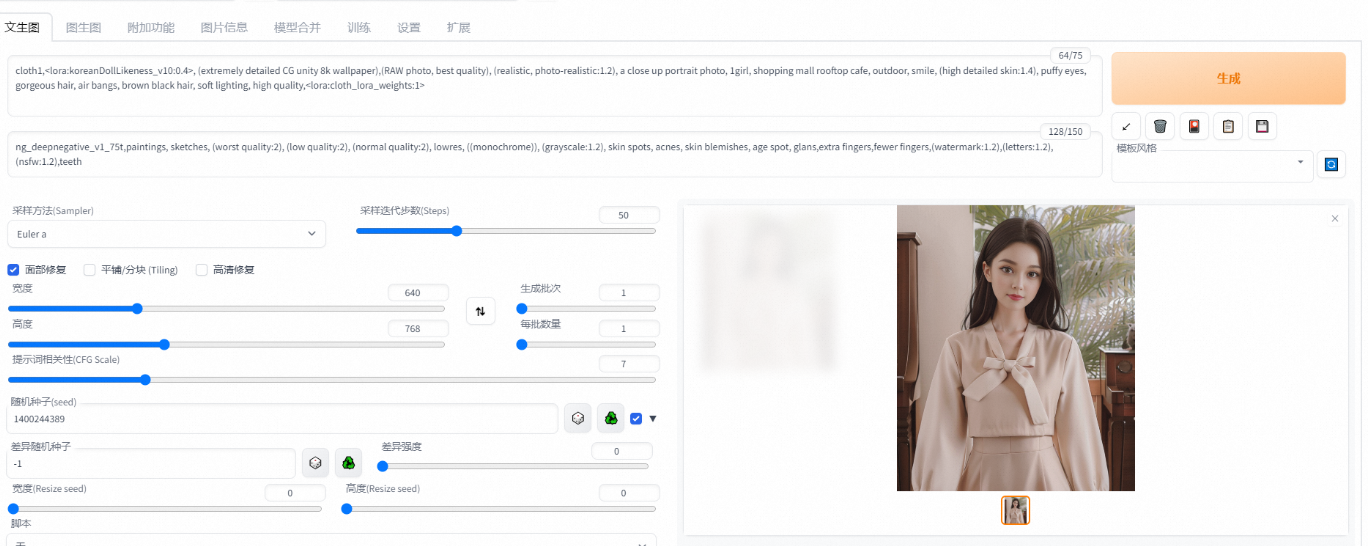
可进行相关调试完成推理结果
准备工作:
创建PAI-DSW实例:
安装依赖库:
torch、diffusers等。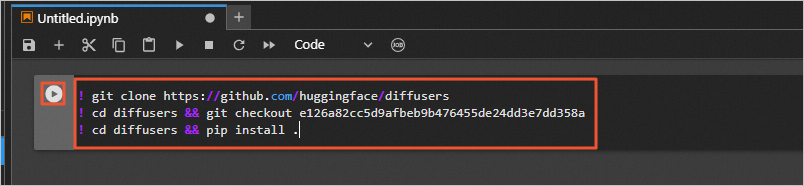
上传数据集:
模型微调:
启动WebUI进行推理:
使用阿里云交互式建模(PAI-DSW)进行AIGC Stable Diffusion模型微调训练,以及如何利用该模型在WebUI上进行文生图推理的体验。
首先,我通过给定的链接进入了操作页面,开始我的配置之旅。选择了一个合适的Stable Diffusion模型作为基础,上传了我自己的数据集,包括成对的文本和图片。在PAI-DSW平台上,设置参数相对简单直观,我调整了学习率、训练迭代次数等关键参数。
接下来的步骤,就是启动训练,看着进度条一点一点前进,心里还是有点小激动的。训练完成后,我得到了一个定制化的模型,准备进行推理测试。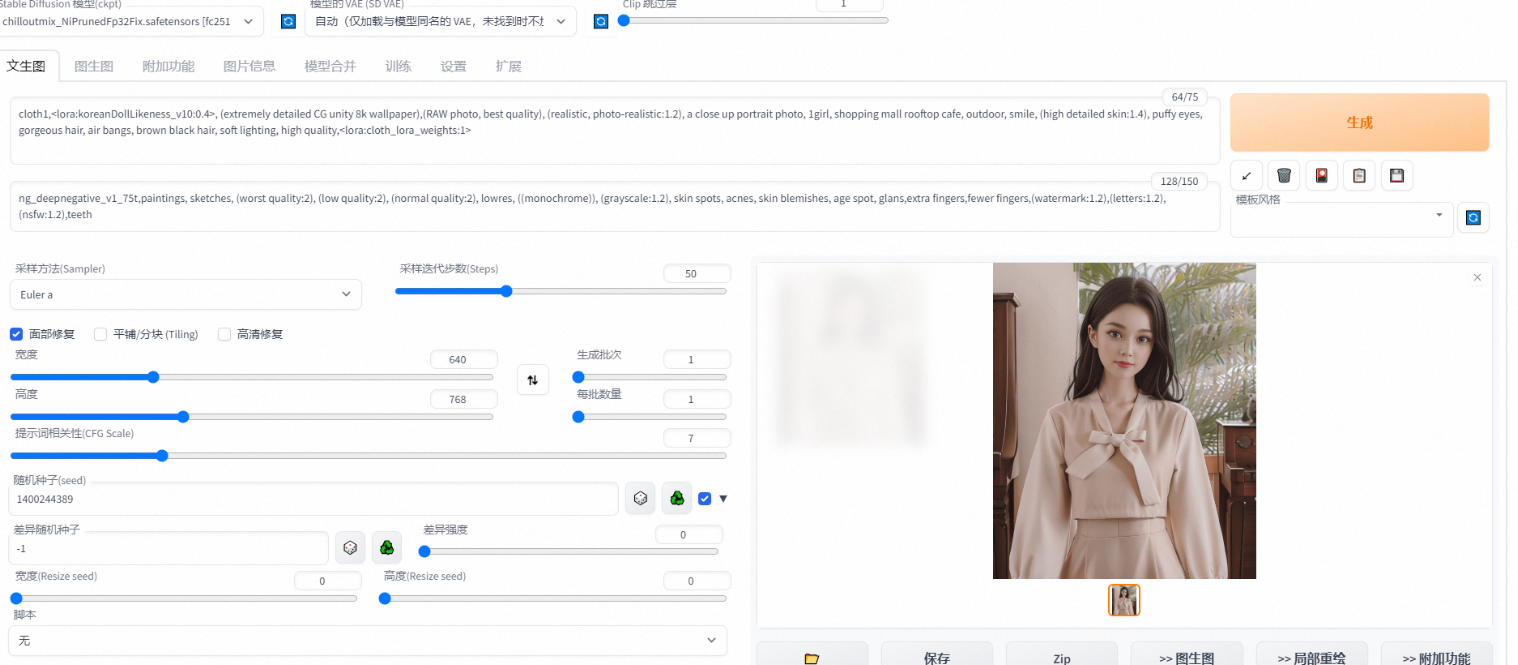
推理的效果挺让人惊喜的,我输入了一段描述性文本,“夕阳下的海边,海浪轻拍沙滩”,模型生成的图片竟然意外地贴合文本意境,颜色和氛围都相当到位。这样的结果让我对继续优化模型充满期待。
整个过程下来,感觉PAI-DSW还是挺好用的,界面友好,功能齐全,特别是对于我这种非专业算法人员来说,门槛降低了不少。而且,看到自己定制的模型能够生成如此质量的图片,确实很有成就感。
提示词
正向prompt
```cloth1,, (extremely detailed CG unity 8k wallpaper),(RAW photo, best quality), (realistic, photo-realistic:1.2), a close up portrait photo, 1girl, shopping mall rooftop cafe, outdoor, smile, (high detailed skin:1.4), puffy eyes, gorgeous hair, air bangs, brown black hair, soft lighting, high quality,
负向prompt:
```ng_deepnegative_v1_75t,paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), (grayscale:1.2), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,(watermark:1.2),(letters:1.2),(nsfw:1.2),teeth
如果你也对AIGC感兴趣,想快速入门并打造出自己的图像生成模型,强烈推荐尝试PAI-DSW。它不仅能提供稳定的训练平台,还能让你轻松分享和展示成果。
作为服务华为的运营工程师,使用 ODPS 两年,深刻体会其在通信设备运维场景的支撑力。华为基站设备日志日均增量超 TB 级,供应链数据跨 12 个区域节点,ODPS 的湖仓一体架构让分散数据实现统一调度,这是保障 5G 基站稳定运行的关键。 AI 爆发倒逼运维模式升级。过去设备故障分析依赖 T+1 报表,如今需实时预判潜在风险,这要求 ODPS 跳出传统计算框架。 ODPS 有引领数据革命的...
一、遇到的问题 创建应用需改参数并重启集群 修改 wal_level、polar_max_super_conns 会触发集群重启,高峰期操作有风险,新手容易踩坑。 网络配置略繁琐 应用默认不能访问外网,必须手动配 NAT 网关 + SNAT;应用白名单和集群白名单独立,要重复配置。 控制台入口较深 Dashboard 账号密码藏在配置页里,不好找;创建应用等待 3–5 分钟无进度提示。 Qo...
🎁嘿,大家好!👋 ,今天跟大家聊聊AI技术如何助力短剧领域的创新发展。随着AI技术的飞速发展,短剧创作迎来了前所未有的变革。这不仅仅是技术的进步,更是创意和效率的双重提升。🚀 AI助力短剧领域的创新 智能编剧辅助 创意生成:AI可以基于大数据分析,生成多种剧情梗概和创意点子。这对于编剧来说,就像是一个无穷无尽的创意宝库,可以激发更多的灵感。💡 剧本优化:AI还可以帮助编剧优化剧本,检...
建议:将通义灵码直接接入到阿里云函数计算,让更多的普罗大众可以使用自然语言实现自己的编程需求,例如自动获取招考公告等。 在当今数字化时代,编程不再是专业人士的专属技能。随着人工智能技术的发展,越来越多的普通人也开始尝试通过自然语言来实现自己的编程需求。通义灵码作为一种创新的自然语言处理工具,能够帮助用户更加便捷地完成各种编程任务,比如自动获取招考公告等。为了进一步推广这一技术,建议将通义灵码...
P人出游,你是否需要一个懂你更懂规划的AI导游呢? LLaMA Factory是一款低代码大模型微调框架,集成了百余种开源大模型的高效微调能力,使您无需深入理解复杂算法即可轻松进行模型微调。阿里云的人工智能平台PAI提供一站式机器学习服务,覆盖从数据预处理到预测的全流程,并支持多种深度学习框架与自动化建模,大幅降低了使用难度。通过结合PAI与LLaMA Factory,用户能够充分发挥二者优...

