
Flink CDC里提2个TiDB source connector的bugs,第一,当TiDB的一张表的字段数超过125,则解析记录时,记录的最后超过的字段的数据全部丢失,全部返回null。第二,当CDC的TiDB的表记录数很大时(有几千个regions),则当region发生合并,拆分之后,就再也收不到CDC数据。使用Flink CDC3.0版本,虽然是开源项目,但是也需要经过严格测试在release版本出来,免得使用者在生产环境中踩坑,非常的被动,上述2个bug经过源码排查,第一个是TiKV client类库自身的一个bug,第二是flink cdc的bug,希望社区有关开发者尽快修复啊。TiDB因为是golang开发的,所以TiKV client库的开发人员可能没有搞清楚java byte和golang byte类型的取值范围是不一样的,java是有符号的,而golang byte是无符号的。并且他们用一个byte类型的数组保存一行记录中字段的序号,在查找时又用了binarysearch,binarysearch要求数据是已排序的,所以有符号的和无符号的byte排序当然是不一样的,所以出现排序混乱导致超过127之后字段查询不到而返回null的bug,这是第一个bug,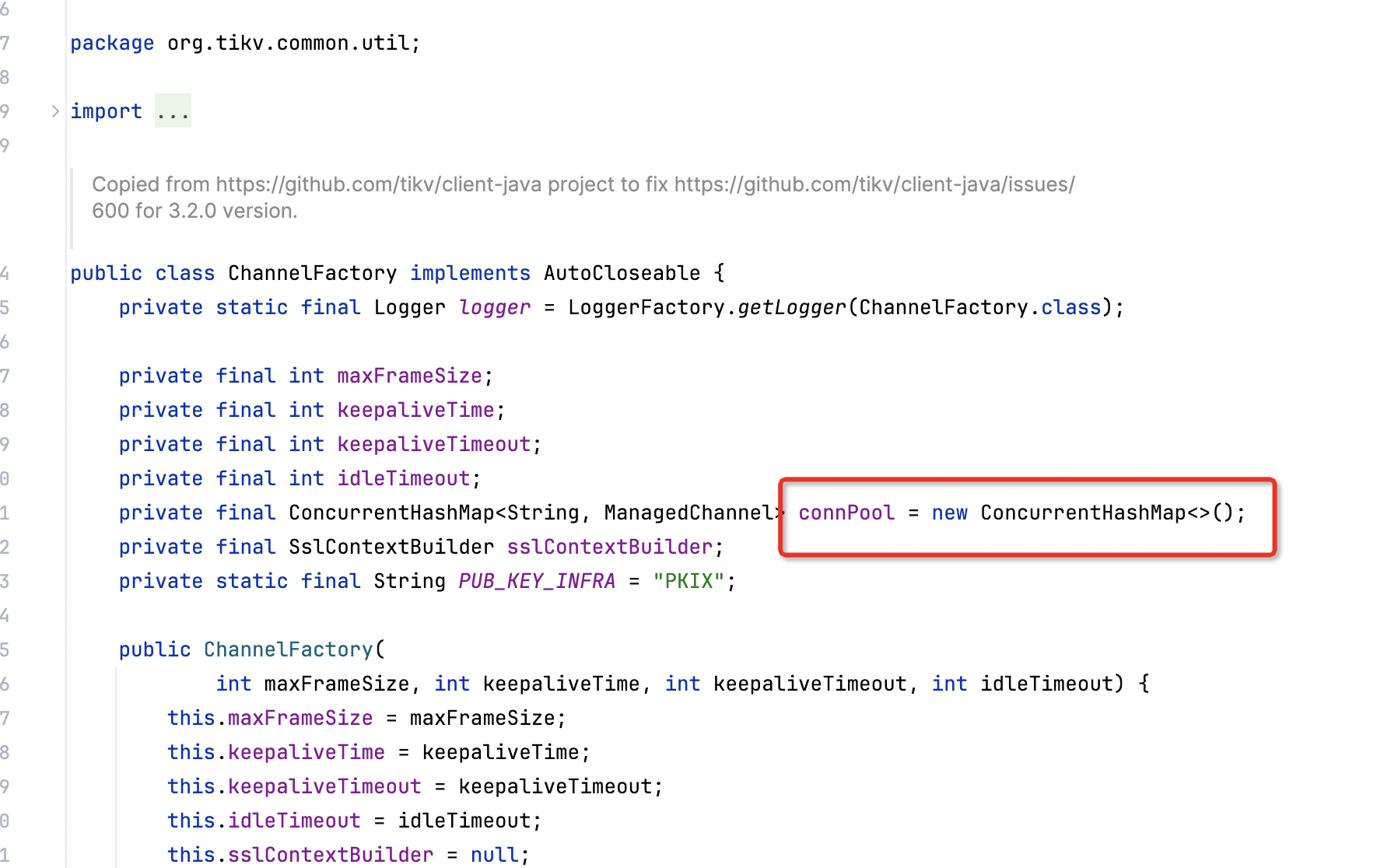 第二个bug涉及到org.tikv.common.util.ChannelFactory这个类中的缓存grpc channel的问题,这个缓存的实现是有问题的,在有几千个region的大表中,当发生合并,拆分后,channel已经失效了,但是为了提高效率,flink cdc复用了实效的channel,导致CDC events无法再接收到了。当然grpc channel是非常昂贵的资源,需要复用,这个没啥毛病,但是实现上有漏洞,我们正在自行修复这个问题。目前只是复现了这个bug。
第二个bug涉及到org.tikv.common.util.ChannelFactory这个类中的缓存grpc channel的问题,这个缓存的实现是有问题的,在有几千个region的大表中,当发生合并,拆分后,channel已经失效了,但是为了提高效率,flink cdc复用了实效的channel,导致CDC events无法再接收到了。当然grpc channel是非常昂贵的资源,需要复用,这个没啥毛病,但是实现上有漏洞,我们正在自行修复这个问题。目前只是复现了这个bug。
 这种问题只有在实际的生产环境中才能暴露出来,一开始我们在测试环境没有遇到任何问题,我正打算把tidb这块的connector重新写一下。
这种问题只有在实际的生产环境中才能暴露出来,一开始我们在测试环境没有遇到任何问题,我正打算把tidb这块的connector重新写一下。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
谢谢非常详细的bug report,可以分别在 Flink Jira 和 TiDB Github 上开issue记录下哈,钉群消息很快会被淹没。此回答来自钉群Flink CDC 社区 。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
