
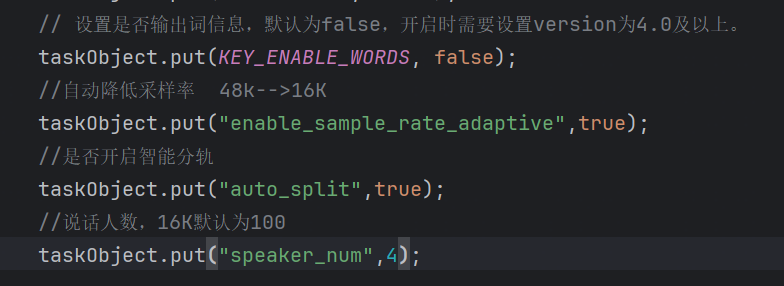
上传了48KHZ采样率的录音文件,开启了智能分轨和采样率自适应,项目配置的也是16K的采样率,但是还是无法识别多人场景
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
角色分离的话 一般建议使用1分钟以上的音频,需要代码里设置分轨的参数 需要是单声道哈,8k是两个人 16k是4 个 如果是立体声的话 分的不是角色 是声道数,需要开启智能分轨的参数:auto_split、supervise_type为2
--此回答整理自钉群“阿里语音AI【4群】”
阿里云语音AI在多人场景下的识别确实是一个挑战,因为多人同时说话会导致语音信号的重叠和混淆,增加了识别的难度。针对你提到的问题,以下是一些可能的解决策略和建议:
优化录音质量:
确保录音设备质量良好,尽量减少背景噪音和回声。
如果可能,尽量让每个说话人的声音保持一定的分离度,减少声音重叠。
使用分轨功能:
你已经开启了智能分轨功能,这是一个很好的尝试。这个功能旨在将多人语音分离成单独的轨道,从而便于识别。但请注意,智能分轨的效果会受到录音质量和多人交叠程度的影响。
检查分轨后的结果,看看是否成功地将每个人的语音分离出来。如果没有,可能需要考虑其他方法。
采样率适配:
虽然你设置了项目采样率为16K,并且开启了采样率自适应,但48KHZ到16K的降采样可能会带来一些信息损失。尽管语音AI算法会对这种损失进行补偿,但在某些情况下,原始高采样率的数据可能更有助于识别。
考虑是否可以使用与录音文件相同的采样率(如48KHZ)来进行识别。这可能需要阿里云语音AI支持更高的采样率,或者你在上传前自己进行预处理。
使用更高级的模型或API:
阿里云可能提供了不同级别的语音识别服务,有些可能针对多人场景进行了优化。了解并尝试这些更高级的服务可能有助于提高识别效果。
预处理和后处理:
在上传给阿里云之前,你可以尝试使用语音信号处理工具对录音进行预处理,如降噪、语音增强等。
在阿里云返回识别结果后,你也可以进行后处理,如使用自然语言处理(NLP)技术来纠正或完善识别结果。
联系阿里云技术支持:
如果尝试了上述方法仍然无法解决问题,建议联系阿里云的技术支持团队,他们可能能提供更具体的帮助或建议。
考虑其他解决方案:
如果阿里云语音AI无法满足你的需求,你也可以考虑其他语音识别服务提供商,或者结合使用多种技术来提高多人场景的识别效果。
请注意,语音识别技术,特别是在多人场景下,仍然是一个活跃的研究领域,持续的技术进步可能会带来更好的解决方案。

