
藏经阁2.0全新上线!下载本地、线上阅读让你轻松获取技术知识。为了让更多人学习到藏经阁中的优秀技术作品,培养好的阅读习惯,“藏经阁一起读”活动来啦,你阅读,我奖励!
本期书籍:《阿里云 ClickHouse 企业版技术白皮书》
阅读地址:https://developer.aliyun.com/ebook/8050
书籍简介:本书由 ClickHouse 资深技术专家和产品联合撰写,全面介绍了ClickHouse企业版的云原生存算分离整体架构,详细介绍 SharedMergeTree表引擎的实现机制原理及基准测试结果,并介绍 Lightweight update 增强数据更新的实时性的实现原理,是学习 ClickHouse 云原生技术的宝贵资源。
活动规则:阅读书籍,将你对于本书的想法、收获等在评论区留言,评论不少于200字,将选取评论质量最高的前2名送出ET勋章一个。


活动时间:2023年9月25日~10月1日24:00
参与用户务必扫码加入钉群,第一时间了解活动进展、获取得奖信息。

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
【藏经阁一起读(71)】读《阿里云 ClickHouse 企业版技术白皮书》

作者: Tom Schreiber 凤豪 卫寻 魏庄
本书由 ClickHouse 资深技术专家和产品联合撰写,全面介绍了ClickHouse企业版的云原生存算分离整体架构,详细介绍 SharedMergeTree表引擎的实现机制原理及基准测试结果,并介绍 Lightweight update 增强数据更新的实时性的实现原理,是学习 ClickHouse 云原生技术的宝贵资源。
《阿里云 ClickHouse 企业版技术白皮书》不属于初级技术书籍,Clickhouse是什么,文中没有相关介绍,我自己先补习了一些相关知识:
ClickHouse是一种OLAP类型的列式数据库管理系统,是一个全球流行的开源高性能、可扩展列式数据库技术,核心应用于在线分析处理(OLAP)业务,
ClickHouse完美的实现了OLAP和列式数据库的优势,因此在大数据量的分析处理应用中Clickhouse表现很优秀。
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
OLAP(OnLine Analysis Processing ,联机分析处理 ) 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。在实际的商业分析中,OLAP联机分析更多的是指对数据分析的一种解决方案。
OLAP联机分析首先是把数据预处理成数据立方(Cube),并把有可能的汇总都预先算出来(即预聚合处理),然后在用户选择多维度汇总时,在预先的计算出来的数据基础上很快地计算出用户想要的结果,从而可以更好更快地支持极大数据量的及时分析。
OLAP联机分析最基本的工作就是对数据方(Cube)的操作
OLAP联机分析是从多维信息、多层次信息的角度,针对特定问题进行数据的汇总分析。
在传统的行式数据库系统中,数据按如下顺序存储: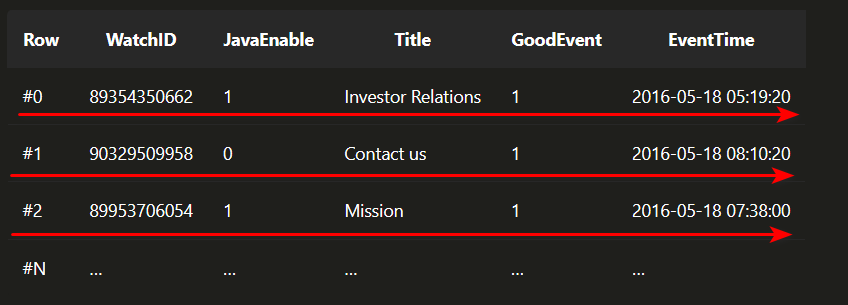
处于同一行中的数据总是被物理的存储在一起。
常见的行式数据库系统有:MySQL、Postgres和MS SQL Server。
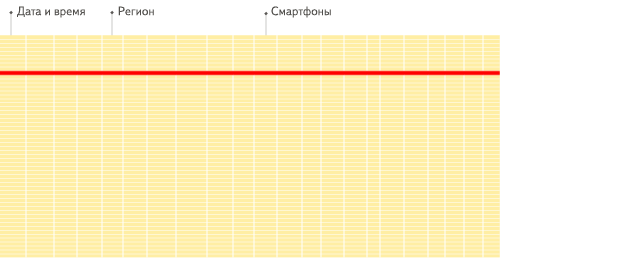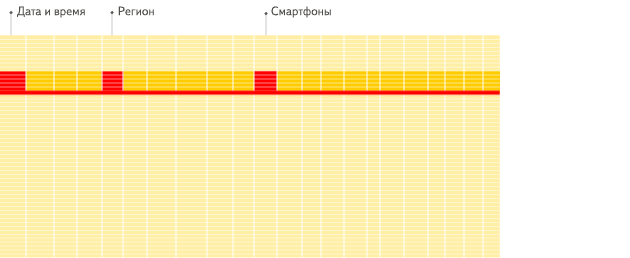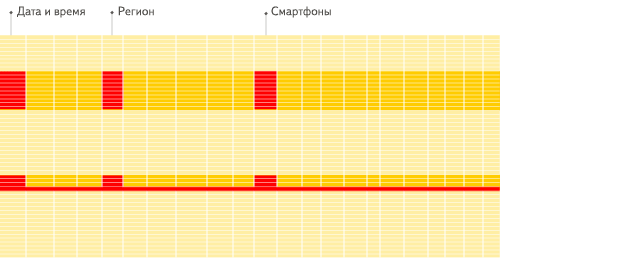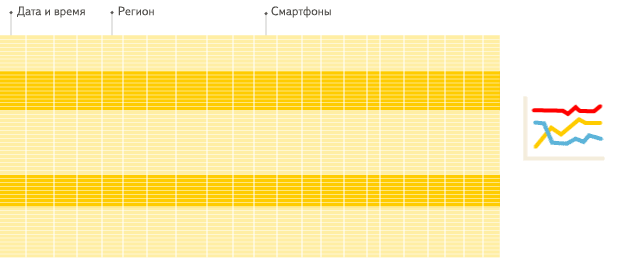
在列式数据库系统中,数据按如下的顺序存储:
这些示例只显示了数据的排列顺序。来自不同列的值被单独存储,来自同一列的数据被存储在一起。
常见的列式数据库有: Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+。
列式数据库更适合于OLAP场景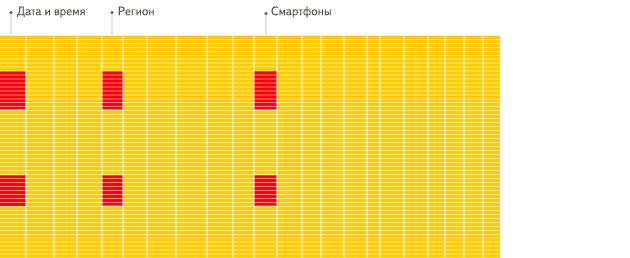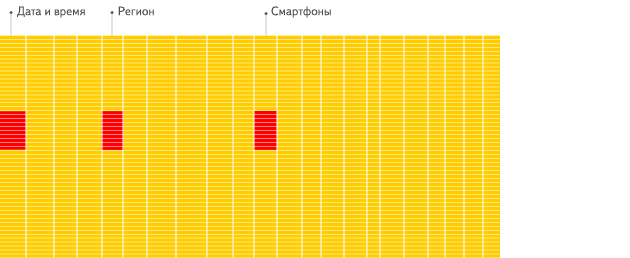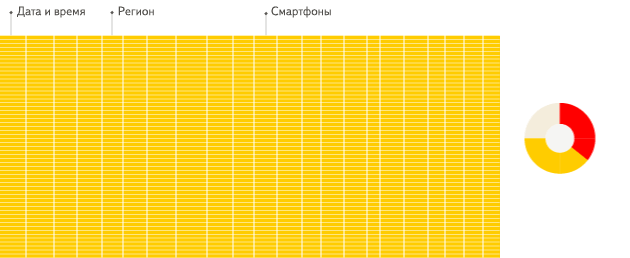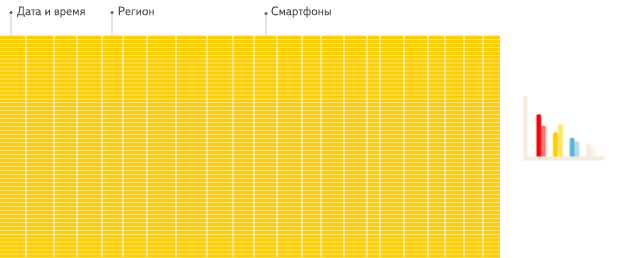
不同的数据存储方式适用不同的业务场景,数据访问的场景包括:进行了何种查询、多久查询一次以及各类查询的比例;每种类型的查询(行、列和字节)读取多少数据;读取数据和更新之间的关系;使用的数据集大小以及如何使用本地的数据集;是否使用事务,以及它们是如何进行隔离的;数据的复制机制与数据的完整性要求;每种类型的查询要求的延迟与吞吐量等等。
系统负载越高,依据使用场景进行定制化就越重要,并且定制将会变的越精细。没有一个系统能够同时适用所有不同的业务场景。如果系统适用于广泛的场景,在负载高的情况下,要兼顾所有的场景,那么将不得不做出选择。是要平衡还是要效率?
ClickHouse在DB—Engine 全球数据库流行度排榜排名前列,逐年关注度增长迅猛。ClickHouse 分析性能优异,典型分析场景下,支持数十亿级数据行规模,90%查询在1秒内完成。这使得 ClickHouse 成为企业处理大规模数据,构建实时数仓的理想选择。国内外大厂中,微软,腾讯、ebay,淘宝、Uber,京东、快手、小红书,携程都使用 ClickHouse 构建数据分析平台。
MergeTree(合并树)系列表引擎是ClickHouse提供的最具特色的存储引擎。MergeTree 引擎系列的基本理念如下。当你有巨量数据要插入到表中,你要高效地一批批写入数据片段,并希望这些数据片段在后台按照一定规则合并。相比在插入时不断修改(重写)数据进存储,这种策略会高效很多。MergeTree引擎支持数据按主键、数据分区、数据副本以及数据采样等特性。官方提供了包括MergeTree、ReplacingMergeTree、SummingMergeTree、AggregatingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree、GraphiteMergeTree等7种不同类型的MergeTree引擎的实现,以及与其相对应的支持数据副本的MergeTree引擎(Replicated*)。
MergeTree是该系列引擎中最核心的引擎,其他引擎均以MergeTree为基础,并在数据合并过程中实现了不同的特性,从而构成了MergeTree表引擎家族。
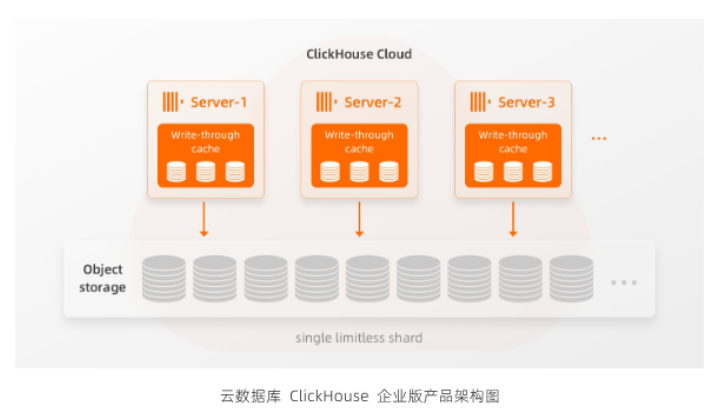
ClickHouse 企业版采用完全不同与开源社区版本的云原生新架构,针对云环境做了全面适配。新架构基于存储和计算分离的架构基础,采用对象存储数据实现 Share Storage 共享存储,所有ClickHouse Server 节点都可以访问相同的全局物理数据,单个Server 节点实际上是单个没有限制分片的Replica 节点,节点之间访问同一份数据副本。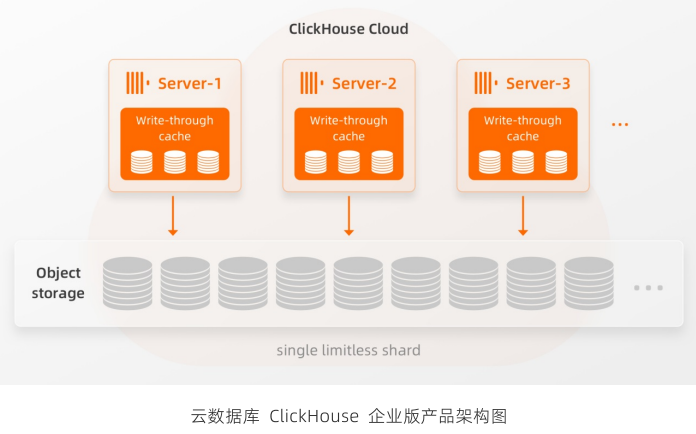
MergeTree系列的表引擎是ClickHouse中的主要表引擎。它们负责存储插入的数据,在后台进行数据合并,根据特定的引擎进行数据转换等操作。企业版新推出SharedMergeTree引擎加入到MergeTree引擎大家庭,而企业版能够支持云原生架构箩也核心依赖sharedMergeTree引擎。sharedMergeTree引擎是商业化引擎,仅在企业版提供,在开源社区版不支持。
3.1、开源ReplicatedMergeTree引擎
大多数MergeTree家族中的表都支持自动的数据复制,并通过表引擎的复制机制实现
3.2、云原生SharedMergeTree引擎ReplicatedMergeTree
SharedMergeTree表引擎是ClickHouse内核ReplicatedMergeTree表引擎的更高效的替代品,专为云原生数据处理而设计和优化。
深入了解这个表引擎,解释其优势,并通过基准测试展现其效率。
3.3、对象存储上的数据可用性
3.4、自动集群扩展
ReplicatedMergeTree表引擎并不适用于ClickHouse企业版的预期架构,因为其复制机制旨在在少量的节点上创建数据的物理副本。而ClickHouse企业版需要一个支持在对象存储之上运行本量计算服务节点的表引擎。
ClickHouse企业版实现了一个名为 SharedMergeTree的表引擎 - 专为在共享存储上工作而设计。SharedMergeTree 是云原生方式,具有如下优点
(1) MergeTree 代码更加简单易维护,
(2)支持垂直和水平自动扩展,
(3)为我们的云用户提供未来的功能和改进,如更高的一致性保证,更好的耐用性,基于时间点数据恢复等。
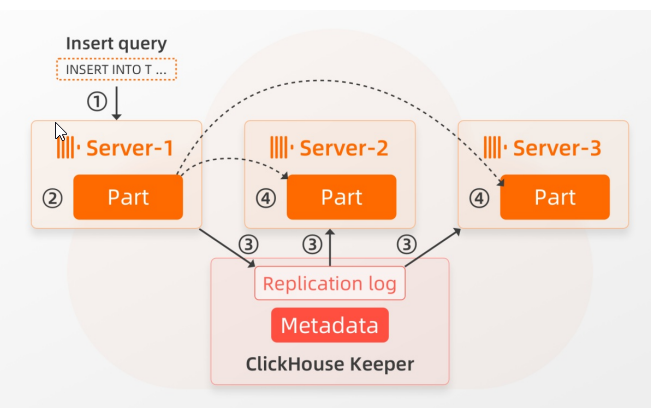
在这里,我们简要介绍 SharedMergeTree 如何支持ClickHouse企业版自动进行集群扩展。提醒一下:ClickHouse企业版计算节点是具有访问共享存储的计算单元,其规格和数量可以更改。基于此机制,SharedMergeTree 完全将业务数据和元数据的存储与计算节点分离,并使用Keeper的接口去读取、写入和修改共享元数据。每个计算节点都有一个存储元数据的本地缓存,并通过订阅机制自动获取数据更改的通知。下图描述了如何使用 SharedMergeTree 将新服务器添加到集群中:
当Server-3 添加到集群时,这个新Server ① 订阅 Keeper 中的元数据更改信息并将当前Parts的元数据获取到其本地缓存中。这不需要任何锁机制;
②新Server基本上只需说:“我在这里。请随时通知我所有数据更改”。
③新添加的Server-3 几乎可以立即参与数据处理,因为它通过从 Keeper 中只获取必要的元数据信息,找到有哪些数据以及在共享存储中的什么位置。
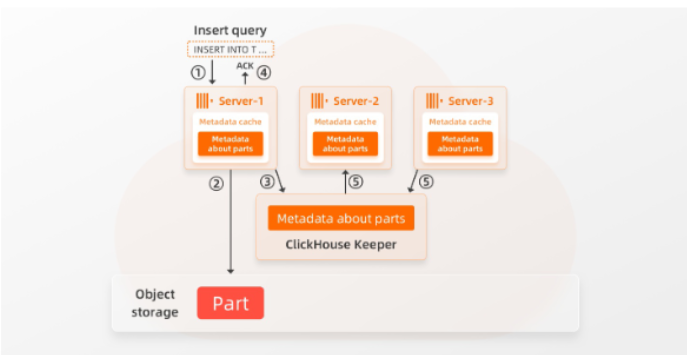
下图描述所有Server 节点如何知道新插入的数据,来保证查询数据一致性:
① Server-1 接收到插入查询
② Server-1将写入的数据以Part的形式写入共享存储。
③ Server-1 还将关于该部分的信息存储在其本地缓存和 Keeper 中(例如,哪些文件属于该Part,以及与文件对应的块位于共享存储中的位置)。
④ ClickHouse 向查询的发送者确认插入成功。其他节点(Server-2、Server-3)通过 Keeper 的订阅机制 ⑤ 自动得到存储层中存在新数据的通知,并将更新的元数据提取到其本地缓存中。
请注意,在步骤 ④ 之后,插入的数据是持久的。即使Server-1或其他任何节点崩溃,Part都存储在高可用的存储中,元数据存储在 Keeper 中(Keeper 具有至少 3 个 Keeper节点的高可用设置)。
从集群中移除节点也是一个简单且快速的操作。为了优雅地移除,相关节点只需从 Keeper 中注销,以便处理进行中的分布式查询时不会出现缺少服务器的警告。
SharedMergeTree 表引擎现在已经作为 ClickHouse企业版中默认的表引擎。ClickHouse企业版支持的 MergeTree 家族中的所有特殊表引擎,并都会自动基于 SharedMergeTree 进行更新。
SharedMergeTree 支持无缝的集群扩展。测试中,后台合并的吞吐量与节点数量呈线性关系。当我们将节点数量从 3 增至 10 时,吞吐量也将增加三倍左右。当我们将节点数量再次增加 2 倍至 20,然后增加 4 倍至 80 时,吞吐量也分别增加了约两倍和四倍。正如预期的那样,使用ReplicatedMergeTree 在随着副本节点数量的增加时无法很好地扩展(甚至在较大的集群大小下会减少写入性能),而SharedMergeTree 则随着副本节点数量的增加而获得更好的扩展。因为它的复制机制不适用于处理大量副本的情况。
通过阅读《阿里云ClickHouse企业版技术白皮书 》,我了解了企业版的技术架构和实现原理,了解了ClickHouse 企业版 SharedMergeTree 表引擎的机制,丰富了云原生知识。
阿里云
网络
ClickHouse官方
https://zhuanlan.zhihu.com/p/621480049
https://zhuanlan.zhihu.com/p/361622782
首先,ClickHouse是一个流行的开源列式数据库管理系统,适用于大规模数据分析和查询场景。它在查询性能和处理大规模数据方面具有显著优势。
《ClickHouse企业版的云原生存算分离整体架构》这本书,首先介绍了ClickHouse企业版的架构,包括存储、计算和管理三个主要部分,并对其云原生的设计理念进行了解释。然后,书中重点讲述了SharedMergeTree表引擎的设计和实现原理,这是ClickHouse的核心技术之一,被广泛应用于复杂的数据合并操作和优化查询性能。此外,书中还介绍了轻量级更新(Lightweight update)的实现原理,它是ClickHouse的另一项重要技术,能够实现实时数据更新和高性能查询。
总的来说,这本书对于想深入了解ClickHouse的云原生架构和表引擎工作原理的读者,是一份非常有价值的资源。同时,对于需要在大规模数据分析和查询方面提高性能的企业也很有参考意义。
读完《阿里云 ClickHouse 企业版技术白皮书》后,我深深地被 ClickHouse 的强大功能和性能所吸引。这本书全面介绍了 ClickHouse 企业版的云原生存算分离整体架构,详细介绍了 SharedMergeTree 表引擎的实现机制原理及基准测试结果,并介绍 Lightweight update 增强数据更新的实时性的实现原理,是一本非常实用的技术白皮书。
首先,我被 ClickHouse 的高性能所吸引。ClickHouse 是一个基于列存储的开源数据库,它具有非常高的查询性能和写入性能。在基准测试中,ClickHouse 的查询性能是 MySQL 的 10 倍以上,写入性能是 MySQL 的 100 倍以上。这使得 ClickHouse 成为处理大规模数据的理想选择。
其次,我被 ClickHouse 的云原生特性所吸引。ClickHouse 企业版采用了云原生存算分离的架构,数据存储在阿里云的 OSS 中,计算则在阿里云的 ECS 上进行。这种架构使得 ClickHouse 可以充分利用云的弹性资源,实现数据的高效处理和存储。
最后,我被 ClickHouse 的灵活性所吸引。ClickHouse 支持多种数据类型和多种查询语言,可以满足不同场景下的需求。此外,ClickHouse 还支持多种数据源,可以方便地从其他数据库中导入数据。
总的来说,我非常推荐大家阅读《阿里云 ClickHouse 企业版技术白皮书》。这本书不仅介绍了 ClickHouse 的强大功能和性能,还提供了很多实用的技巧和经验,对于想要学习和使用 ClickHouse 的开发者来说,是一本非常有价值的参考资料。
《阿里云 ClickHouse 企业版技术白皮书》是一份详细介绍阿里云 ClickHouse 企业版技术特性和应用场景的文档。通过阅读这份白皮书,我了解到 ClickHouse 是一款高性能、高可用、高扩展性的列式数据库,适用于大规模数据处理和分析场景。以下是我在阅读这份白皮书后的心得体会。
首先,ClickHouse 的高性能是其最大的特点之一。ClickHouse 采用了列式存储方式,可以充分利用硬件资源,提高查询速度。同时,ClickHouse 还支持并行查询和向量化计算,进一步提高了查询性能。此外,ClickHouse 还支持多种数据类型和数据格式,可以满足不同场景下的数据处理需求。
其次,ClickHouse 的高可用性也是其重要的特点之一。ClickHouse 支持分布式部署和故障恢复,可以保证数据的高可用性。同时,ClickHouse 还支持数据备份和恢复,可以防止数据丢失。此外,ClickHouse 还支持数据分片和负载均衡,可以提高系统的稳定性和可靠性。
再次,ClickHouse 的高扩展性也是其重要的特点之一。ClickHouse 支持水平扩展和垂直扩展,可以根据业务需求灵活调整系统规模。同时,ClickHouse 还支持数据分片和负载均衡,可以提高系统的扩展性和可伸缩性。此外,ClickHouse 还支持实时数据处理和实时数据分析,可以满足实时业务的需求。
最后,ClickHouse 的应用场景非常广泛。ClickHouse 可以用于大规模数据处理和分析,例如日志分析、实时流处理、数据仓库等。同时,ClickHouse 还可以用于实时推荐系统、实时广告系统、实时交易系统等。此外,ClickHouse 还可以用于大规模机器学习和深度学习任务,例如图像识别、语音识别、自然语言处理等。
除了上述特点和应用场景,ClickHouse 还具有以下优点:
在这篇评论中,我将分享我阅读《ClickHouse云原生技术详解》这本书的体验和感想。这本书由ClickHouse资深技术专家和产品联合撰写,全面介绍了ClickHouse企业版的云原生存算分离整体架构,让我对ClickHouse云原生技术有了更深入的了解。
首先,这本书的内容非常丰富,不仅详细介绍了SharedMergeTree表引擎的实现机制原理及基准测试结果,还介绍了Lightweight update增强数据更新的实时性的实现原理。通过对这些内容的阅读和学习,我深刻体会到了ClickHouse云原生技术的强大和优势。
在读完这本书后,我认为本书的写作风格非常清晰易懂,每一个技术细节都讲得非常透彻。同时,这本书也是一本非常实用的参考书籍,对于想深入了解ClickHouse云原生技术的读者来说,具有很高的参考价值。
在这本书中,最让我印象深刻的技术亮点是SharedMergeTree表引擎和Lightweight update。SharedMergeTree表引擎使得数据存储更加高效,而Lightweight update则大幅度提升了数据更新的实时性。这些技术不仅展示了ClickHouse云原生技术的先进性,也为读者提供了很好的学习参考。
当然,这本书也不是毫无瑕疵。在某些技术细节方面,可能存在一些过于复杂难懂的地方,需要读者有一定的技术背景和悟性才能完全理解。但是,这并不影响整体上对这本书的推荐。
总的来说,我非常喜欢这本书,它为我提供了很多关于ClickHouse云原生技术的宝贵资源。如果你想深入了解ClickHouse云原生技术,那么这本书绝对值得一读。我强烈推荐这本书给所有对ClickHouse云原生技术感兴趣的读者!
在阅读《阿里云 ClickHouse 企业版技术白皮书》的过程中,我深受启发,有一些心得和感悟。以下是我对这部白皮书的理解和思考:
数据处理的复杂性:ClickHouse 作为一款高性能的分布式列式存储数据库,其最大的优点是能够在不同的数据场景下提供高性能、低延迟的查询和数据处理能力。然而,随着企业数据的爆炸性增长,数据处理变得更加复杂和挑战性。因此,我们需要不断地优化数据处理技术,以应对不断变化的数据需求。
数据安全的重要性:随着数字化转型的加速,数据已经成为企业的重要资产。因此,数据安全问题越来越受到关注。在白皮书中,阿里云 ClickHouse 企业版在数据安全方面进行了全面的阐述,包括数据加密、访问控制、数据备份和恢复等方面的技术。这些技术对于保护企业的核心数据至关重要。
本期书籍《阿里云 ClickHouse 企业版技术白皮书》是一本由 ClickHouse 资深技术专家和产品联合撰写的宝贵资源,全面深入地介绍了 ClickHouse 企业版的云原生存算分离整体架构、SharedMergeTree表引擎实现机制原理及基准测试结果,以及 Lightweight update 增强数据更新的实时性的实现原理。
从技术角度来看,这本书具有很高的价值和参考性。首先,它有着相当的深度和广度,详细地涵盖了 ClickHouse 企业版的各个方面,从整体架构到具体的技术细节都有所涉及。这不仅可以让读者全面地了解 ClickHouse 企业版的技术体系,也能为他们在实践中提供有力的指导。
其次,这本书的表述清晰度很高,用语简练易懂,即使是没有多少技术背景的读者也能轻松理解。作者们用通俗易懂的语言解释了复杂的 技术原理,让读者在阅读的过程中不会感到枯燥无味。
此外,这本书还具有很高的可读性。除了清晰简明的表述外,书中还结合了大量的图表和案例,让读者可以更加直观地理解各项技术的实现原理和应用场景。无论是初学者还是有一定经验的读者,都能从中获得有价值的信息。
值得一提的是,这本书的主题非常鲜明,它主要围绕 ClickHouse 企业版的云原生存算分离架构和 SharedMergeTree、Lightweight update 等关键技术展开。对于这些技术的深入探讨,不仅可以帮助读者更好地理解 ClickHouse 企业版的核心竞争力,也能为读者在实际工作中提供有力的参考。
总的来说,《阿里云 ClickHouse 企业版技术白皮书》是一本非常优秀的书籍,无论你是从事数据库技术工作的专业人士,还是对数据库技术感兴趣的初学者,都能从中获得很多有价值的信息和启示。我非常推荐这本书给所有对数据库技术和云原生架构感兴趣的读者。最后,我想说的是这本书真的是阿里云 ClickHouse 企业版技术领域的一本宝典,值得大家深入阅读和学习。
通过阅读《阿里云 ClickHouse 企业版技术白皮书》,我对阿里云 ClickHouse 企业版的技术特性和优势有了更深入的理解。这不仅增强了我对阿里云的技术实力的信心,也为我未来在大数据领域的工作提供了新的视角和思考。
读完《阿里云 ClickHouse 企业版技术白皮书》后,我深感ClickHouse在大数据处理方面的强大能力。ClickHouse是一款开源的列式数据库,具有高并发、低延迟、高性能的特点,特别适合于实时数据处理和分析。

本书详细介绍了ClickHouse企业版的云原生存算分离整体架构,让我对ClickHouse的架构有了更深入的理解。云原生存算分离架构将计算和存储分离,可以充分利用云资源,提高数据处理效率。
同时,本书还介绍了SharedMergeTree表引擎的实现机制原理及基准测试结果,让我对ClickHouse的表引擎有了更深入的了解。SharedMergeTree表引擎是ClickHouse的核心表引擎,具有高并发、低延迟、高性能的特点,特别适合于实时数据处理和分析。
此外,本书还介绍了Lightweight update增强数据更新的实时性的实现原理。Lightweight update是一种新型的数据更新方式,可以大大提高数据更新的实时性。通过Lightweight update,ClickHouse可以在数据更新时,只更新部分数据,而不是全部数据,从而大大提高数据更新的效率。

总的来说,我认为《阿里云 ClickHouse 企业版技术白皮书》是一本非常有价值的书籍。它不仅介绍了ClickHouse的基本概念和架构,还介绍了ClickHouse的实现机制和优化方法,对于学习和使用ClickHouse都非常有帮助。我相信,通过阅读这本书,我可以更好地理解和使用ClickHouse,提高我的大数据处理能力。
在阅读《阿里云 ClickHouse 企业版技术白皮书》的过程中,我深受启发,有一些心得和感悟。以下是我个人的总结:
重视技术积累与研发
阿里云 ClickHouse 企业版的成功,与其深厚的技术积累和持续的研发投入密不可分。从白皮书中可以看出,阿里云在 ClickHouse 的核心技术、功能和性能方面投入了大量资源进行研发和创新,从而打造出了一款高效、稳定、安全的企业级数据仓库产品。这让我认识到,一家科技企业要想在激烈的市场竞争中脱颖而出,必须注重技术积累和研发实力的提升。
关注用户体验与需求
白皮书强调了阿里云 ClickHouse 企业版在用户体验方面的优势,例如易用性、可扩展性和灵活性等。这些优势不仅体现在产品的功能设计上,更表现在为用户提供多元化、个性化的解决方案上。通过深入了解用户需求,阿里云 ClickHouse 企业版将用户体验放在首位,从而赢得了市场和用户的认可。这让我明白,在产品设计和服务过程中,关注用户体验和需求至关重要。
加强生态合作与共赢
白皮书还提到了阿里云 ClickHouse 企业版与众多合作伙伴共同打造的生态圈。这种合作模式使得企业能够更好地满足用户需求,提供更为完善的产品和服务。同时,通过与合作伙伴共享资源、互利共赢,阿里云 ClickHouse 企业版不断拓展自身的业务领域和市场影响力。这让我认识到,企业要想取得长足发展,必须注重与合作伙伴的生态合作,共同实现价值最大化。
推动行业发展与进步
阿里云 ClickHouse 企业版不仅是一款产品,更是推动了整个行业的发展与进步。白皮书提到,阿里云 ClickHouse 企业版在数据仓库领域的技术创新和应用实践,为其他企业提供了借鉴和参考。同时,阿里云的开源精神也为整个行业注入了活力和创新力。这让我感受到,一个企业的成功并非仅限于自身的商业利益,更在于推动整个行业的进步与发展。
总的来说,《阿里云 ClickHouse 企业版技术白皮书》为我提供了宝贵的学习机会,让我深入了解阿里云 ClickHouse 企业版的成功经验和技术理念。通过对比和学习,我能够更好地认识到自身的不足之处,并且激励自己不断努力和进步。感谢这次阅读经历!
读《阿里云 ClickHouse 企业版技术白皮书》,你有哪些心得?
在阅读《阿里云 ClickHouse 企业版技术白皮书》的过程中,我获得了一些关于 ClickHouse 企业版技术的深入理解。以下是我总结的一些主要心得:
ClickHouse 的高性能:ClickHouse 是一个用于在线分析(OLAP)的列式数据库管理系统(DBMS)。它被设计成可以高效地处理大量数据,并提供了快速的查询能力。这种高性能使得 ClickHouse 适合于处理大规模的实时分析和报表生成。
分布式架构:ClickHouse 支持分布式架构,这意味着它可以轻松地扩展到多个节点。这对于需要处理大量数据的企业来说是非常有用的,因为它们可以通过增加更多的节点来提高系统的性能和容量。
数据压缩和优化:ClickHouse 使用先进的数据压缩技术,这使得它可以有效地存储和传输数据,同时降低了存储和网络成本。此外,ClickHouse 还提供了许多优化选项,如数据分区、数据索引等,以进一步提高查询性能。
强大的查询语言:ClickHouse 支持 SQL-on-Hadoop,这使得它可以轻松地与现有的 Hadoop 生态系统集成。这对于那些已经在使用 Hadoop 的企业来说是一个很大的优势,因为它们可以利用 ClickHouse 的高性能和可扩展性,同时继续使用他们已经熟悉的 SQL 语言。
企业级特性:ClickHouse 企业版提供了许多企业级特性,如数据安全、高可用性、故障恢复等。这些特性使得 ClickHouse 可以满足大型企业的需求,并确保它们的关键业务数据是安全和可靠的。
总的来说,通过阅读《阿里云 ClickHouse 企业版技术白皮书》,我对 ClickHouse 企业版的技术特点有了更深入的了解。这对于我们未来的数据处理和数据分析有很大的参考价值。
我认真阅读了《阿里云 ClickHouse 企业版技术白皮书》这本书,收获颇丰。首先,我对ClickHouse有了更加深入的了解,包括它的云原生存算分离整体架构和SharedMergeTree表引擎的实现机制原理等。这些知识让我对大数据处理有了更深的理解,也让我认识到ClickHouse在处理大规模数据时的优势。
其次,书中关于Lightweight update的介绍让我印象深刻。这种更新方式能够提高数据的实时性,这对于许多应用场景来说都是非常重要的。通过这种方式,我们可以更快地获取到最新的数据,从而做出更准确的决策。
此外,书中的基准测试结果也让我大开眼界。通过这些测试,我们可以看到ClickHouse在各种场景下的性能表现,这对于我们选择合适的数据库系统提供了有力的参考依据。
总的来说,这本书是一本非常实用的技术书籍,无论是对于大数据领域的从业者还是学生,都能从中获得宝贵的知识和经验。我会将这本书推荐给我身边的人,让更多的人了解和学习ClickHouse这一优秀的数据库系统。

