
问题1:Flink CDC两台服务器传输数据,相互间无法访问对方的数据库,但服务器ip可以ping通,
无法使用flink sql模式同步
如果我在source端使用flink cdc捕获数据,在sink端部署kafka接收数据,是否可行?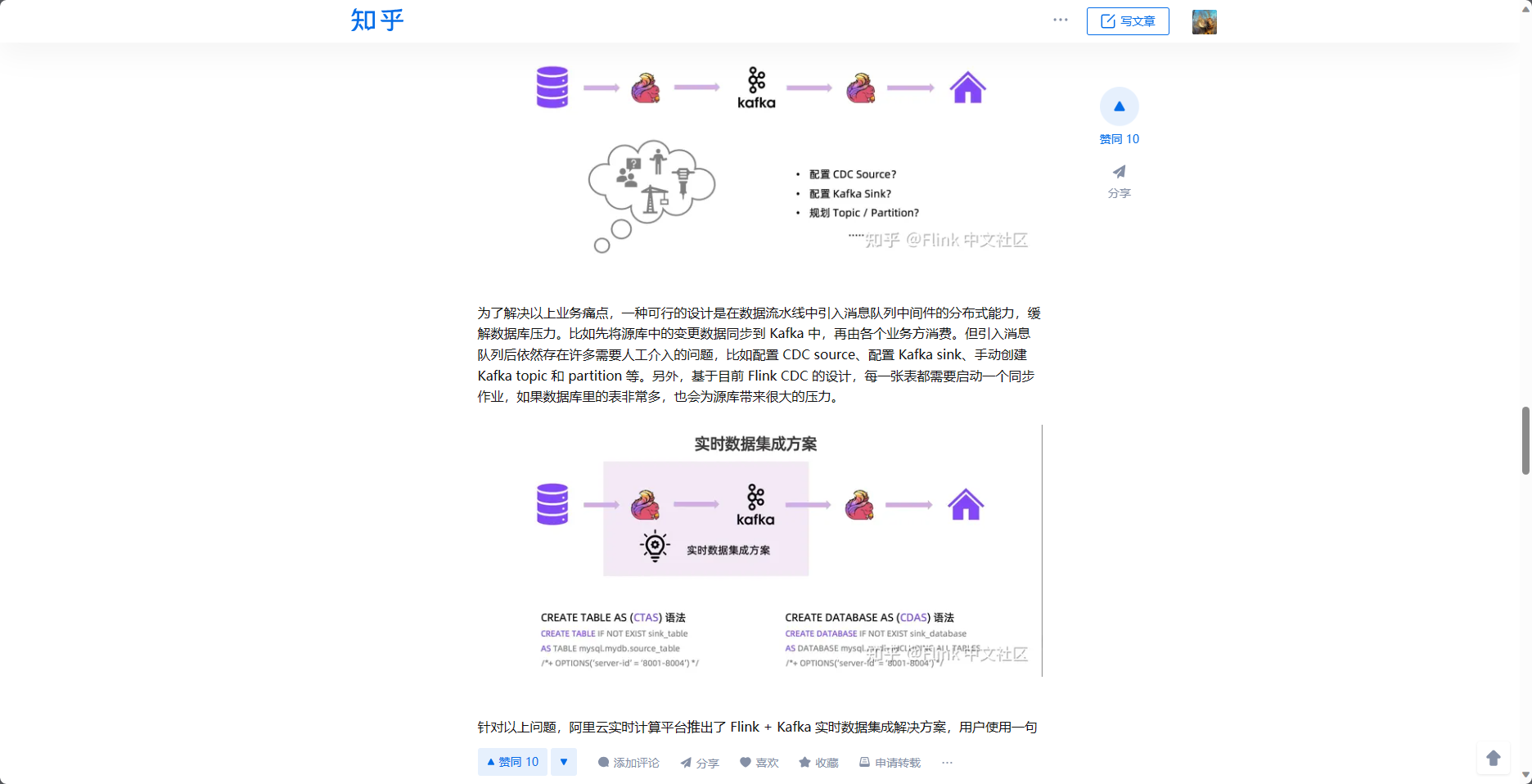
类似于这种模式?
问题2:采用这种模式?source端使用debezium解析日志,传输到kafka中,sink使用flink接收数据?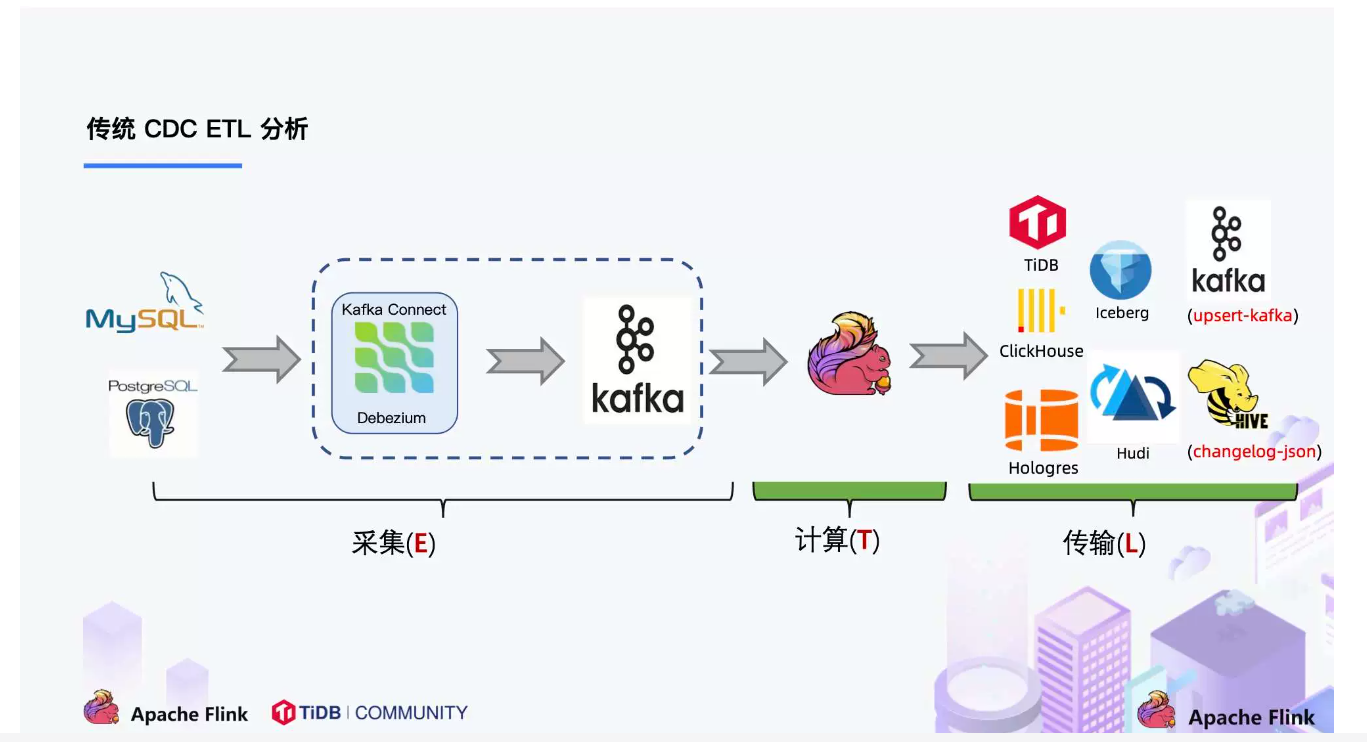
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
回答1:你不想一个task一张表的话建议直接用debezium
回答2:sink和source都是kafka-mysql-connect,不用flink, 直接用kafka + debezium mysql connnect
https://docs.confluent.io/kafka/overview.html
https://docs.confluent.io/platform/current/installation/docker/installation.html
https://github.com/confluentinc/cp-all-in-one/blob/7.5.0-post/cp-all-in-one-kraft/docker-compose.yml%E5%8F%AF%E4%BB%A5%E5%8F%82%E8%80%83%E8%BF%99%E4%B8%AAcompose
https://docs.confluent.io/platform/current/installation/docker/config-reference.html
https://github.com/confluentinc/cp-all-in-one/blob/7.5.0-post/cp-all-in-one-kraft/docker-compose.yml用这个compose比较省时间, 你自己按开源的玩坑会很多, 虽然这个compose的部分组件是商业版本的, 但是一样用的,此回答整理自钉群“Flink CDC 社区”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

