
ModelScope中,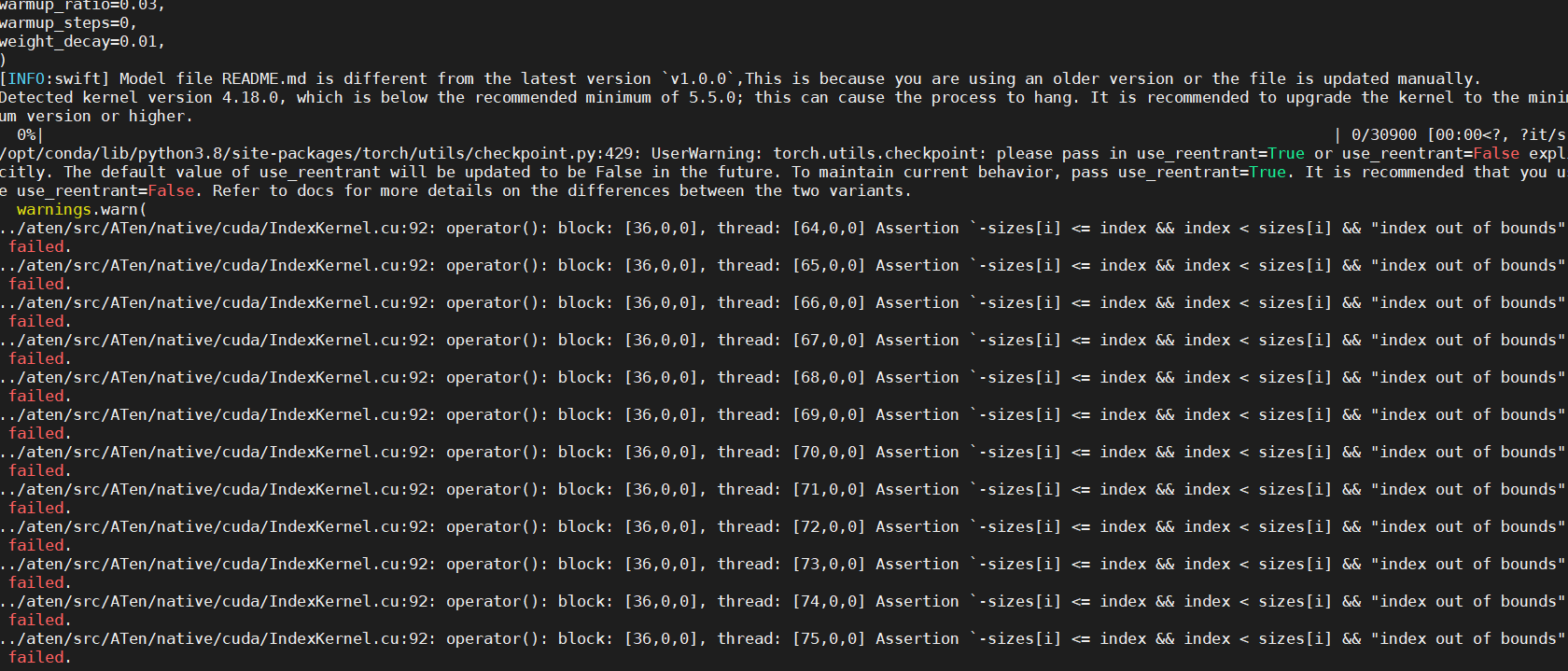 ../aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [36,0,0], thread: [64,0,0] Assertion
../aten/src/ATen/native/cuda/IndexKernel.cu:92: operator(): block: [36,0,0], thread: [64,0,0] Assertion -sizes[i] <= index && index < sizes[i] && "index out of bounds" failed 这样的报错有大佬遇到过没?
DDP-DS 2卡的
这个报错信息表示在运行一个深度学习模型时,发生了索引越界的错误。具体来说,错误发生在IndexKernel.cu文件的第92行,涉及到一个名为sizes的数组。报错信息中提到了sizes[i]和index的值,以及一个断言条件sizes[i] <= index && index < sizes[i]。
这个报错通常发生在使用分布式数据并行(DDP)训练深度学习模型时,特别是在多GPU环境下。在这种情况下,每个进程都有自己的数据集切片,这些切片的大小可能不同。当某个进程试图访问其数据集切片之外的数据时,就会发生索引越界的错误。
要解决这个问题,你可以尝试以下方法:
检查你的代码,确保在访问数据集切片时没有越界。特别是要注意sizes数组的值是否正确,以及index是否在有效范围内。
如果问题仍然存在,尝试减小批量大小(batch size),以减少每个进程需要处理的数据量。这可能会降低训练速度,但可以防止索引越界错误。
如果上述方法都无法解决问题,可以考虑使用其他分布式训练框架,如Horovod或MegEngine,它们可能对这种情况有更好的支持。
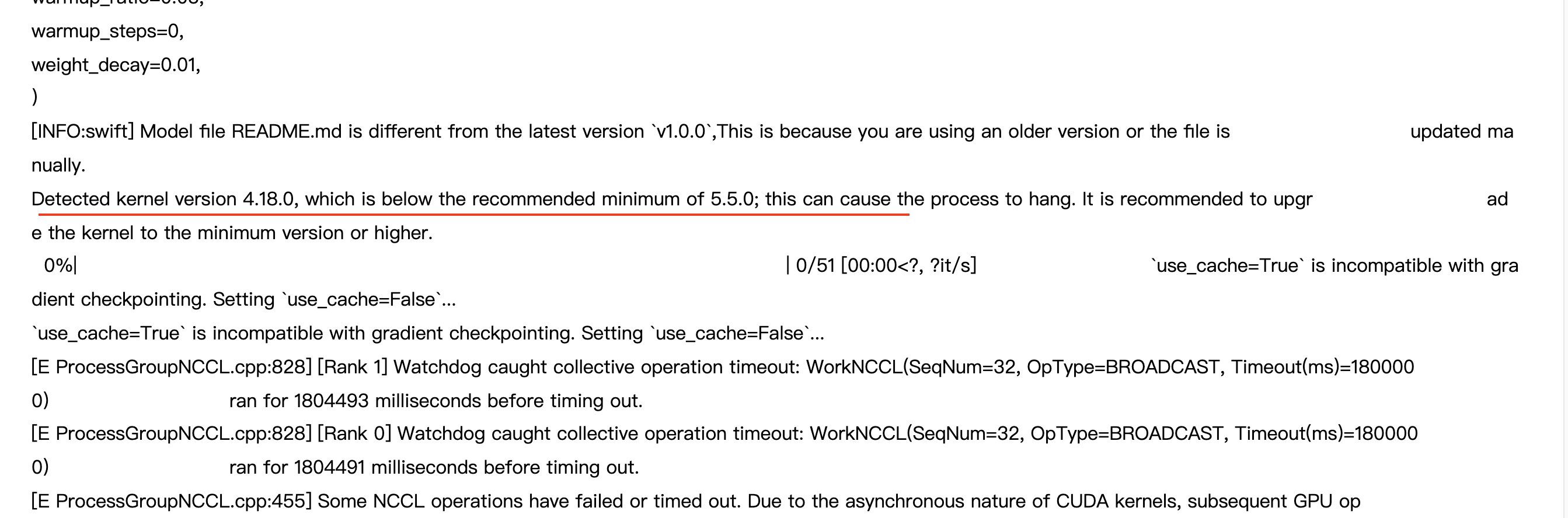
您先看一下这里的kernel日志从这里开始不一样了,会不会是和这个有关。我这找一下。
双卡没问题swift/examples/pytorch/llm/scripts/openbuddy_mistral_7b_chat/lora_ddp_ds/sft.sh 中,--max_length 8192 其余未改动。期间报错:AttributeError: 'FieldInfo' object has no attribute 'required'。pip install deepspeed之后,训练可以正常跑起来,如下: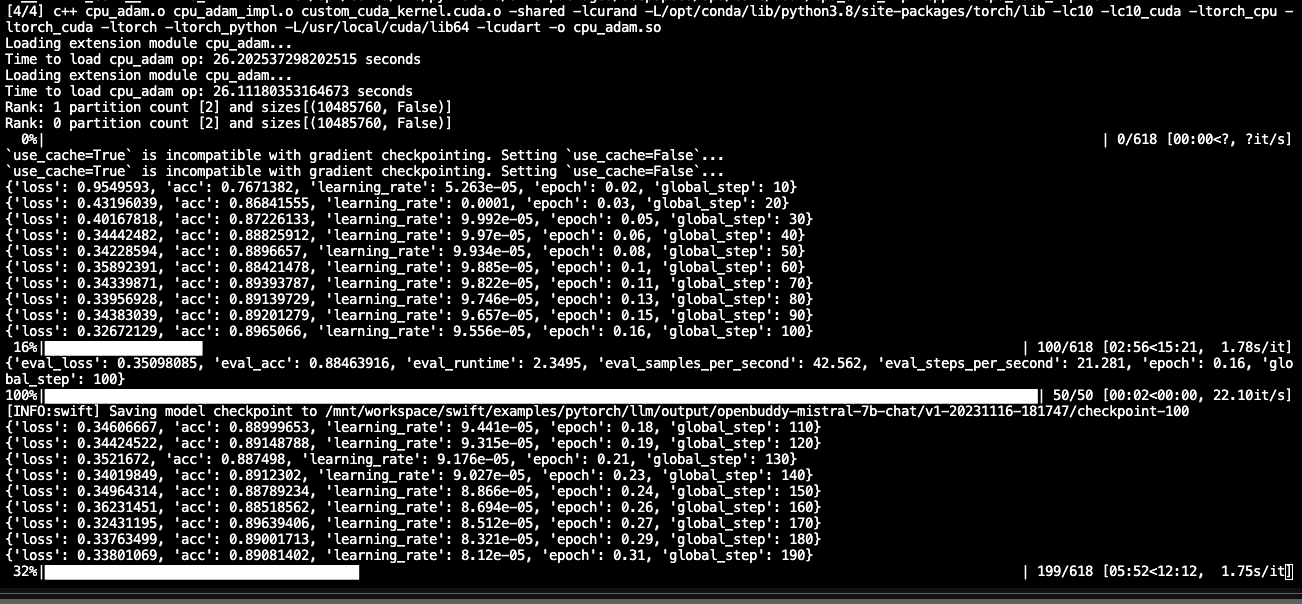
显存占用每张卡约18G镜像registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.5——此回答整理自钉群:魔搭ModelScope开发者联盟群 ①

