
DataWorks如何全量下载?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
下载数据。
【下载方式一】DataStudio查询结果下载
限制:上限1万条。
step1:项目管理员角色设置项目开启允许下载。
step2:DataStudio查询结果下载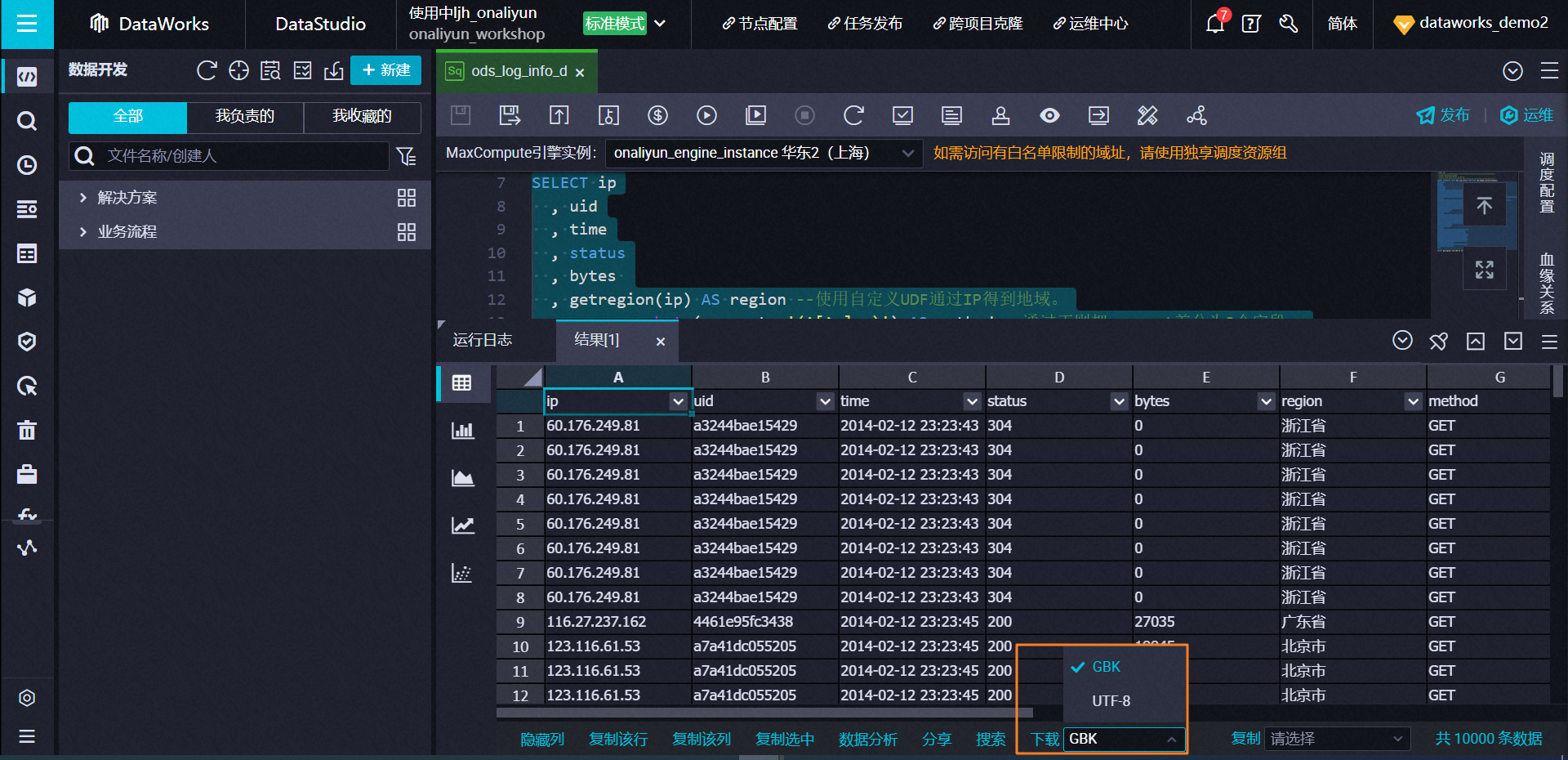
【下载方式二】数据分析查询结果下载
限制:,DataWorks标准版及以上上限20万条,基础版上限1万条。仅阿里云主账号和租户管理员可以访问编辑。
step1:安全中心>安全策略>数据查询与分析管控,开启下载
新版本: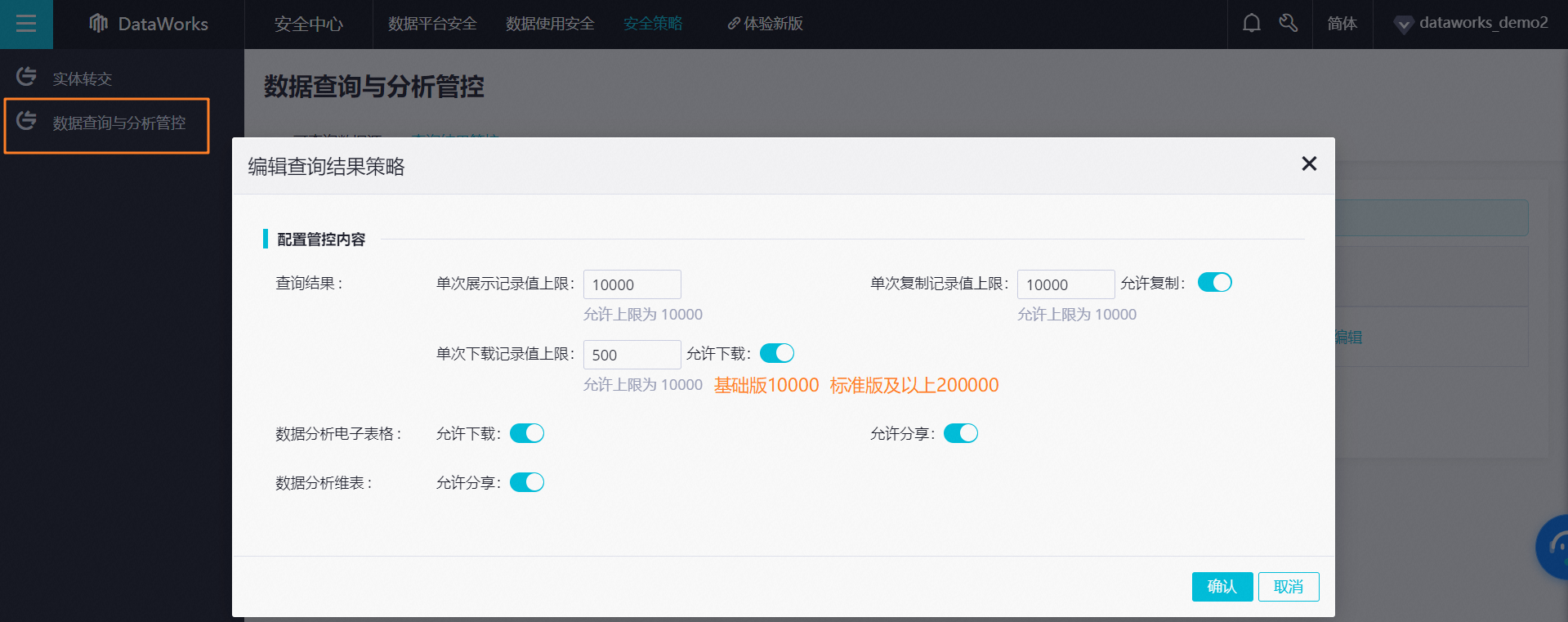
老版本:数据分析-系统管理-设置允许下载。
step2:SQL查询结果下载。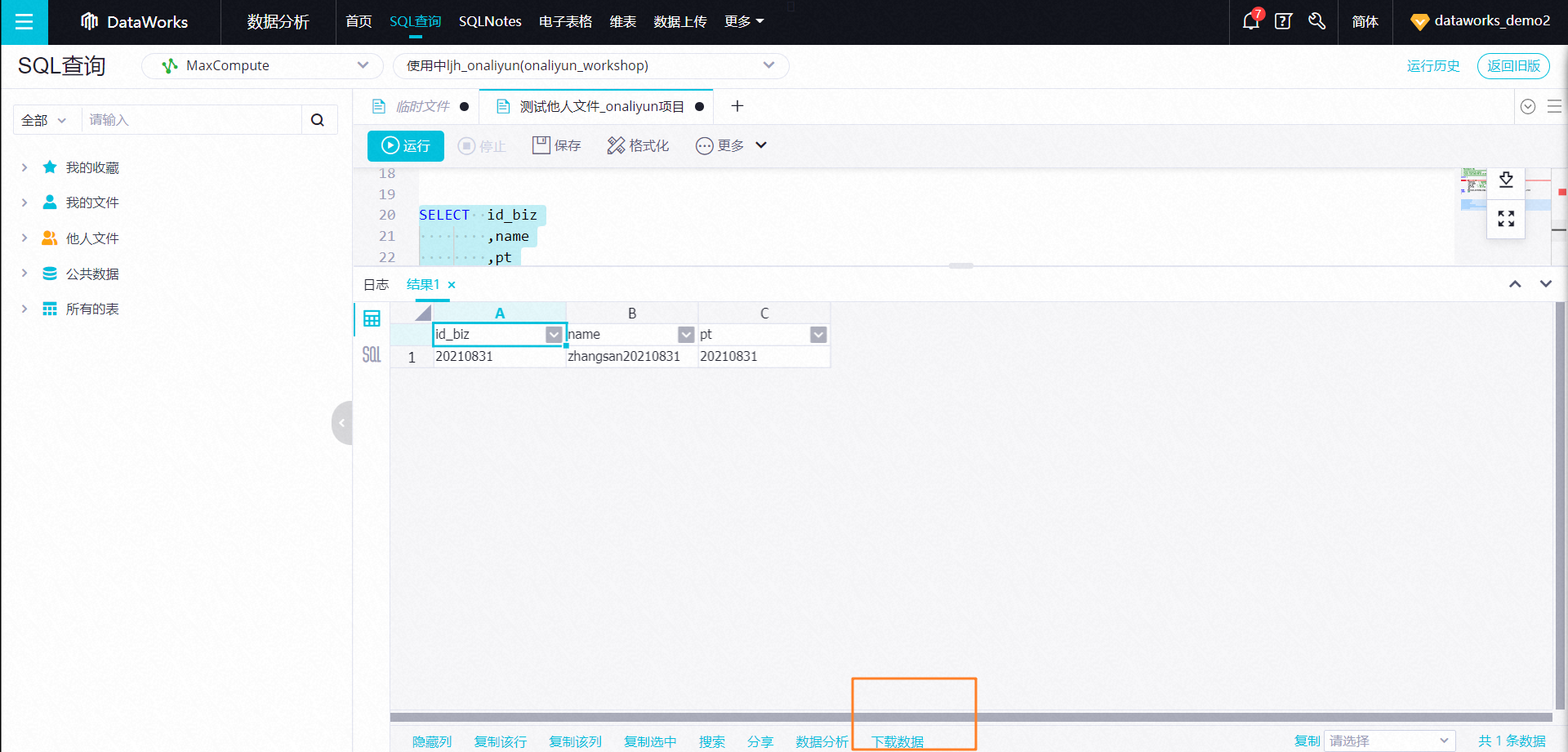
【下载方式三】SQLTask配合Tunnel实现量数据导出
限制:支持全量下载。,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在DataWorks中,全量下载是指将数据从数据源完整地导出到本地文件或存储系统。下面是使用DataWorks实现全量下载的一种常见方法:
创建离线同步任务:在DataWorks中,创建一个离线同步任务,用于将数据从数据源导入到目标数据表。确保配置正确的源表和目标表,并选择执行模式为"全量导入"。
设置数据源连接和目标表定义:在离线同步任务的配置中,提供正确的数据源连接信息,包括数据库地址、端口号、用户名、密码等。同时,指定目标表的表名和字段映射关系。
配置导出参数:根据需要,设置导出参数,如分区策略、数据过滤条件等。确保导出参数能够满足你的全量下载需求。
运行离线同步任务:保存离线同步任务配置后,可以手动运行该任务,以触发数据的全量导入操作。在任务运行期间,DataWorks会自动执行全量下载逻辑,并将数据导入到目标表中。
下载导出结果:当离线同步任务完成后,你可以通过DataWorks提供的"导出数据"功能,将目标表的数据下载到本地文件或存储系统。这可以完成全量下载的过程。
请注意,具体的配置和操作步骤可能因DataWorks版本和数据源类型而有所不同。建议参考DataWorks的官方文档和技术支持资源,以获取更详细的指导和帮助。
另外,全量下载涉及大量数据的导出和存储,可能会对系统资源和网络带宽造成一定的负载。在执行全量下载前,请确保你的系统和网络环境具备足够的性能和容量来处理和存储导出的数据。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


