
请问下大数据计算MaxCompute,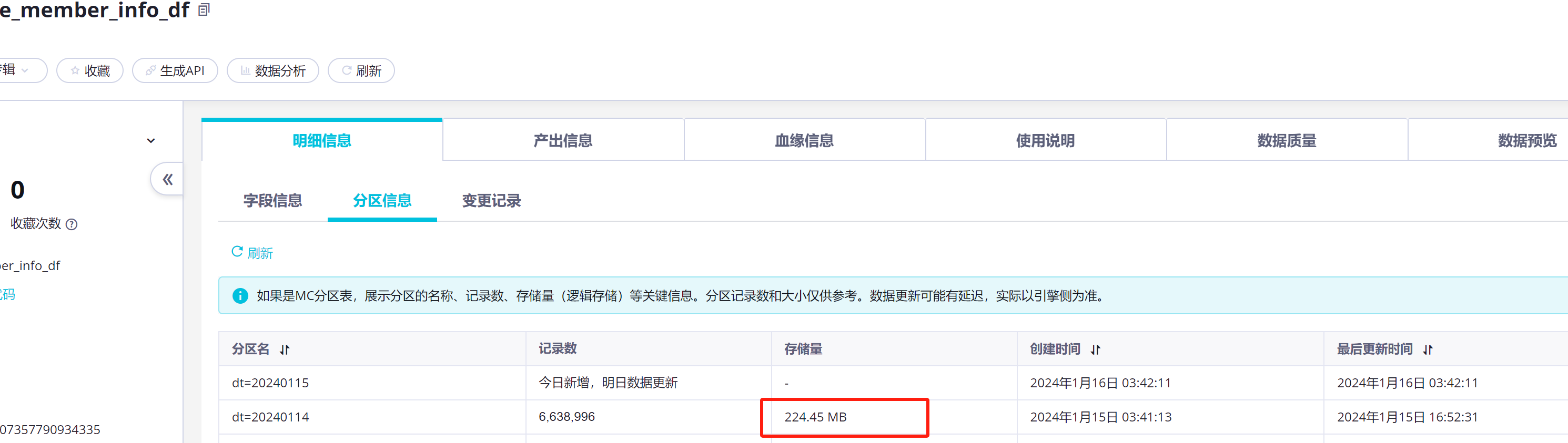
我这个表只有224M的数据,我用这个方法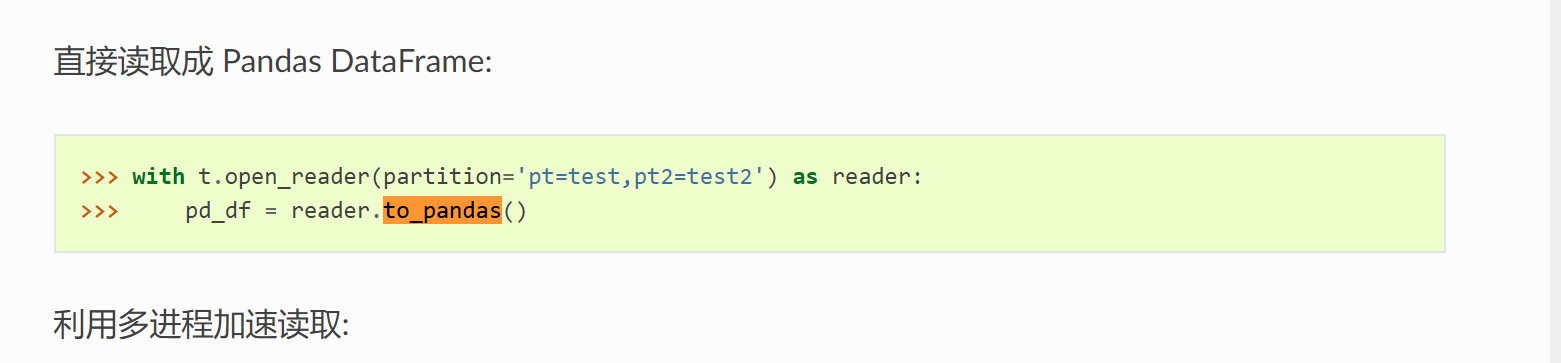
读取出来却超过我的内存(8G内存)大小了喃?这是怎么回事啊?
我改了一种读取方式,能获取到logview了
但我看logview是没问题的,现在问题出在这个reader.to_pandas(),因为数据很大,超过内存(8G)了,直接就被Linux给killed了,这个表这个分区我看又只有224M数据,但读取出来为啥这么大,这个压缩比到底是多少哦?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在MaxCompute中读取数据超过内存大小可能是由于数据量过大或内存分配不足导致的。
为了解决这个问题,可以采取以下几个措施:
odps.stage.mapper.mem、odps.stage.reducer.mem和odps.stage.joiner.mem等参数来增加每个任务的内存限制。例如,使用命令set odps.stage.mapper.split.size=256;可以调整每个Mapper读取数据的大小为256 MB。ExecutionContext.claimAlive来重置计时器,避免因长时间占用CPU资源而被系统限制。需要注意的是,在进行这些调整时,应该根据实际情况和系统的限制来进行,避免过度消耗资源或超出系统的限制。同时,也需要考虑到成本和效率的平衡,确保资源的合理利用。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


