
DataWorks写udf函数,没起作用,单独执行脚本是成功的,帮忙看看是哪的问题?
from odps.udf import annotate
@annotate('string->string')
class convert_latin_to_english(object):
def init(self):
self.mapping = {
'à': 'a', 'á': 'a',
'â': 'a', 'ã': 'a', 'ä': 'a', 'å': 'a', 'æ': 'ae', 'ç': 'c', 'è': 'e',
'é': 'e', 'ê': 'e', 'ë': 'e', 'ì': 'i', 'í': 'i', 'î': 'i', 'ï': 'i',
'ð': 'd', 'ñ': 'n', 'ò': 'o', 'ó': 'o', 'ô': 'o', 'õ': 'o', 'ö': 'o',
'ø': 'o', 'ù': 'u', 'ú': 'u', 'û': 'u', 'ü': 'u', 'ý': 'y', 'þ': 'th',
'ß': 'ss', 'ā': 'a', 'ă': 'a', 'ą': 'a', 'ć': 'c', 'ĉ': 'c', 'ċ': 'c',
'č': 'c', 'ď': 'd', 'đ': 'd', 'ē': 'e', 'ĕ': 'e', 'ė': 'e', 'ę': 'e',
'ě': 'e', 'ĝ': 'g', 'ğ': 'g', 'ġ': 'g', 'ģ': 'g', 'ĥ': 'h', 'ħ': 'h',
'ĩ': 'i', 'ī': 'i', 'ĭ': 'i', 'į': 'i', 'ı': 'i', 'ij': 'ij', 'ĵ': 'j',
'ķ': 'k', 'ĸ': 'k', 'ĺ': 'l', 'ļ': 'l', 'ľ': 'l', 'ŀ': 'l', 'ł': 'l',
'ń': 'n', 'ņ': 'n', 'ň': 'n', 'ʼn': 'n', 'ŋ': 'n', 'ō': 'o', 'ŏ': 'o',
'ő': 'o', 'œ': 'oe', 'ŕ': 'r', 'ŗ': 'r', 'ř': 'r', 'ś': 's', 'ŝ': 's',
'ş': 's', 'š': 's', 'ţ': 't', 'ť': 't', 'ŧ': 't', 'ũ': 'u', 'ū': 'u',
'ŭ': 'u', 'ů': 'u', 'ű': 'u', 'ų': 'u', 'ŵ': 'w', 'ŷ': 'y', 'ź': 'z',
'ż': 'z', 'ž': 'z', 'ſ': 's', 'ƀ': 'b', 'ƃ': 'b', 'ƅ': 'b', 'ƈ': 'c',
'ƌ': 'd', 'ƍ': 'd', 'ƒ': 'f', 'ƕ': 'hv', 'ƙ': 'k', 'ƚ': 'l', 'ƛ': 'l',
'ƞ': 'n', 'ơ': 'o', 'ƣ': 'oi', 'ƥ': 'p', 'ƨ': 's', 'ƪ': 's', 'ƫ': 't',
'ƭ': 't', 'ư': 'u', 'ƴ': 'y', 'ƶ': 'z', 'ƹ': 'z', 'ƺ': 'z', 'ƽ': 'z',
'ƾ': 'z', 'ƿ': 'w', 'dž': 'dz', 'lj': 'lj', 'nj': 'nj', 'ǎ': 'a', 'ǐ': 'i',
'ǒ': 'o', 'ǔ': 'u', 'ǖ': 'u', 'ǘ': 'u', 'ǚ': 'u', 'ǜ': 'u', 'ǝ': 'e',
'ǟ': 'a', 'ǡ': 'a', 'ǣ': 'ae', 'ǥ': 'g', 'ǧ': 'g', 'ǩ': 'k', 'ǫ': 'o',
'ǭ': 'o', 'ǯ': 'z', 'dz': 'dz', 'ǵ': 'g', 'ǹ': 'n', 'ǻ': 'a', 'ǽ': 'ae',
'ǿ': 'o', 'ȁ': 'a', 'ȃ': 'a', 'ȅ': 'e', 'ȇ': 'e', 'ȉ': 'i', 'ȋ': 'i',
'ȍ': 'o', 'ȏ': 'o', 'ȑ': 'r', 'ȓ': 'r', 'ȕ': 'u', 'ȗ': 'u', 'ș': 's',
'ț': 't', 'ȝ': 'g', 'ȟ': 'h', 'ȣ': 'ou', 'ȥ': 'z', 'ȧ': 'a', 'ȩ': 'e',
'ȫ': 'o', 'ȭ': 'o', 'ȯ': 'o', 'ȱ': 'o', 'ȳ': 'y', 'ȼ': 'c', 'ȿ': 's',
'ɀ': 'z', 'ɂ': 'z', 'ɇ': 'e', 'ɉ': 'j', 'ɋ': 'q', 'ɍ': 'r', 'ɏ': 'y'
# 添加更多的映射关系
}
def evaluate(self, s):
# 如果输入的字符串为空,直接返回空字符串
if not s or s =='' or not isinstance(s, str):
return None
result = ''
for char in s.lower():
if char in self.mapping:
result += self.mapping[char]
else:
result += char
return result
执行结果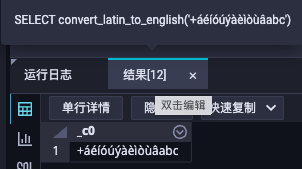
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
UDF包部署问题:
确保你已经将包含UDF的Python包(或者只是UDF的.py文件)正确地上传并部署到了DataWorks的ODPS环境中。在DataWorks中,通常需要将Python文件打包成ZIP文件,并通过“资源管理”->“上传资源”来上传这个ZIP包。
确保ZIP包中的目录结构正确,通常只需要包含.py文件和可能的依赖文件。
UDF注册问题:
在DataWorks中,需要在“数据开发”->“函数管理”中注册你的UDF。确保注册时填写的函数名、类名、资源类型等信息正确无误。
特别注意函数签名(即输入输出类型)是否与你在@annotate中定义的一致。
权限问题:
确保你的DataWorks账号有足够的权限去执行这个UDF,包括读取和写入数据的权限。
环境问题:
DataWorks中的ODPS环境与你的本地环境可能有所不同,特别是在Python版本和已安装的库方面。检查DataWorks的ODPS环境中是否支持你的UDF所需的Python版本和库。
如果UDF依赖于外部库,确保这些库也被正确地上传并部署到了ODPS环境中。
SQL调用问题:
检查在SQL中调用UDF的方式是否正确。确保函数名、参数等都正确无误。
尝试在DataWorks的SQL编辑器中运行一个简单的UDF调用示例,以确认基本的调用逻辑没有问题。
如果您在DataWorks中创建的UDF在业务流程中没有生效,但单独执行脚本是成功的,可能是以下原因:
函数注册问题:确保UDF已经正确注册到MaxCompute项目中,并且在DataWorks中能查看到。您可以通过SHOW FUNCTIONS命令检查是否在MaxCompute中可见。
函数引用问题:在业务流程中,确保您正确引用了自定义函数的名称。可以尝试在节点中使用引用函数功能,确保函数名称无误。
资源加载:确保关联的资源(如JAR包)已经加载到DataWorks,并且在函数创建时选择了正确的资源。
函数参数和返回类型:检查DESC FUNCTION 以确认函数的参数和返回类型是否匹配调用。
权限问题:检查当前用户是否有执行该UDF的权限。
数据类型或逻辑错误:UDF可能在特定输入数据上抛出异常,检查输入数据类型和函数内部逻辑。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


