
请问这个英语预处理的包如何得到?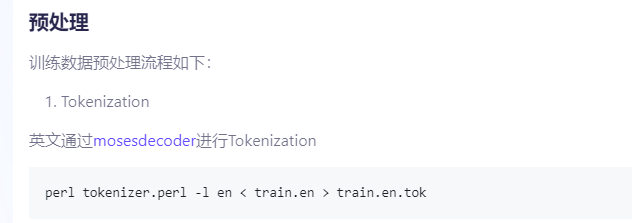
我从github下载了对应的文件,仍然报错
在ModelScope中,如果你需要使用英语预处理的包,你可以直接下载已经预处理好的数据集。这些数据集通常包含分词、去停用词、词干提取等预处理步骤的结果。
你可以在ModelScope的数据集中找到这些预处理过的数据集。在数据集的页面,你会看到一个"Data Preview"按钮,点击后可以查看数据集的内容。如果数据集已经包含了预处理的结果,那么在"Data Preview"中,你应该可以看到每个样本都已经经过了预处理。
如果你需要自己进行预处理,你可以参考相关的教程和文档。例如,你可以参考NLTK、spaCy等自然语言处理库的教程,了解如何进行文本的分词、去停用词、词干提取等预处理步骤。

