
在AI Earth我用决策树提取出来冬小麦的区域,如何选取样本验证kappa系数和acc系数?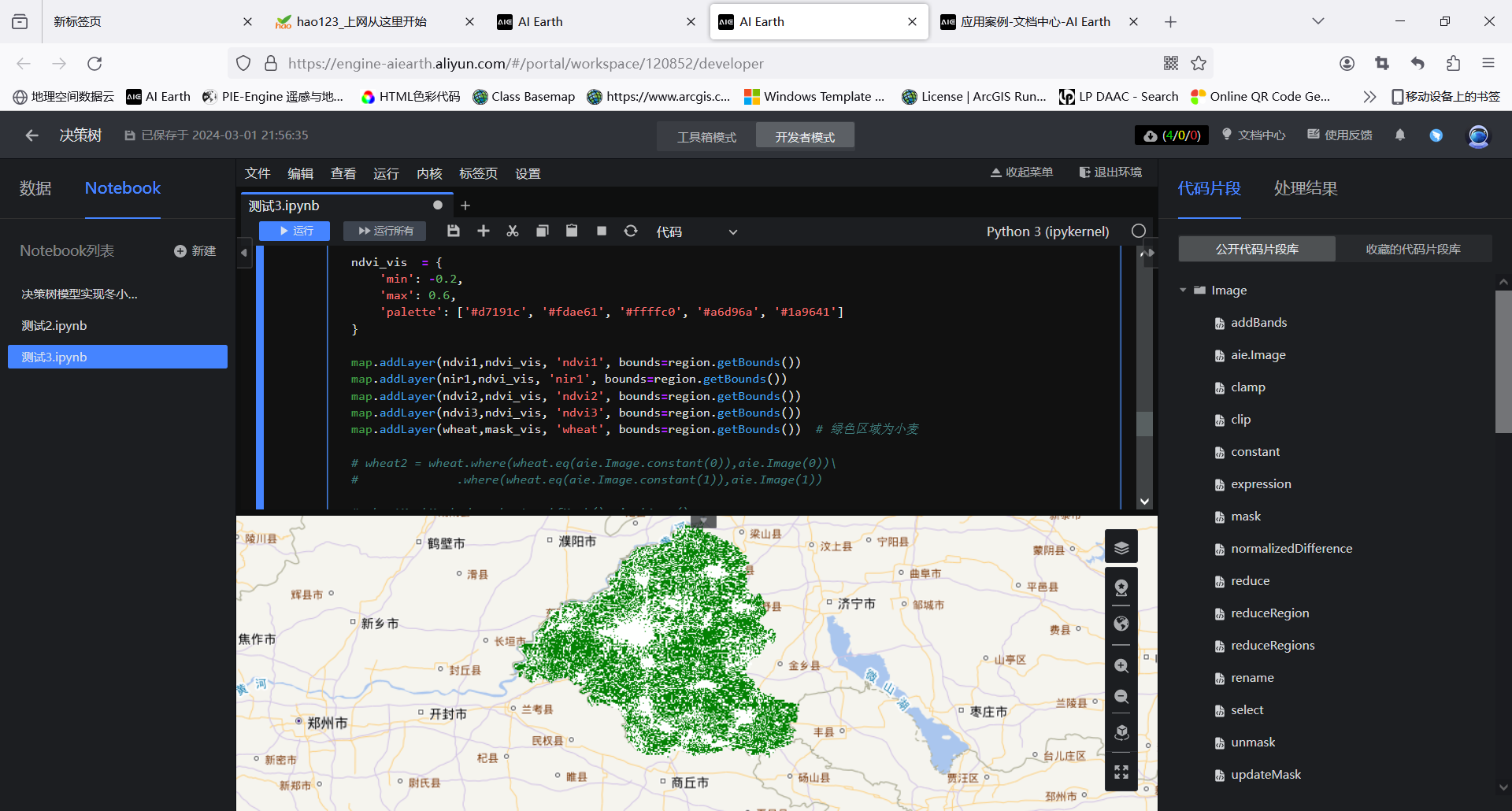
import aie
aie.Authenticate()
aie.Initialize()
feature_collection = aie.FeatureCollection('China_City') \
.filter(aie.Filter.eq('city', '菏泽市'))
region = feature_collection.geometry()
img1 = aie.ImageCollection('SENTINEL_MSIL2A') \
.filterBounds(region) \
.filterDate('2020-10-01', '2020-11-11') \
.filter(aie.Filter.lte('eo:cloud_cover',60)) \
.select(["B11","B8","B4","B3","B2"])\
.median()
# .map(removeLandsatCloud)
img2 = aie.ImageCollection('SENTINEL_MSIL2A')\
.filterDate("2021-02-01", "2021-05-11")\
.filterBounds(region)\
.filter(aie.Filter.lt('eo:cloud_cover', 60))\
.select(["B11","B8","B4","B3"])\
.median()
img3 = aie.ImageCollection('SENTINEL_MSIL2A')\
.filterDate("2021-05-30", "2021-07-5")\
.filterBounds(region)\
.filter(aie.Filter.lt('eo:cloud_cover', 60))\
.select(["B11","B8","B4","B3","B2",])\
.median()
red1 = img1.select("B4")
nir1 = img1.select("B8")
swir1 = img1.select("B11")
red2 = img2.select("B4")
nir2 = img2.select("B8")
red3 = img3.select("B4")
nir3 = img3.select("B8")
ndvi1 = (nir1.subtract(red1)).divide(nir1.add(red1)).rename(["NDVI"]).select("NDVI")
nbr1 = (nir1.subtract(swir1)).divide(nir1.add(swir1)).rename(["NBR"]).select("NBR")
ndvi2 = (nir2.subtract(red2)).divide(nir2.add(red2)).rename(["NDVI"]).select("NDVI")
ndvi3 = (nir3.subtract(red3)).divide(nir3.add(red3)).rename(["NDVI"]).select("NDVI")
wheat = ndvi1.lt(aie.Image.constant(0.3))\
.And(nbr1.lt(aie.Image.constant(0.07)))\
.And(ndvi2.gt(aie.Image.constant(0.32)))\
.And(ndvi3.lt(ndvi2))\
.clip(region)
map = aie.Map(
center=region.getCenter(),
height=800,
zoom=7
)
vis_params = {
'color': '#00FF00'
}
map.addLayer(
region,
vis_params,
'region',
bounds=region.getBounds()
)
mask_vis = {
'min': 0,
'max': 1,
'palette': ['#ffffff', '#008000'] # 0:白色, 1:绿色
}
ndvi_vis = {
'min': -0.2,
'max': 0.6,
'palette': ['#d7191c', '#fdae61', '#ffffc0', '#a6d96a', '#1a9641']
}
map.addLayer(ndvi1,ndvi_vis, 'ndvi1', bounds=region.getBounds())
map.addLayer(nir1,ndvi_vis, 'nir1', bounds=region.getBounds())
map.addLayer(ndvi2,ndvi_vis, 'ndvi2', bounds=region.getBounds())
map.addLayer(ndvi3,ndvi_vis, 'ndvi3', bounds=region.getBounds())
map.addLayer(wheat,mask_vis, 'wheat', bounds=region.getBounds()) # 绿色区域为小麦
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在AI Earth中,您可以使用以下步骤来选取样本并验证决策树提取冬小麦区域的kappa系数和acc系数:
总的来说,在进行这一过程时,请确保您的样本集具有代表性,并且覆盖了不同的物候期和光谱特征,以便能够准确地验证模型的性能。同时,注意数据的预处理和云去除等步骤,以提高模型的准确性。
在AI Earth中,您可以通过以下步骤来选取样本并验证决策树分类结果的Kappa系数和Accuracy系数:
请注意,这个过程可能需要一定的遥感知识和数据分析技能。如果您不熟悉这些步骤,可能需要进一步学习相关的遥感技术和统计分析方法。
看了你的代码,并不是使用平台 classifier 里面的API 函数来完成你的决策树。你只是拼接了一些函数来完成。如果你能知道正确分类的数量(在pixel 或者 object 这个级别)。那么你可以构建ConfusionMatrix,来计算 Kappa 系数等。具体混淆矩阵如何构建可参考文档中心—>API 参考里面的具体说明。此回答整理自钉群“AI Earth地球科学云平台交流群”
将原始数据集划分为训练集和测试集/验证集。常用的划分方法包括随机划分、交叉验证(如K折交叉验证)或者时间序列上的留出法(对于时间序列数据)。
使用训练好的模型对验证集进行预测,得到模


