
模型:
SambertHifigan语音合成-中文-多人预训练-16k
https://modelscope.cn/models/speech_tts/speech_sambert-hifigan_tts_zh-cn_multisp_pretrain_16k/summary
训练 部分
trainer = build_trainer(
Trainers.speech_kantts_trainer, default_args=kwargs)
trainer.train()
# 就是上面这句,在本地环境,阿里云ECS+EAIS实例上,都会报同样错误。
# 魔搭提供的Notebook GPU版本可以通过。
本地Docker环境,GPU 检查 与命令 nvidia-smi,都正常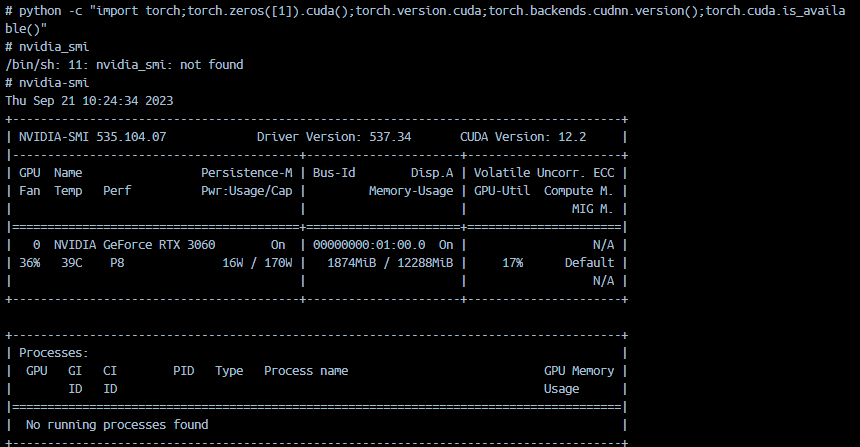
ECS+EAIS环境,查看GPU命令eais_smi,也可以通过
但这两个环境都还是会报同样错误
File "voicegen.py", line 135, in tune
trainer.train()
File "/opt/conda/lib/python3.7/site-packages/modelscope/trainers/audio/tts_trainer.py", line 229, in train
self.prepare_data()
File "/opt/conda/lib/python3.7/site-packages/modelscope/trainers/audio/tts_trainer.py", line 208, in prepare_data
se_model)
File "/opt/conda/lib/python3.7/site-packages/modelscope/preprocessors/tts.py", line 37, in __call__
speaker_name, target_lang, skip_script, se_model)
File "/opt/conda/lib/python3.7/site-packages/modelscope/preprocessors/tts.py", line 57, in do_data_process
targetLang, skip_script, se_model)
File "/opt/conda/lib/python3.7/site-packages/kantts/preprocess/data_process.py", line 200, in process_data
se_model,
File "/opt/conda/lib/python3.7/site-packages/kantts/preprocess/se_processor/se_processor.py", line 67, in process
sess = onnxruntime.InferenceSession(se_onnx, sess_options=opts)
File "/opt/conda/lib/python3.7/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 360, in __init__
self._create_inference_session(providers, provider_options, disabled_optimizers)
File "/opt/conda/lib/python3.7/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 397, in _create_inference_session
sess = C.InferenceSession(session_options, self._model_path, True, self._read_config_from_model)
onnxruntime.capi.onnxruntime_pybind11_state.InvalidProtobuf: [ONNXRuntimeError] : 7 : INVALID_PROTOBUF : Load model from /work/voiceswork/raymond/pretrain/orig_model/basemodel_16k/speaker_embedding/se.onnx failed:Protobuf parsing failed.
# python -c "import torch;torch.zeros([1]).cuda();torch.version.cuda;torch.backends.cudnn.version();torch.cuda.is_available()"
求解,在线等
