
PolarDB这个日志是哪里配置出了问题?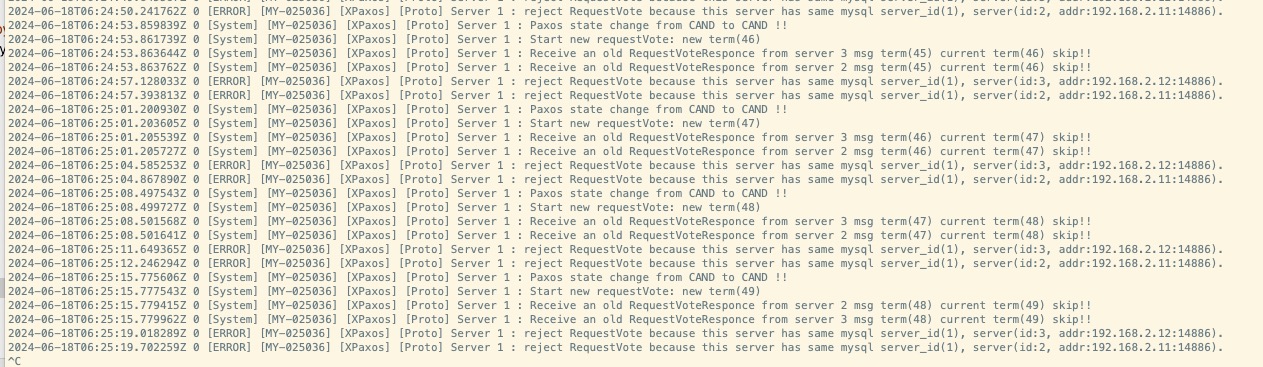
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
主要涉及MySQL的Paxos协议实现(可能是基于Group Replication或其他高可用方案)和选举过程中的冲突:
相同的MySQL server_id冲突:日志中多次提到“reject RequestVote because this server has same mysql server_id(1)” ,表明有多台服务器尝试参与选举时使用了相同的server_id(这里是1)。在MySQL的分布式一致性协议(如Paxos或Raft)中,每个节点需要有唯一的标识符(即server_id),以区分不同的参与者。解决这个问题需要确保集群中每台服务器的server_id是唯一的。
旧的RequestVote响应被跳过:多条日志显示收到了“old RequestVoteResponce”且其msg term小于当前term,因此被跳过。这是正常的Paxos行为,因为一旦服务器进入了一个新的任期(term),任何来自旧任期的投票请求都将被忽略,以防止过时信息干扰选举结果。
Paxos状态频繁在CAND(Candidate)状态间变化:日志中频繁出现“Paxos state change from CAND to CAND”,这可能意味着选举过程没有顺利产生领导者(Leader),服务器之间可能存在网络分区、通信延迟或配置不当,导致选举不断重新开始。
时间戳混乱:日志中的时间戳似乎存在格式错误或混乱的情况,例如“2024-06-18T86:24:53.861739Z”和“2024-06-18T06:24:53.863762Z”,小时部分超出了正常的24小时范围,这可能是日志打印错误或解析时的问题,但不影响对问题本质的理解。
解决建议:
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about


