
问题一:ModelScope中,请问Qwen-14B-Chat-Int4的这个示例在多卡服务器上跑需要设置什么吗?这边一直卡在加载模型跑不下去呢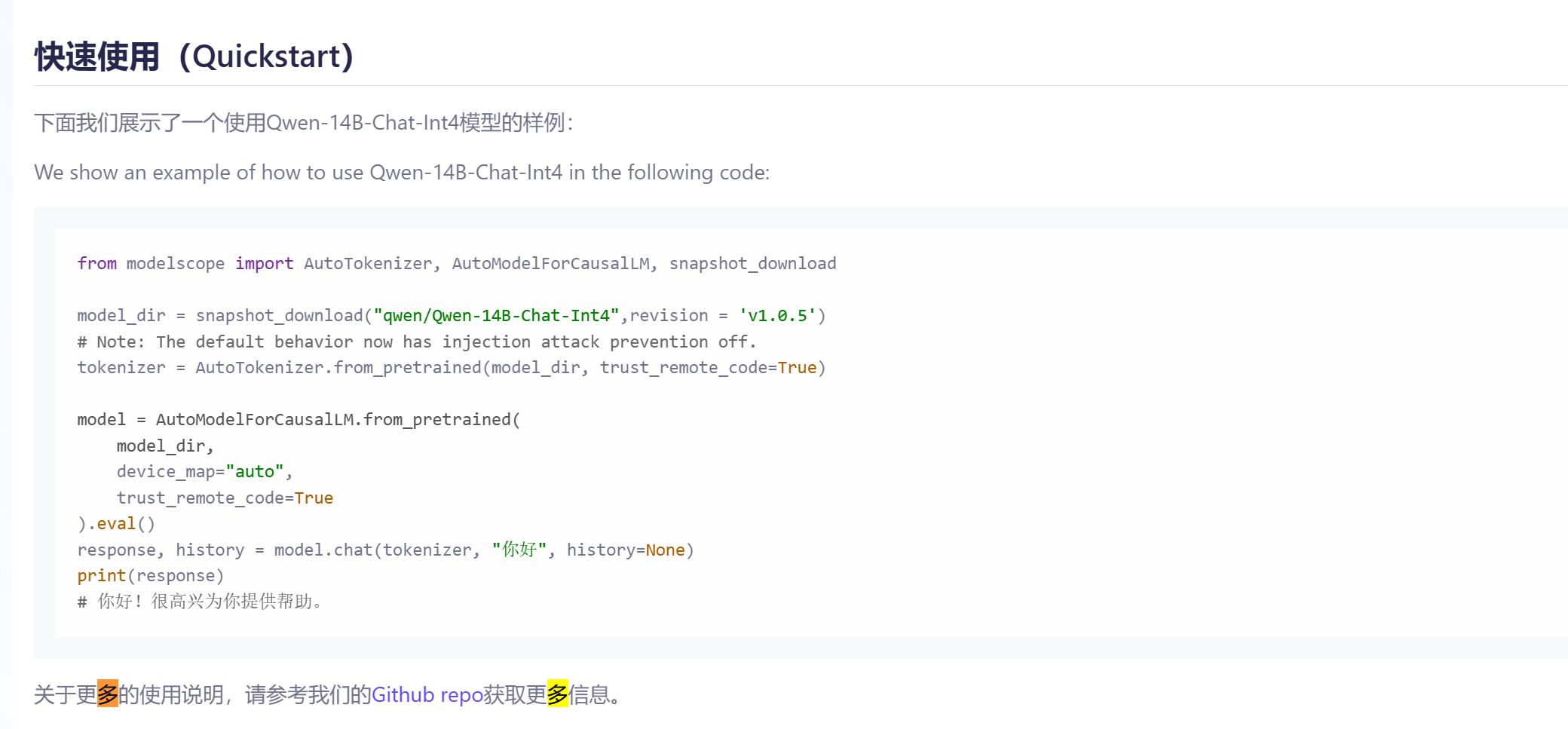 问题二;可以指定多卡服务器的其中一直卡吗?我改了device_map='cuda:0',跑到cpu去了而且也是卡在加载模型跑不下去
问题二;可以指定多卡服务器的其中一直卡吗?我改了device_map='cuda:0',跑到cpu去了而且也是卡在加载模型跑不下去
问题一:对于ModelScope中的Qwen-14B-Chat-Int4示例,如果你在多卡服务器上运行时遇到问题,首先你需要确保你的服务器上的CUDA和cuDNN版本与模型要求的版本相符。其次,你需要确保你的服务器上的PyTorch版本与模型要求的版本相符。此外,你还需要确保你的服务器上的Python版本与模型要求的版本相符。最后,你需要确保你的服务器上的其他依赖库(如transformers、torchtext等)的版本与模型要求的版本相符。
问题二:在PyTorch中,你可以通过设置torch.device(device_map)来指定使用的设备。device_map应该是一个字符串,表示你想要使用的设备的名称。例如,如果你想使用第一台GPU设备,你可以设置device_map='cuda:0'。如果你想使用第二台GPU设备,你可以设置device_map='cuda:1',以此类推。
然而,需要注意的是,如果你的服务器上的所有GPU设备都被其他进程占用,那么你可能无法使用这些设备。此外,如果你的服务器上的GPU设备不支持你所需要的功能(如FP16计算),那么你也无法使用这些设备。
如果你的代码在指定了设备后仍然无法运行,那么可能是你的代码中存在其他问题。在这种情况下,你可能需要检查你的代码,看看是否存在其他错误。
针对问题一的回答:多卡还不支持叭,notebook免费实例您试一下,可以跑的。针对问题二的回答:device_map改成device。——此回答整理自钉群:魔搭ModelScope开发者联盟群 ①

