
ModelScope中,我使用的本地微调好的模型跑的 跑不通 ,但是fastchat可以跑通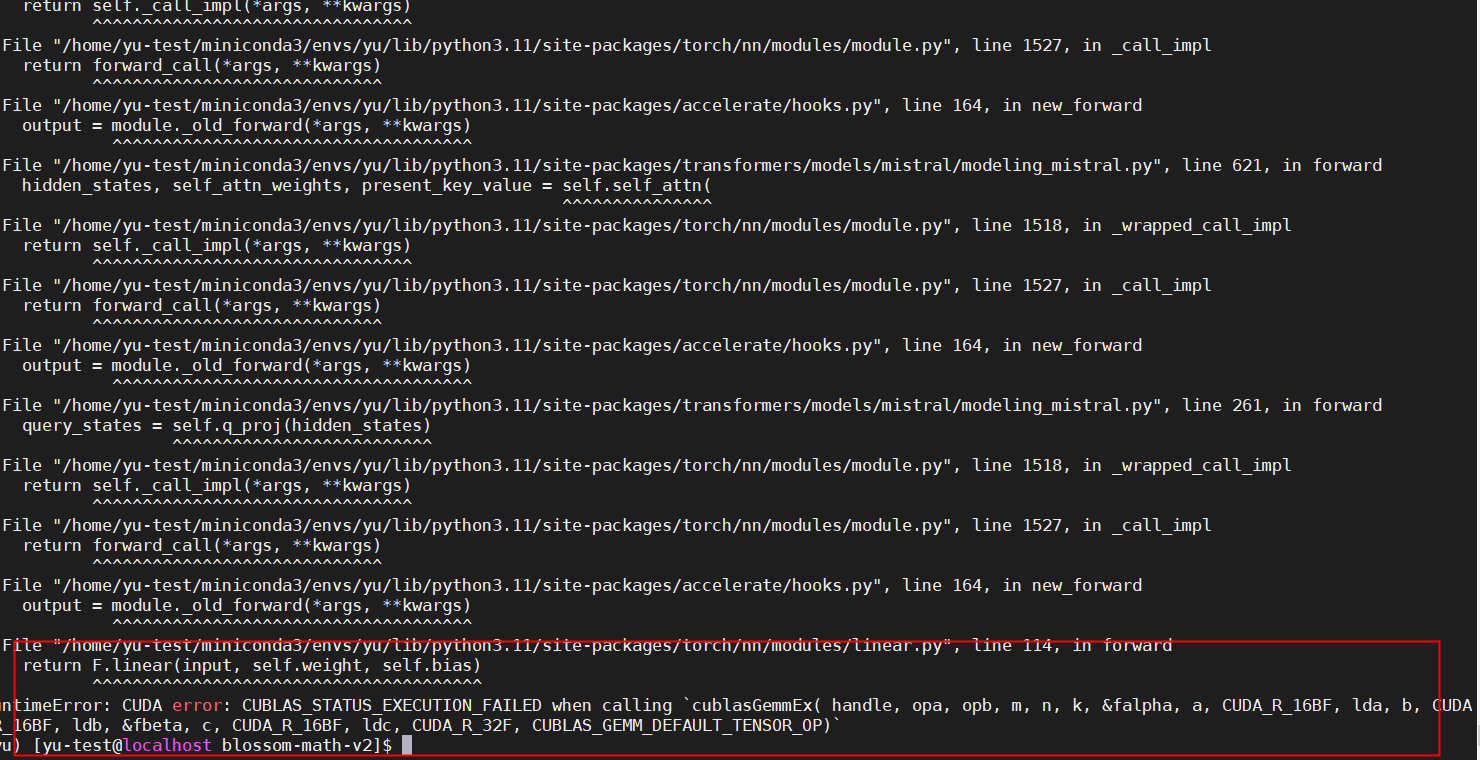 2023-11-13 02:43:37,300 - modelscope - INFO - PyTorch version 2.1.0 Found.
2023-11-13 02:43:37,300 - modelscope - INFO - PyTorch version 2.1.0 Found.
2023-11-13 02:43:37,301 - modelscope - INFO - Loading ast index from /home/yu-test/.cache/modelscope/ast_indexer
2023-11-13 02:43:37,330 - modelscope - INFO - Loading done! Current index file version is 1.9.4, with md5 ee6d385e991d568a514305f0011803d8 and a total number of 945 components indexed
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:09<00:00, 4.51s/it]
Both max_new_tokens (=2048) and max_length(=256) seem to have been set. max_new_tokens will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/transformers/generation/utils.py:1539: UserWarning: You are calling .generate() with the input_ids being on a device type different than your model's device. input_ids is on cpu, whereas the model is on cuda. You may experience unexpected behaviors or slower generation. Please make sure that you have put input_ids to the correct device by calling for example input_ids = input_ids.to('cuda') before running .generate().
warnings.warn(
Traceback (most recent call last):
File "/data1/swift/examples/pytorch/llm/blossom-math-v2/resume_pipeline.py", line 24, in
outputs = model.generate(inputs, max_length=256)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/transformers/generation/utils.py", line 1652, in generate
return self.sample(
^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/transformers/generation/utils.py", line 2734, in sample
outputs = self(
^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/accelerate/hooks.py", line 164, in new_forward
output = module._old_forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/transformers/models/mistral/modeling_mistral.py", line 1045, in forward
outputs = self.model(
^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/ yu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/transformers/models/mistral/modeling_mistral.py", line 932, in forward
layer_outputs = decoder_layer(
^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/accelerate/hooks.py", line 164, in new_forward
output = module._old_forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/transformers/models/mistral/modeling_mistral.py", line 621, in forward
hidden_states, self_attn_weights, present_key_value = self.self_attn(
^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/accelerate/hooks.py", line 164, in new_forward
output = module._old_forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/transformers/models/mistral/modeling_mistral.py", line 261, in forward
query_states = self.q_proj(hidden_states)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/accelerate/hooks.py", line 164, in new_forward
output = module._old_forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/yu-test/miniconda3/envs/yu/lib/python3.11/site-packages/torch/nn/modules/linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling cublasGemmEx( handle, opa, opb, m, n, k, &falpha, a, CUDA_R_16BF, lda, b, CUDA_R_16BF, ldb, &fbeta, c, CUDA_R_16BF, ldc, CUDA_R_32F, CUBLAS_GEMM_DEFAULT_TENSOR_OP)
从错误信息来看,这是一个CUDA相关的错误。这个错误可能是由于模型和GPU之间的数据类型不匹配导致的。你可以尝试将模型的输入数据转换为与GPU相同的数据类型,然后再进行预测。
首先,你需要检查模型的设备类型:
print(model.device)
如果模型在GPU上,确保你的输入数据也在GPU上。你可以使用to()方法将输入数据转移到GPU上:
inputs = inputs.to(model.device)
然后再次尝试运行模型:
outputs = model.generate(inputs, max_length=256)
transformers版本您看一下和您的版本一样,先不改动模型卡片推理代码,您试一下能不能跑通。——此回答整理自钉群:魔搭ModelScope开发者联盟群 ①

