
NLP自学习平台命名实体识别支持训练自己的模型吗?输入黑色 iphone 14promax将14 标注成了型号pro和 max识别不出来,标注成了普通词,请问没识别出来是因为不支持中英文混合吗,还是因为没有训练过类似的数据?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
你好,可以试用下灵积平台的OpenNLU服务
https://help.aliyun.com/zh/dashscope/developer-reference/opennlu-api-details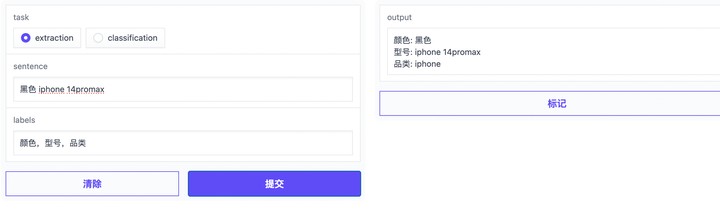
此回答整理自钉群“阿里云NLP基础服务2.0 - 用户答疑群”
命名实体识别(Named Entity Recognition,NER)是自然语言处理(NLP)的一个重要任务,主要用于识别文本中的实体,如人名、地名、组织名等。大多数NLP平台都支持训练自己的模型来进行命名实体识别。
关于你的问题,可能是因为模型没有训练过类似的中英文混合数据,导致它在处理这种类型的数据时表现不佳。此外,也可能是因为模型在处理中文和英文混合的文本时存在一些困难。
为了解决这个问题,你可以尝试以下几种方法:
增加训练数据:你可以收集更多的包含中英文混合的命名实体识别数据,并使用这些数据来训练你的模型。这样,模型就可以学习到如何处理这种类型的数据了。
调整模型参数:你可以尝试调整模型的参数,如学习率、批次大小等,看看是否可以提高模型的性能。
使用预训练模型:你可以尝试使用一些预训练的模型,如BERT、RoBERTa等,这些模型在大规模数据上进行了预训练,可能在处理各种类型的文本时表现更好。
使用多语言模型:一些多语言模型,如mBERT、XLM-R等,可以在多种语言上进行训练,可能更适合处理中英文混合的文本。
人工干预:对于一些难以自动识别的实体,你可能需要进行人工干预,手动进行标注,然后再用这些数据进行模型训练。

