
PolarDB的平滑扩容原理是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
PolarDB的平滑扩容原理是指在不影响业务连续性的前提下,通过增加计算节点或存储资源来提升数据库系统的处理能力和存储容量。具体来说:
在线水平扩展:
数据均衡分布:
存储扩展:
高可用性保障:
综上所述,PolarDB的平滑扩容是一个结合了计算、存储资源在线扩展与数据智能迁移的技术方案,旨在帮助用户应对不断增长的业务需求,同时确保数据库服务的稳定性和可靠性。
PolarDB的平滑扩容原理是在不中断业务的情况下,通过增加或减少计算节点来扩展或缩小数据库的处理能力。在扩容过程中,PolarDB会自动将数据重新分布到新的节点上,以保证数据的均衡分布。
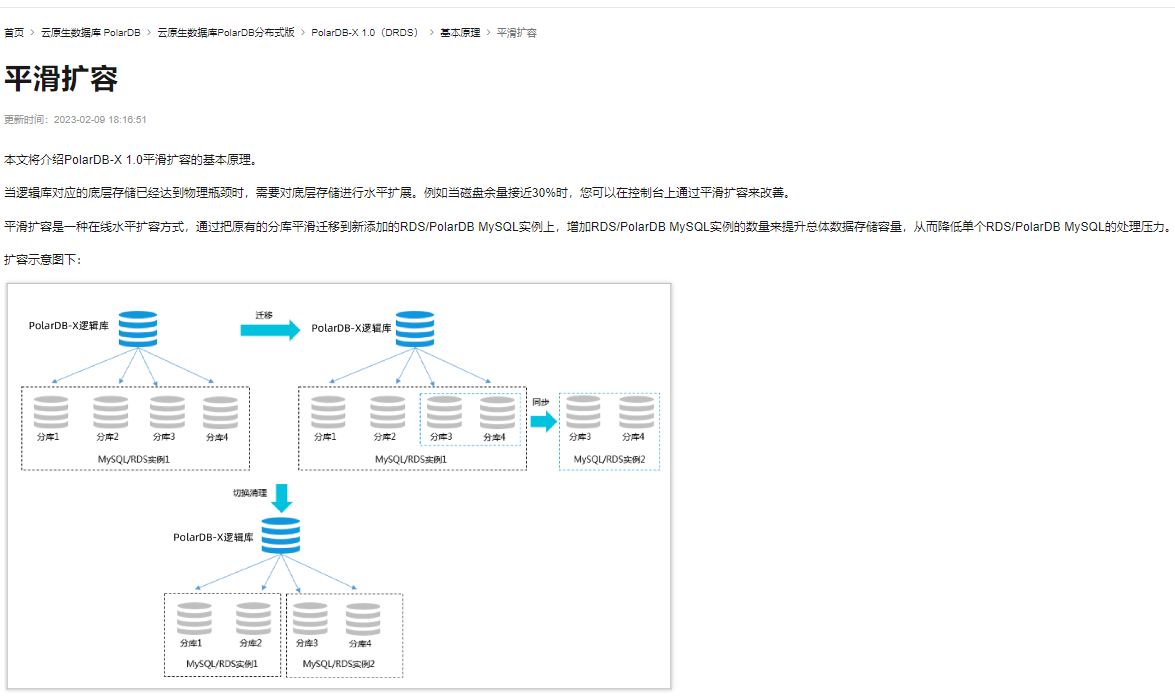
PolarDB的平滑扩容是一种在线水平扩容方式,其基本原理是通过增加RDS/PolarDB MySQL实例的数量来提升总体数据存储容量,从而降低单个RDS/PolarDB MySQL实例的处理压力。
具体来说,平滑扩容的过程主要包括以下几个步骤:
此外,PolarDB-X 1.0采用基于存储计算分离的Shared-Nothing架构,这种架构能够最大限度地发挥云数据库的弹性扩展能力。当现有实例的IOPS、CPU、磁盘容量等指标达到瓶颈时,通过水平增加实例数量来进行扩容,提升整体性能。
PolarDB的平滑扩容原理是通过增加RDS/PolarDB MySQL实例数来实现在线水平扩展,从而提升整体性能和数据存储容量。
首先,在配置阶段,需要在PolarDB分布式版数据库控制台创建扩容计划,选择新增加的RDS/PolarDB MySQL实例,并确定需要迁移到新实例上的分库。提交任务后,系统会在目标RDS/PolarDB MySQL上自动创建数据库和账号,并进行数据迁移同步的准备。
其次,全量迁移阶段,系统会选择当前时间之前的一个时间点,将这个时间点之前的数据进行全量复制迁移到新的实例上。这样做确保了数据的一致性和完整性。
再者,在增量数据同步阶段,系统会实时同步原有实例中的新增数据到新实例上,以保证数据的实时更新和同步。
最后,在切换阶段,当数据迁移和同步完成后,会将流量切换到新的实例上,以实现无缝的扩容。在清理阶段,会对旧实例中的数据进行清理,以释放资源。
此外,PolarDB-X 1.0采用基于存储计算分离的Shared-Nothing架构,这种架构使得每个节点都是独立的,可以最大限度地发挥云数据库的弹性扩展能力。当RDS的IOPS、CPU、磁盘容量等指标达到瓶颈时,通过水平扩容增加RDS数量,可以有效提升PolarDB-X数据库的整体性能。
综上所述,PolarDB的平滑扩容是一个复杂的过程,涉及到多个步骤和技术,但其核心目的是在不中断服务的情况下,通过增加实例数量来提升数据库的性能和存储能力。
PolarDB的平滑扩容原理是通过增加RDS/PolarDB MySQL实例的数量来提升总体数据存储容量。具体步骤如下:
创建扩容计划:选择新增的RDS/PolarDB MySQL实例,并选定需要迁移到新实例上的分库,提交任务后系统自动在目标实例上创建数据库和账号,并开始数据迁移同步。
全量迁移:系统选取一个时间点进行全量的数据复制迁移。
增量数据同步:完成全量迁移后,基于该时间点的增量变更日志进行实时同步,确保原分库与目标分库数据一致。
数据校验:增量同步达到准实时后,系统自动进行全数据校验并修正因同步延迟产生的不一致数据。
应用停写和路由切换:校验完成后,在业务低峰期进行应用停写(建议但非必须),然后在引擎层进行分库规则的路由切换,将流量引向新库,切换过程快速完成。
整个扩容过程中, PolarDB-X 采用存储计算分离的Shared-Nothing架构,通过水平拆分技术将数据分散到多个MySQL实例上,以实现扩展性和弹性伸缩能力。当需要进一步扩容时,可以通过在不同MySQL实例上挪动分库来增加数据库访问量和存储容量。
内容可参考如下:
阿里云关系型数据库主要有以下几种:RDS MySQL版、RDS PostgreSQL 版、RDS SQL Server 版、PolarDB MySQL版、PolarDB PostgreSQL 版、PolarDB分布式版 。


