
目前监听一个订单表,修改订单状态的时候我要获得相关的数据,然后处理数据,
我下载日志发现Flink有些订单监听到了,有些监听不到,这是什么情况?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Apache Flink 中,如果你发现有些订单被监听到了,而有些没有,这可能是由多种原因导致的。以下是一些可能的原因和对应的检查步骤,以及一个简化的代码示例来展示如何处理订单流。
可能的原因
数据源问题:
数据源可能不是实时发送所有订单数据。
数据源可能存在数据丢失或延迟。
Flink 作业配置:
并行度(Parallelism)设置可能不足以处理所有的订单数据。
时间窗口设置(如果使用了时间窗口)可能不合适。
状态后端(State Backend)可能有问题或资源不足。
代码逻辑:
KeyBy 操作可能不正确,导致订单没有被分配到正确的 KeyedStream。
过滤逻辑(如果有)可能错误地排除了某些订单。
资源限制:
Flink 集群的资源可能不足以处理所有订单。
网络、磁盘或内存限制可能导致数据丢失。
检查点和故障恢复:
如果 Flink 作业由于故障而重新启动,检查点(Checkpoints)可能不完整,导致状态丢失。
简化的代码示例
假设你有一个 Flink 作业,它从 Kafka 读取订单数据,并对每个订单进行某种处理: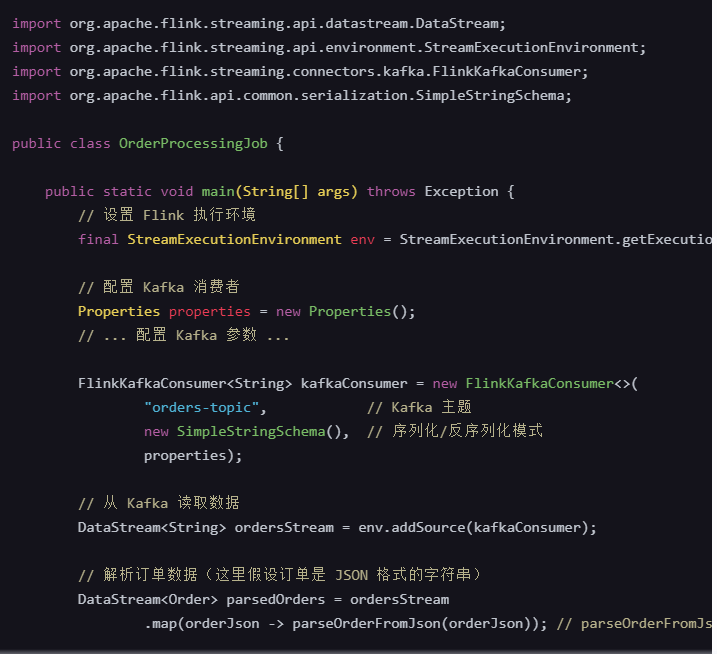

遇到部分订单被Flink监听到而另一些没有被监听到的情况,可能涉及多个因素。以下是可能的原因和排查方向:
数据生产与消费的对齐问题:
确保所有订单更改事件都正确发送到了Kafka或其他消息队列中。检查是否有网络问题、生产者错误或消息队列配置不当导致部分消息未被发送或延迟。
Flink消费者配置:
检查Flink作业中Kafka消费者的配置,特别是消费起始位移(offset)。如之前提到,使用earliest模式可以避免因位移问题导致的消息遗漏,但需注意这可能会重复处理历史数据。
Checkpoint与容错机制:
确认Flink作业的checkpoint机制是否正常工作,以及在遇到故障时是否能从最近的检查点恢复状态。如果checkpoint失败或不频繁,可能导致部分处理进度丢失。
水印(Watermarks)与事件时间处理:
如果你的处理逻辑依赖于事件时间(event time)窗口,检查水印(watermarks)的生成和传播是否正确。水印落后或不准确可能导致窗口无法及时关闭,从而影响数据处理的完整性。
并行度与数据分区:
Flink作业的并行度设置以及数据在Kafka中的分区策略可能会影响消息的分配。确保数据分区和Flink消费者并行度相匹配,避免数据倾斜或丢失。
网络与资源限制:
检查运行Flink集群的资源(CPU、内存、网络带宽)是否充足。资源不足可能导致任务处理速度下降,进而影响数据的实时处理。
日志与监控:
详细查看Flink作业的日志输出,寻找任何错误或警告信息。同时,利用Flink的监控界面或日志来跟踪数据流经各个算子的状态,以定位问题所在。
Kafka消费者组管理:
确保没有其他消费者也在同一消费组内消费这些消息,这可能导致消息被其他实例消费而Flink未能看到。
针对以上方向逐一排查,并根据实际情况调整配置或优化作业设计,应该能有效解决订单数据监听不全的问题。
订单监听不到可能是:
数据源问题:检查源表数据是否正常进入Flink,查看numRecordsIn_VVP指标确认是否有数据输入。
过滤或计算问题:检查作业中是否存在数据过滤,比如join、window或where操作可能导致部分数据未输出。
State管理:若开启了minibatch,确保table.exec.state.ttl配置合适,避免因状态过期导致无新数据更新。
日志分析:通过print操作将结果打印到日志,分析为何某些订单未处理。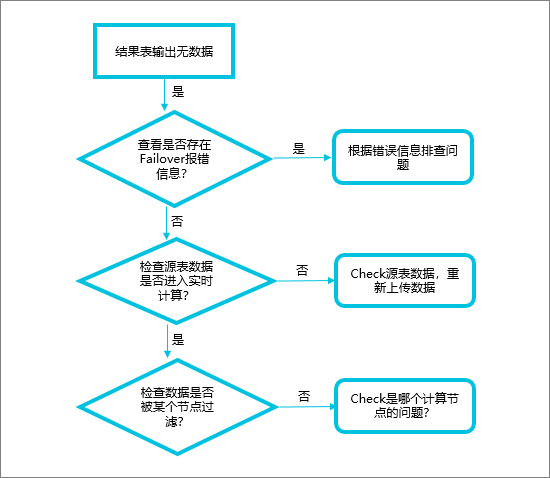
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


