
iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch 这个模型 使用的tokenizer 是CharTokenizer 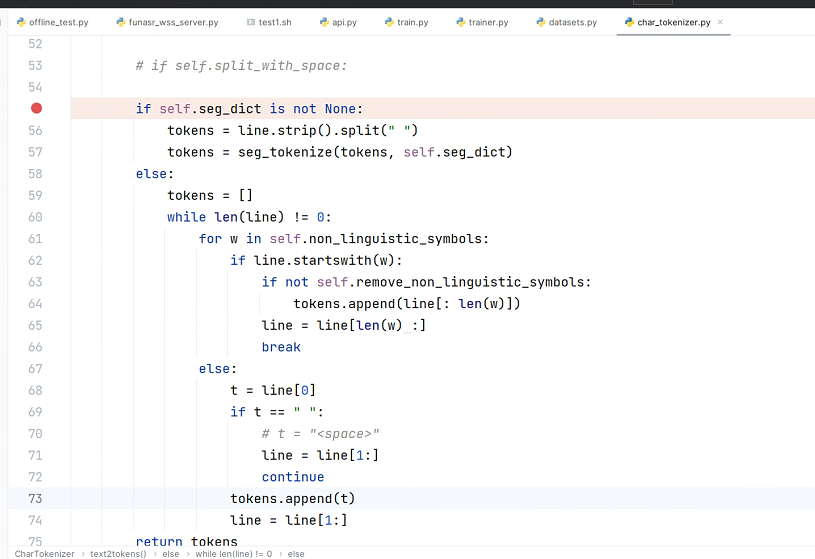
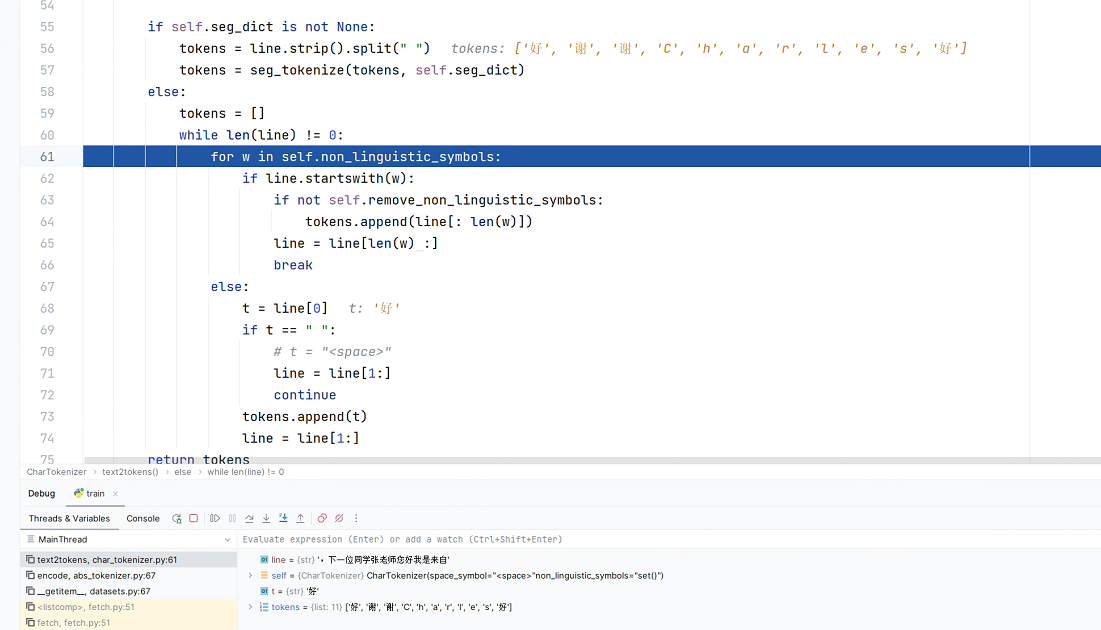
那比如 如果 我想微调 同时具备英文和中文能力时,这个地方 英文 也变成了一个字母一个字母的token话了。所以 在modelscope-funasr 如果想让模型同时具备 中文、英文能力 是不是 不能用这个预训练模型?或者说 可不可以换 tokenizer?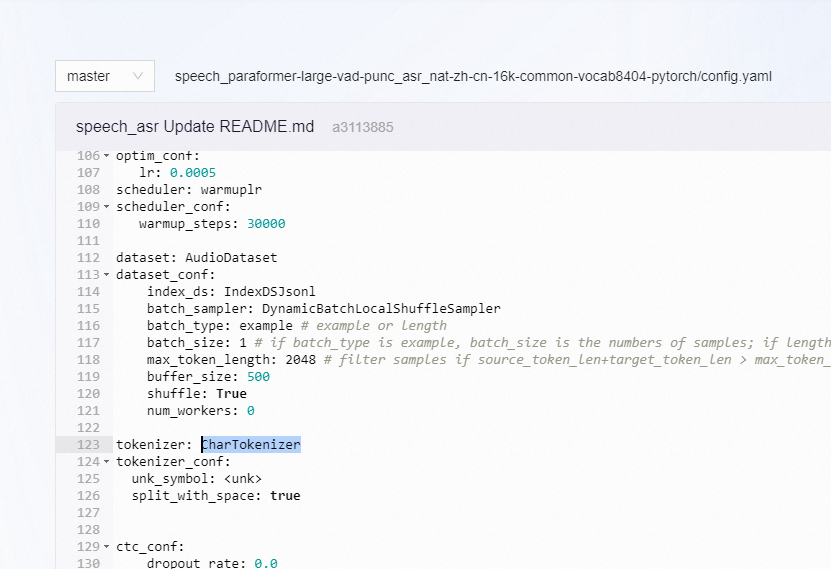
可以使用modelsce-funasr预训练模型进行中英文的语音识别,并且可以更换tokenizer。
modelscope-funasr是阿里巴巴提供的一个端到端的语音识别工具包,旨在为研究人员和开发人员在学术研究和工业应用之间架设桥梁。它支持多种语言,包括中文和英文,因此具备同时处理这两种语言的能力。ModelScope平台上也提供了多种不同大小、不同语种的模型供用户选择和使用。
关于iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch这个模型使用的tokenizer,它是以字符为单位进行分词的CharTokenizer。这种分词方式对于中文来说十分合适,因为中文写作不像英文那样由空格分隔单词。但是对于英文来说,这可能会导致将每个字母作为一个独立的token,这并非最佳做法。
在modelscope-funasr中,如果想要支持新的语言或者修改现有的语言处理能力,可以通过修改tokenizer来实现。比如拓展到维吾尔语,就可以使用相应的bpe模型生成新的tokenizer,并替换掉原来的tokenizer。同样地,如果需要支持中英文混合识别,理论上也是可以更换一个适合中英文的tokenizer,或者对现有tokenizer进行适当修改来达到目的。
综上所述,虽然modelscope-funasr提供的预训练模型默认使用的是CharTokenizer,但用户可以根据自己的需求更换或定制tokenizer,从而实现想要的中英文混合语音识别功能。


