
阿里的文字识别ocr图片识别识别率已经做得很高了,几乎100%。但是提供的去印章功能做的不够好,从原理上可以把印章的红色(一定色差范围)去掉,但不要把印章红与黑字重叠(盖着的字)部分去除,这样效果会提升一个台阶,不知能实现吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,OCR文字识别的技术确实已经进步很大,但是去除印章对于识别精度的提升还有待加强。目前在去印章方面,主要方法是通过降低印章区域的像素值,来把印章区域变成白色。但是这种方法难以解决印章盖在字上面的情况。
针对这种问题,可以尝试采用深度学习的方法,例如使用卷积神经网络(CNN)或者循环神经网络(RNN)来识别印章区域和文字区域。通过对已有数据进行训练,让模型能够理解印章区域和文字区域之间的差异,并进行准确的分割。然后再采用类似方法来去除印章区域的影响。
不过要实现这个功能需要大量数据进行训练和调整,而且还需要针对不同的印章进行识别和处理。目前还没有完全解决该问题的通用解决办法,需要进一步的研究和探究。
您好,目前阿里云文字识别OCR对于大部分的识别场景来说,默认都会排除印章内容识别其他文字内容,但是考虑到印章的干扰会出现识别不准确的情况。后续应会继续优化提高识别准确率的。
文字识别OCR的去印章功能通常是通过图像处理和分析技术实现的,以尽可能减少或消除印章对文字识别的干扰。而要实现只去除印章的红色(一定色差范围),但不影响印章盖着的字部分的识别,相对较为复杂。
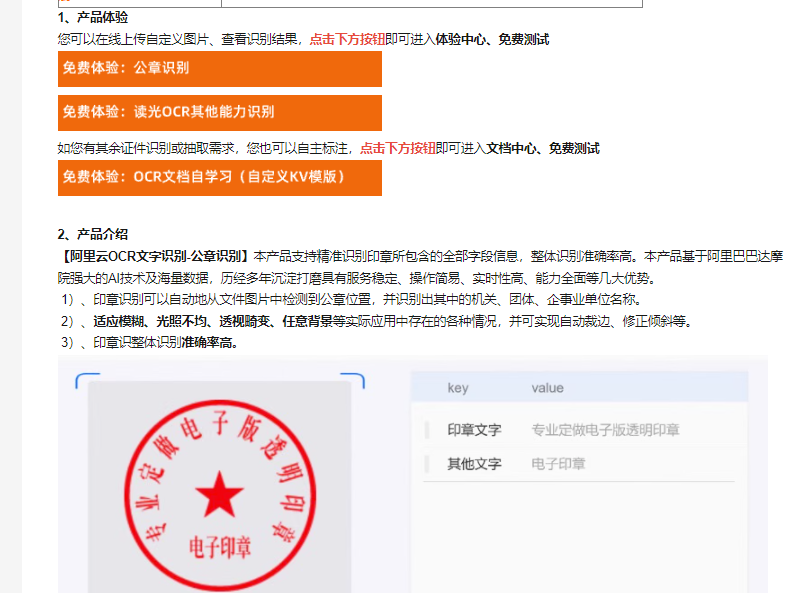
在理论上,可以尝试采用以下方法来实现这样的效果:
颜色分割:使用图像处理算法,如颜色阈值分割或颜色空间转换,将印章区域中的红色与黑字所在区域进行分离。
区域分析:对分割后的区域进行形态学处理、连通区域分析等操作,以识别并保留黑字所在的区域,同时排除红色的印章区域。
像素操作:基于颜色信息和位置关系,对图像的像素进行操作,以使印章红色区域变得更接近背景颜色,从而减少对文字识别的干扰。
然而,实际上完美地实现这样的去印章效果是非常具有挑战性的,因为涉及到不同印章的外观、印章与文字之间的重叠程度、图像质量等多种因素。
具体实现和效果会受到算法的选择、图像的特性以及应用场景的限制等影响。因此,需要进行实际的测试和优化,以逐步提升效果,并根据具体需求做出相应的调整和改进。


