
flink cdc读取pg时报这个错有遇到过吗?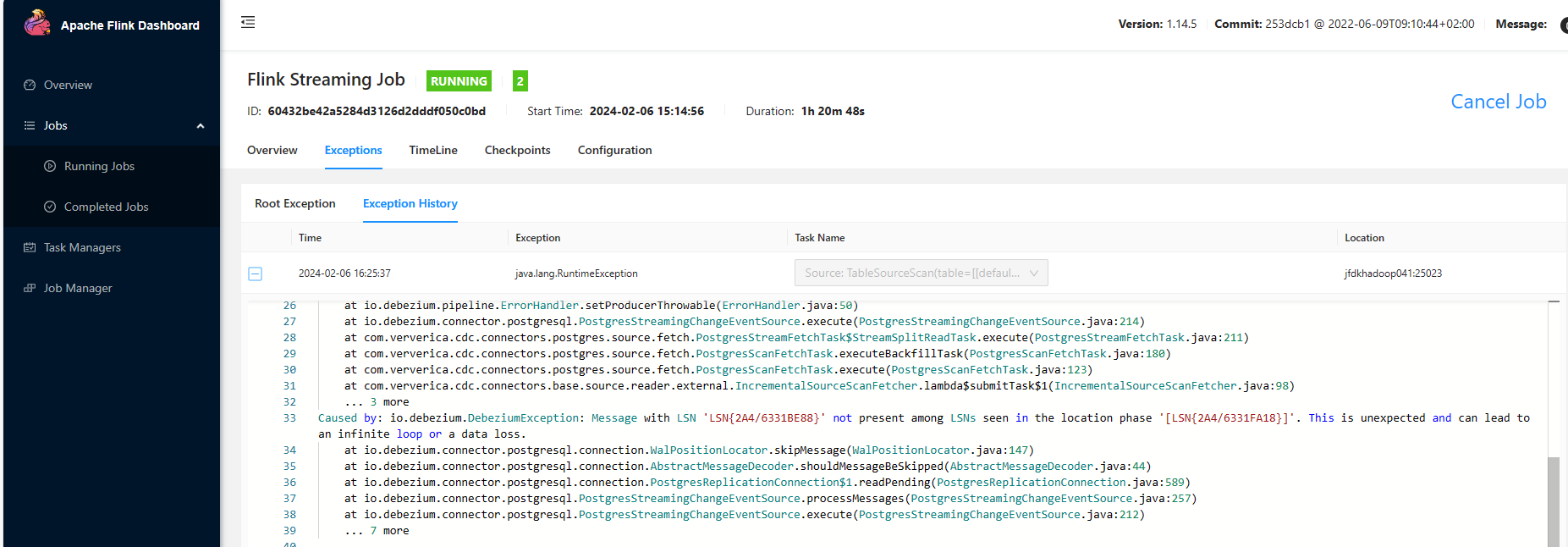
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink CDC读取PostgreSQL(PG)时,如果遇到错误,首先需要明确具体的错误信息。根据知识库中的相关资料,以下是一些可能的原因及解决方案:
Flink CDC 2.4.0版本不支持从PostgreSQL的备库读取增量数据,因为PostgreSQL本身也不支持备库读取增量数据。
解决方法:
确保Flink CDC连接的是PostgreSQL的主库,而不是备库。
Postgres CDC连接器通过发送心跳包来推进Slot的偏移量。如果表变更不频繁,可能会导致WAL日志无法及时回收,从而引发错误。
相关参数:
- heartbeat.interval.ms:发送心跳包的时间间隔,默认值为30秒(30s)。
解决方法:
检查并调整heartbeat.interval.ms参数,确保其值适合当前业务场景。例如,可以将其设置为更短的时间间隔(如10秒)以避免WAL日志堆积。
在Postgres CDC中,全量阶段和增量阶段的日志读取可能会引发一致性问题。如果跳过全量阶段日志读取(scan.incremental.snapshot.backfill.skip=true),可能会导致仅提供至少一次(At-Least Once)的语义保证。
相关参数:
- scan.incremental.snapshot.backfill.skip:是否跳过全量阶段的日志读取,默认值为false。
解决方法:
- 如果下游算子或存储支持幂等性,可以考虑跳过全量阶段日志读取以减少WAL Slot数量。 - 如果SQL涉及聚合、关联等操作,建议不要跳过全量阶段日志读取。
即使Flink和PostgreSQL之间的网络是连通的,仍可能出现timeout expired while fetching topic metadata类似的错误。这可能是由于PostgreSQL返回的Endpoint信息中包含无法解析的域名或IP地址。
解决方法:
1. 检查PostgreSQL的listener_security_protocol_map配置,确认返回的Endpoint是否可被Flink访问。 2. 如果Endpoint中使用了域名,请为Flink配置对应的域名解析服务。
conflictMode参数来处理冲突。
conflictMode=strict:冲突时报错(默认值)。conflictMode=ignore:冲突时忽略。conflictMode=update:冲突时自动更新。cache)可能会影响数据读取效率。建议根据业务需求选择合适的缓存策略(如ALL、LRU或None)。根据上述分析,您可以按照以下步骤排查和解决问题: 1. 确保Flink CDC连接的是PostgreSQL的主库,而非备库。 2. 检查并调整heartbeat.interval.ms参数,避免WAL日志堆积。 3. 根据业务需求,合理配置全量阶段和增量阶段的日志读取策略。 4. 检查网络连通性,确保Flink能够访问PostgreSQL返回的Endpoint。 5. 调整冲突处理策略(conflictMode)和缓存策略(cache),以适配具体业务场景。
如果问题仍未解决,请提供具体的错误信息以便进一步分析。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

