Flink CDC在DataStream 可以用redis来缓存维表。。。在flink sql中,有办法实现这个功能吗?Lookup Join 不知道怎么去用redis缓存,还有更新缓存?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
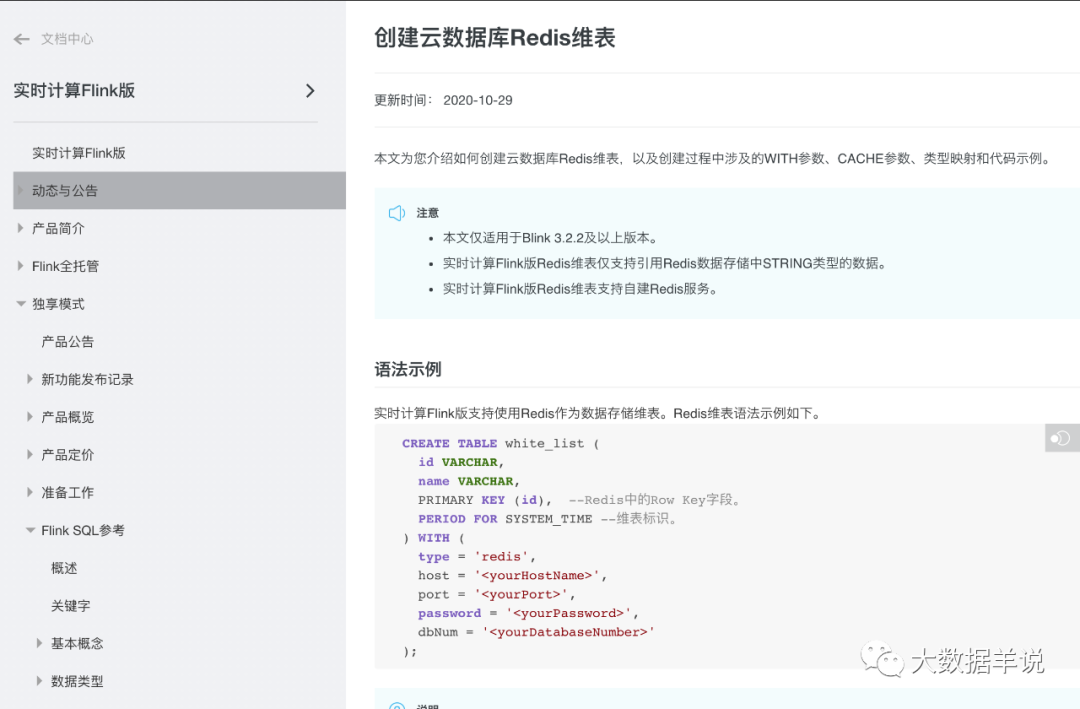
在 Flink SQL 中,可以使用 Redis 作为维表的缓存来优化查询性能。具体来说,可以使用 Lookup Join 来实现这个功能。
Lookup Join 是一种常见的连接方式,用于将两个流或数据集进行关联。在 Flink SQL 中,可以使用 Lookup Join 来将一个流或数据集与另一个流或数据集进行关联,并将结果输出到一个新的流或数据集中。
对于使用 Redis 作为维表缓存的情况,可以按照以下步骤实现:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
TableEnvironment tableEnv = TableEnvironment.create(env);
RedisConfig config = new RedisConfig.Builder()
.setHost("localhost")
.setPort(6379)
.build();
RedisSink<String> sink = new RedisSink<>(config, new MyRedisFunction());
tableEnv.registerTableSource("redis", sink);
Table factTable = tableEnv.fromDataStream(inputStream, "fact");
Table dimensionTable = tableEnv.sqlQuery("SELECT * FROM redis");
Table resultTable = factTable.join(dimensionTable).where("fact.id = dimension.id");
在这个例子中,inputStream 是输入流的名称,fact 和 dimension 分别是事实表和维表的字段名称。"SELECT * FROM redis" 是从 Redis 中读取数据并创建维表的 SQL 语句。fact.id = dimension.id 是关联条件。
class MyRedisFunction implements SinkFunction<Tuple2<String, String>> {
private Jedis jedis;
private String key;
private String value;
private long expirationTime;
// ...构造函数和其他方法...
@Override
public void open(Configuration parameters) throws Exception {
this.jedis = new Jedis(new RedisURI("redis://localhost:6379"));
this.key = "my_key";
this.value = "my_value";
this.expirationTime = System.currentTimeMillis() + 3600L; // 缓存过期时间为1小时
}
@Override
public void invoke(Tuple2<String, String> value, Context context) throws Exception {
jedis.setex(key, expirationTime, value.f1); // 将值存储到 Redis 中,并设置过期时间
}
@Override
public void close() throws Exception {
jedis.close(); // 关闭 Jedis 连接池
}
}
在这个例子中,MyRedisFunction 是一个实现了 SinkFunction 接口的类,它负责将数据写入到 Redis 中。在 open 方法中,需要初始化 Jedis 连接池、键名、值和过期时间等参数。在 invoke 方法中,需要将值存储到 Redis 中,并设置过期时间。在 close 方法中,需要关闭 Jedis 连接池。
Flink SQL 支持维表(lookup join)操作,这是一种将流数据与静态或缓慢变化的维度表进行连接的方式。虽然 Flink SQL 直接支持 Redis 作为维表存储引擎的可能性较小,但可以通过以下方法实现:
使用 Flink DataStream API:
在 Flink 的 DataStream API 中,可以使用异步 I/O 实现 Redis 维表 join。这种方法允许在 Flink 应用中直接访问 Redis,并控制缓存和更新策略。
结合 Flink Table API 和 User Defined Functions (UDFs):
尽管 Flink SQL 不直接支持 Redis 缓存,但可以通过在 Table API 中使用自定义函数来间接实现。首先,在 Table API 中创建一个 UDF,该 UDF 使用 Redis 客户端库来查询和更新 Redis。然后,你可以将这个 UDF 用于 Flink SQL 查询中的维表 join 操作。
使用外部系统:
另一种方法是使用一个外部系统(如 Apache Kafka 或 RabbitMQ)来管理维度表的变化,并将这些变化事件传递给 Flink SQL 应用程序。这样,你可以在 Flink SQL 中处理这些变化事件,并相应地更新本地缓存的维度表。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。