
-

在数据源管理页面,单击左上角的图标,选择全部产品 > 数据集成。单击首页中的新建同步任务。在新建节点对话框中,输入节点名称并选择目标文件夹,单击提交。进入离线同步节点的配置页面,选择数据来源。
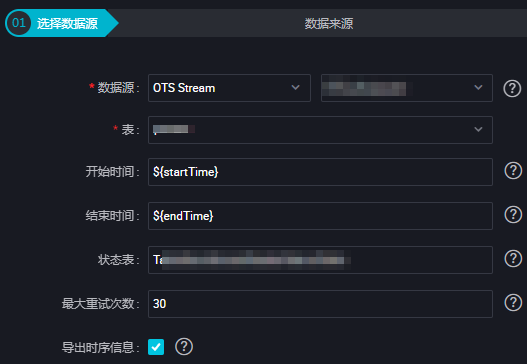
参数 描述
数据源 输入数据源的名称。
表 导出增量数据的表的名称。该表需要开启Stream,您可以在建表时开启,或使用UpdateTable接口开启。
开始时间 增量数据的时间范围(左闭右开)的左边界,格式为yyyymmddhh24miss,单位为毫秒。
结束时间 增量数据的时间范围(左闭右开)的右边界,格式为yyyymmddhh24miss,单位为毫秒。
状态表 用于记录状态的表的名称。
最大重试次数 从TableStore中读增量数据时,每次请求的最大重试次数,默认是30。
导出时序信息 是否导出时序信息,包括数据的写入时间等信息。选择数据去向。参数 描述
数据源 输入配置的数据源名称。
表 选择需要同步的表。
分区信息 此处需同步的表是非分区表,所以无分区信息。
清理规则
空字符串作为null 默认值为否。字段映射。左侧的源头表字段和右侧的目标表字段为一一对应的关系。单击添加一行可以增加单个字段,鼠标放至需要删除的字段上,即可单击删除图标进行删除。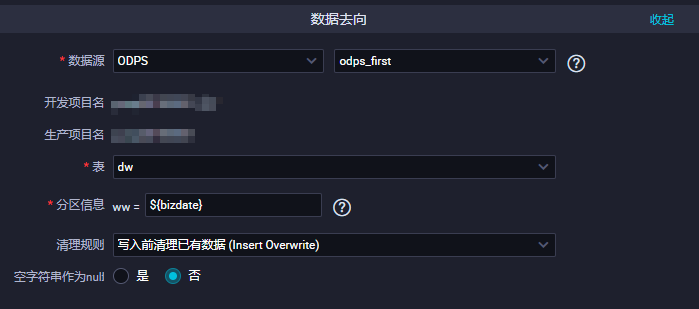
通道控制。单击工具栏中的保存图标。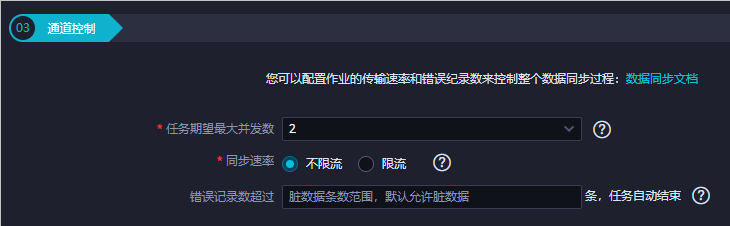
单击工具栏中的运行图标,运行之前需要配置自定义参数。
https://help.aliyun.com/document_detail/137834.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-10-18 17:54:53赞同 展开评论 打赏 -
 月移花影,暗香浮动
月移花影,暗香浮动在DataWorks中,对于ODPS(MaxCompute)的增量数据同步,目前可以采用以下两种方案:
方案一:使用定时增量同步前一天数据。基本思想:将昨天之前数据与昨天数据汇总,作为最新的数据集,运用${bdp.system.bizdate}动态获取昨天的日期,然后进行数据同步。
方案二:如果用户的数据是不更新只累加的数据,比如日志数据,可以在分析型数据库里创建表的时候设置二级分区。每次增量的数据导入到分析型数据库的一个二级分区里。
2023-10-17 14:20:33赞同 展开评论 打赏 -
 面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。在DataWorks中,可以通过以下步骤实现ODPS表的增量数据同步:
- 在DataWorks控制台中,选择“数据开发”模块,然后选择需要同步的ODPS表所在的项目和空间。
- 在项目和空间的左侧导航栏中,选择“数据开发”模块,然后选择“数据集成”功能。
- 在数据集成页面中,点击“新建任务”,选择需要同步的源表和目标表,然后配置同步方式和时间间隔。
- 在同步方式中,选择“增量同步”,并设置增量标记字段和增量标记值。增量标记字段是用来标记数据的更新时间,增量标记值是用来更新增量标记字段的值。例如,可以设置增量标记字段为“update_time”,增量标记值为源表中的最新更新时间。
- 点击“保存并执行”,执行同步任务,将ODPS表中的增量数据同步到目标表中。
2023-10-17 13:31:52赞同 展开评论 打赏 -

配置增量同步
数据集成离线同步任务中,可以使用调度参数来指定同步源表及目标表的数据路径以及数据范围,调度参数的配置方式与其他类型任务一致,没有特殊限制。在同步任务运行时,任务中配置的占位符参数都会被替换为调度参数表达式所表达的实际值,然后再执行数据同步。
以同步MySQL数据为例:
当不配置数据过滤时,默认同步全量数据至目标表中。
当配置数据过滤时,将只同步满足过滤条件的数据至目标表中。
目标MaxCompute表分区名称以调度参数的方式指定,$bizdate表示业务日期,定时任务执行时,任务配置的分区表达式会替换为调度参数所表达的业务日期。调度参数表达式的详细配置说明请参考文档:配置并使用调度参数。https://help.aliyun.com/zh/dataworks/user-guide/configure-a-batch-synchronization-node-to-synchronize-only-incremental-data?spm=a2c4g.11186623.0.i156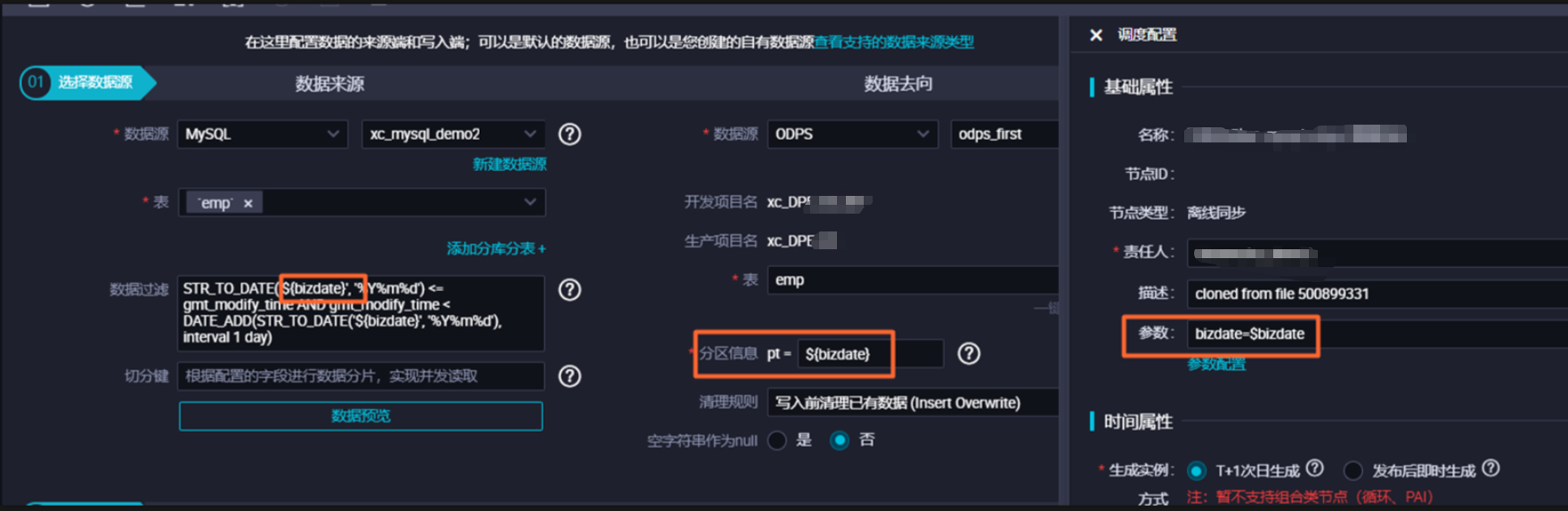 2023-10-17 11:29:01赞同 展开评论 打赏
2023-10-17 11:29:01赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
热门讨论
热门文章
相关课程
更多

相关文章
相关电子书
更多

