
DataWorks如何增加引擎的数量?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要增加DataWorks中已绑定引擎的数量,您需要首先登录DataWorks控制台。在左侧导航栏,单击工作空间列表。在对应工作空间的操作列单击工作空间配置。然后,在右侧配置页面中单击更多设置。在工作空间配置页面的计算引擎信息模块,选择引擎类型的页签。最后,单击“增加实例”,就可以增加已绑定引擎的数量。
请注意,不同版本的DataWorks中,单个工作空间可绑定的各类引擎的数量是有限制的,详情请参见各版本功能支持详情。如果您绑定的引擎数量已经达到这个限制,那么您将无法再绑定更多的引擎。
要增加DataWorks中引擎的数量,您需要首先登录DataWorks控制台。在左侧导航栏,找到并点击工作空间列表。接着,在对应工作空间的操作列中,点击工作空间配置。在弹出的右侧配置页面中,寻找并单击更多设置。然后,在工作空间配置页面的计算引擎信息模块,选择引擎类型的标签页。最后,单击“增加实例”,就可以增加已绑定引擎的数量。
需要注意的是,不同版本的DataWorks中,单个工作空间可以绑定的各类引擎的数量是有限制的,这个数量可能会有所不同。一旦您已经绑定的引擎数量超过了这个限制,系统将无法再绑定新的引擎。如果您需要新增一种类型的引擎,可以参考修改工作空间的服务配置(新增引擎类型)进行操作。
增加DataWorks引擎的数量,您可以通过以下步骤来操作:
DataWorks增加引擎的数量,可以通过以下步骤实现:
在DataWorks中,可以通过以下步骤增加引擎的数量:
添加完引擎后,可以使用DataWorks的数据集成任务从引擎中读取数据,并将数据导入到其他系统中。
DataWorks支持您通过引擎绑定的方式将计算引擎绑定至DataWorks作为DataWorks工作空间的引擎实例,可基于DataWorks进行该类任务的数据开发与周期调度等,本文为您介绍如何绑定与管理计算引擎。
前提条件
在进行引擎绑定前请务必提前了解简单模式工作空间与标准模式工作空间物理形态、对开发流程的影响等内容,详情请参见必读:简单模式和标准模式的区别。
背景信息
您需要在引擎配置前先了解引擎环境与DataWorks模块操作的对应关系。再来决定不同环境分别操作什么引擎(数据库,集群等),当前工作空间各环境绑定的引擎信息可以在管理中心 > 工作空间 > 计算引擎信息界面下查看。
引擎绑定注意事项(重点)
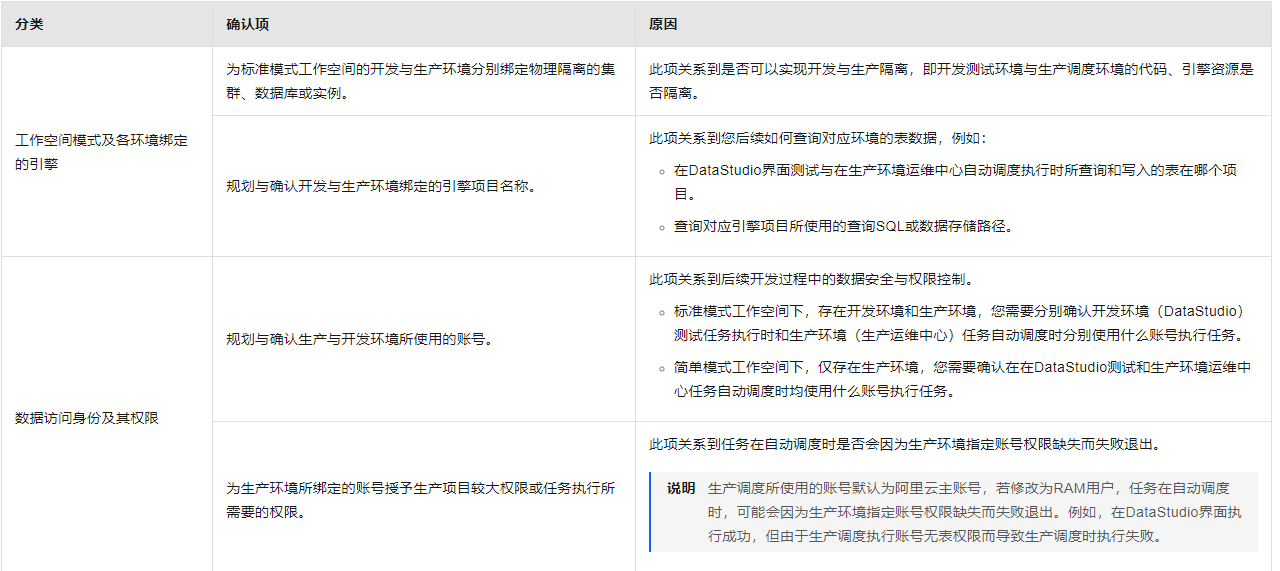
针对工作空间模式的物理特性及DataWorks基于该模式实现的开发机制,您需要在引擎绑定时确认各环境分别绑定的引擎,以及各环境分别使用的执行身份。
引擎绑定背景
标准模式工作空间存在开发与生产两个环境,可以分别操作不同的引擎,但只有生产环境的任务会自动调度,调度时只能使用一种身份执行,并且调度指定的账号拥有该项目较大权限。
简单模式工作空间仅有生产环境,DataStudio测试和生产环境调度均操作同一个引擎,且只能指定一个账号或任务责任人执行,并直接操作生产数据。
引擎绑定确认项
您在为工作空间绑定计算引擎时务必提前确认以下内容:
如果您想增加已绑定引擎的数量或修改已绑定引擎的详细配置信息,可参考以下步骤操作。如果您需要新增一种类型的引擎,您可参考修改工作空间的服务配置(新增引擎类型)进行操作。进入项目空间管理页面。登录DataWorks控制台。在左侧导航栏,单击工作空间列表。在对应工作空间的操作列单击工作空间配置。在右侧配置页面中单击更多设置。在工作空间配置页面的计算引擎信息模块,选择引擎类型的页签。单击增加实例,可增加已绑定引擎的数量。说明 不同版本的DataWorks中,单个工作空间可绑定的各类引擎的数量有限且不一致,详情可参见各版本功能支持详情,如果您绑定的引擎的数量超过限制,则无法继绑定。修改已绑定引擎的参数。页面中无法修改的参数即不支持修改。
https://help.aliyun.com/document_detail/206533.html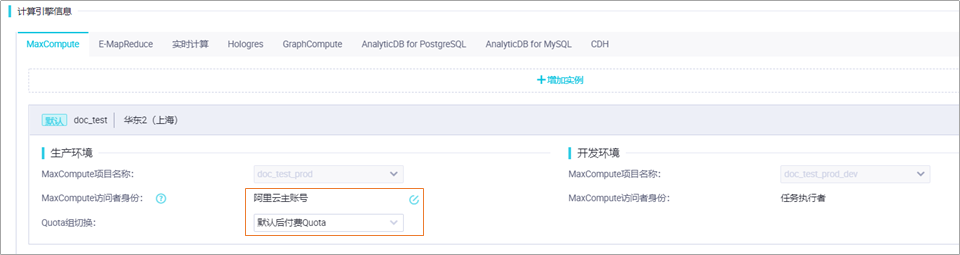
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在DataWorks中,您可以通过增加引擎的数量来提升作业的运行效率和吞吐量。增加引擎后,系统会自动将作业分配给空闲的引擎进行处理,从而缩短作业处理时间。
以下是增加DataWorks引擎数量的步骤:
登录到DataWorks控制台,在左侧导航栏中选择“运维中心”->“基础资源”->“引擎配置”。
在引擎配置页面中,单击右上角的“新增引擎”按钮。
在弹出的配置对话框中,选择需要新增的引擎规格(CPU和内存),并设置引擎的数量。请注意,不同规格的引擎具有不同的价格和性能,您需要根据实际需求进行选择。
配置完成后,单击“确定”按钮保存设置。系统会自动购买和部署新的引擎,这个过程可能需要一些时间,请耐心等待。
新增完成后,您可以返回引擎配置页面查看新增的引擎信息。此时,您可以将已有的作业配置为使用新引擎进行调度,以提高作业的运行效率。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



{kind=link}