
在Flink我用 kafka 元数据,深度检查时,已经加了但是仍然报错;请问还要设置什么吗?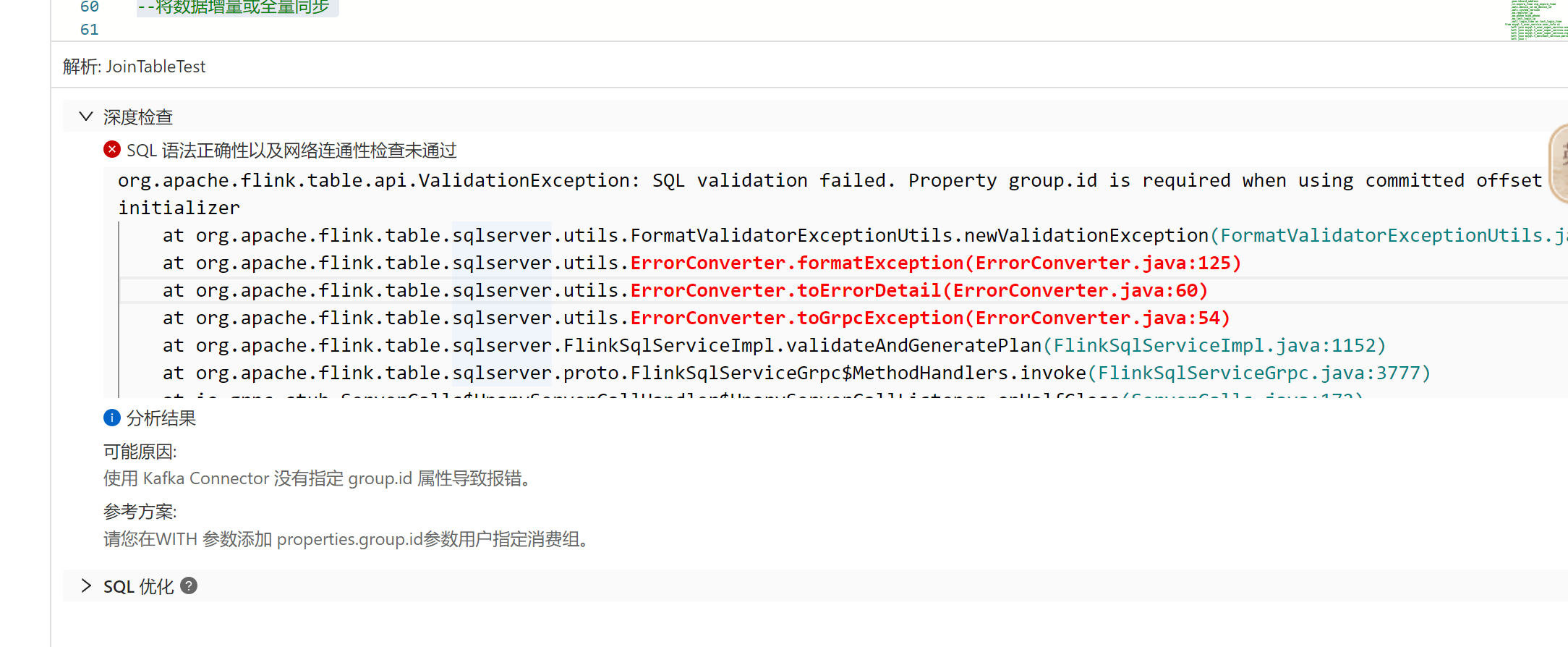
https://vvp.console.aliyun.com/web/c46e1a89755442/zh/#/workspaces/c46e1a89755442/namespaces/testtaskselectdb-default/draft/2fcaf78d-d5a8-4df9-ab9a-75d53c03cc51/sql
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
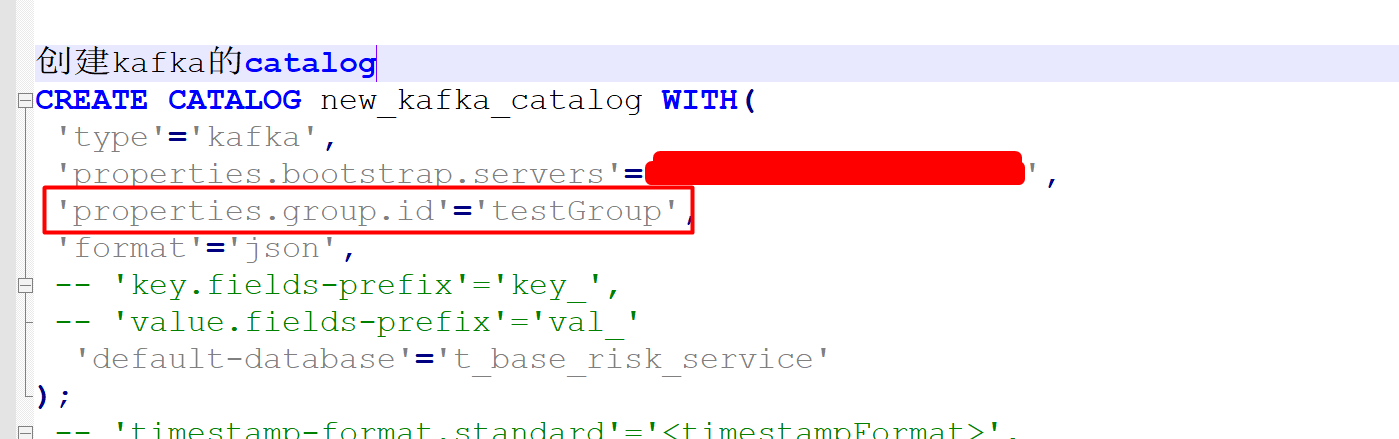
你看一下那个gropu.id的参数,应该是表名,但是您看看new_kafka的这个参数,并不是您的源表,所以catalog有问题,这个参数是错误的。所以您检验失败。方法:创建新的kafka的catalog时,不指定group.id。CREATE CATALOG WITH(
'type'='kafka',
'properties.bootstrap.servers'='',
'format'='json',
'default-database'='',
'key.fields-prefix'='',
'value.fields-prefix'='',
'timestamp-format.standard'='',
'infer-schema.flatten-nested-columns.enable'='',
'infer-schema.primitive-as-string'='',
'infer-schema.parse-key-error.field-name'='',
'infer-schema.compacted-topic-as-upsert-table'='true',
'max.fetch.records'='100',
'aliyun.kafka.accessKeyId'='',
'aliyun.kafka.accessKeySecret'='',
'aliyun.kafka.instanceId'='',
'aliyun.kafka.endpoint'='',
'aliyun.kafka.regionId'=''
);用这个,修改一下参数,试试。参考https://help.aliyun.com/zh/flink/user-guide/manage-kafka-json-catalogs?spm=a2c4g.11186623.0.i12 此回答整理自钉群“实时计算Flink产品交流群”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

