
DataWorks如何同步任务动态分区?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,您可以使用同步任务动态分区功能来实现按照分区键将数据动态同步到目标数据源的分区中。首先,创建一个同步任务节点用于读取MaxCompute表的数据,并配置源表和目标表的信息。源表是MaxCompute表,而目标表可以是另一个MaxCompute表或其他目标存储位置。
为了同步多个分区的数据,您可以在同步任务节点的参数中设置分区变量。然后,为了按分区参数同步数据,可以在循环节点内部放置一个同步任务节点,并使用分区参数来动态指定要同步的分区。
此外,如果需要自动创建分区,例如将RDS中的数据定时每天同步到MaxCompute中,可以设置自动创建按天日期的分区。完成所有配置项的填写后,保存任务的配置,然后执行同步任务即可。
单表实时同步写入到MaxCompute支持根据来源字段内容动态分区;
离线同步任务不支持动态分区,但是可以通过增量同步的方式来实现动态分区,比如源端mysql通过where过滤出update_time为20221010的数据,写入到目标odps表20221010的分区。
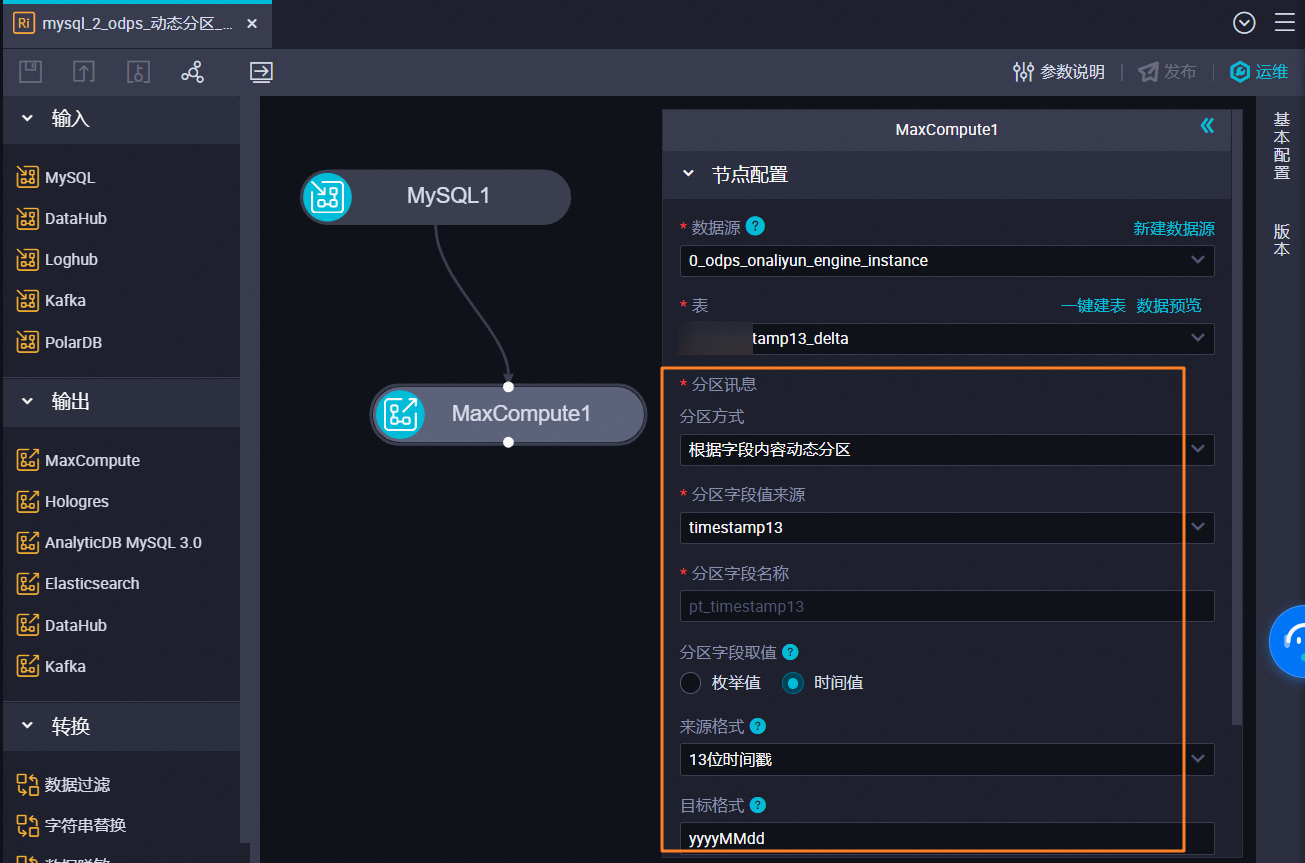
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在DataWorks中,"同步任务动态分区"是一种用于在任务执行过程中根据特定规则生成和使用分区的机制。它允许你根据数据的特性和需求,以动态方式创建和操作分区。
您可以在DataWorks中设置同步任务的源表和目标表,以及用于执行同步任务的资源组。首先,选择同步的源表区域,为您展示所选数据源下所有的表,您可以在源端库表区域选中需要同步的整库全表或部分表,并单击图标,将其移动至已选库表。如果选中的表没有主键,将无法进行实时同步。然后,选择目标MaxCompute(ODPS)数据源和写入模式。
在设置目标表时,您可以选择离线同步任务的数据来源和数据去向,以及用于执行同步任务的资源组,并测试连通性。此外,DataWorks还支持同步源端分库分表数据至目标单表。
在DataWorks中,你可以使用动态分区来同步任务,以实现对数据的实时处理。以下是一些可能的方法:
在DataWorks中,可以通过以下方式同步任务的动态分区:
需要注意的是,在使用动态分区时,需要确保任务的执行频率足够快,以保证数据同步的及时性。此外,还需要考虑数据量的问题,确保任务的执行时间和内存消耗在可接受的范围内。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


