
在文字识别OCR我们实际上有四行数据,但是识别成三行了,再一个就是空格问题,怎么解决?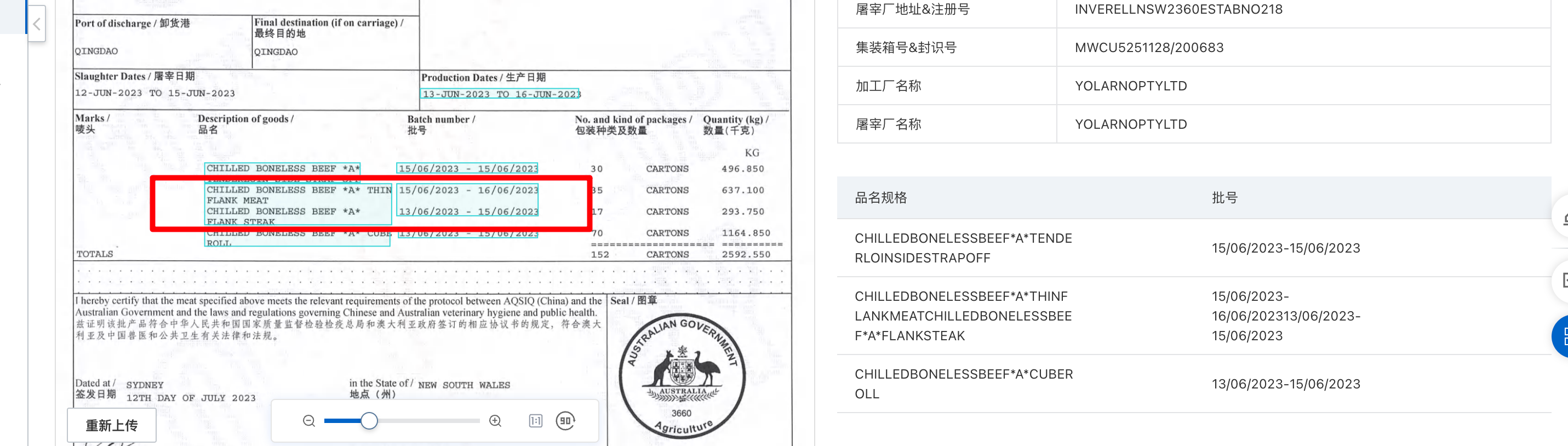
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,阿里云文字识别OCR的识别结果可能会因为不同的因素而出现误差,如果识别结果中出现了错误或者缺失,可以尝试以下解决方法:
调整图片:尽可能保证图片清晰度、亮度、对比度等,以提高识别准确率。
直接拆分数据行:将一行数据拆分成两行或多行,然后再进行识别。
设置区域:在阿里云OCR API中提供了“区域识别”功能,可以通过在图片上框选区域进行针对性识别。
去除空格:将原始图片中的空格去除或者将空格替换为其他字符,再进行识别。
以上方法可以根据具体情况进行尝试,以获得更好的识别结果。具体可以参考官网的具体介绍:https://help.aliyun.com/document_detail/270960.html?spm=a2c4g.295341.0.0.6b2e3a53a8auyq
您好,文字识别OCR的识别准确率受限于图片质量,图片尺寸、图片大小以及识别算法的影响,
识别准确率并不能达到100%,建议您可以接收到识别后返回的数据进行人工审核修正。或者通过文字识别OCR文档自学习自定义表格模版来进行标注、训练等来提高识别准确率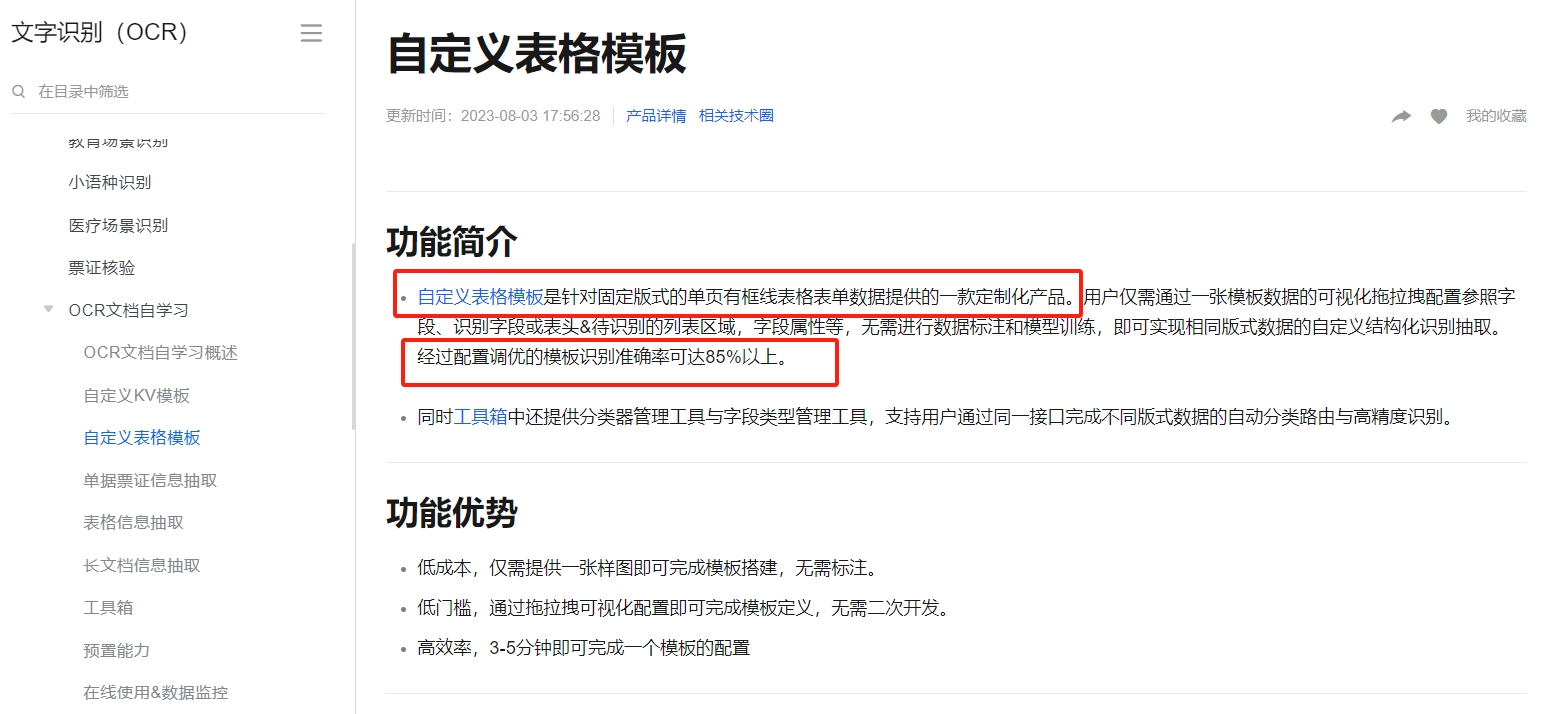
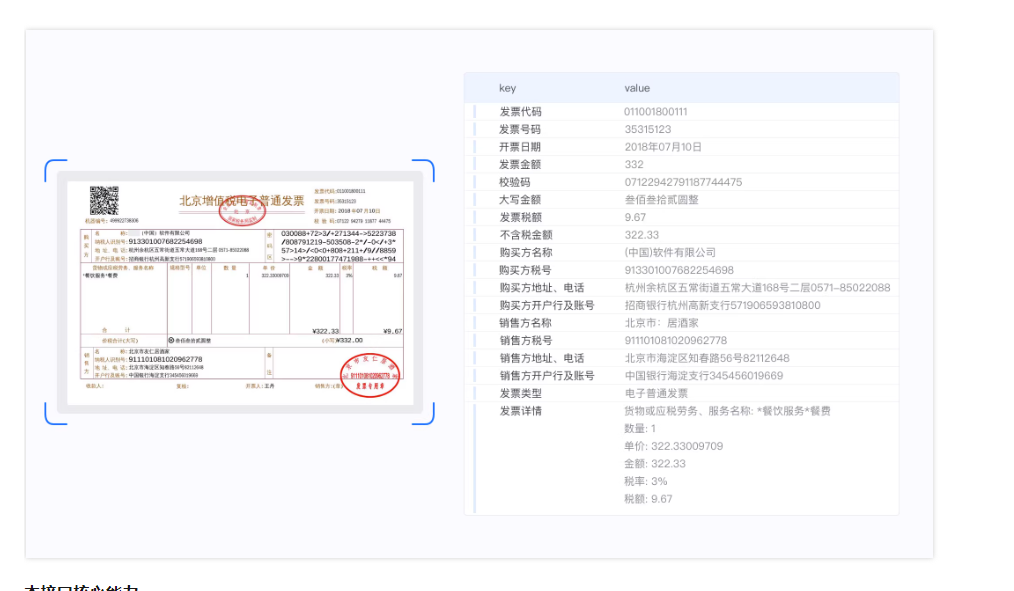
阿里云OCR文字识别服务在识别文本时,可能会因为文本的排列方式、字体、字号、字形等因素影响识别效果。如果您的文本中存在多行数据,但是OCR服务只识别了其中的部分行,或者识别出的文本中存在空格问题,您可以尝试以下方法:
使用高质量的文本图片:确保文本图片清晰、对比度高、背景干净。
调整OCR服务的参数:根据实际需求调整OCR服务的参数,例如识别精度、字符分割精度等。
使用增强功能:如果OCR服务仍然无法正确识别文本,您可以尝试使用OCR服务的增强功能,例如文本增强、图像增强等。
使用多标注功能:如果OCR服务无法正确识别文本,您可以尝试使用OCR服务的多标注功能,手动标注文本的行数和空格位置。
可以新增一些训练数据哈。用新的数据集新建标注任务标注,再讲之前的标注任务和新增的标注任务放到一起训练就好。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”
在文字识别OCR中,如果您的文本实际上有四行数据,但被识别成了三行,或者遇到了空格问题,可以尝试以下方法来解决这些问题:
调整图像预处理:OCR的准确性受到输入图像的质量和预处理的影响。尝试调整图像的对比度、亮度和清晰度等参数,以获得更好的结果。您可以尝试使用图像处理软件或OCR服务提供商提供的图像增强功能,优化图像质量。
检查文本布局和格式:检查原始文本的布局和格式是否符合OCR模型的预期。确保每一行文本都有适当的间距和显示方式,以便OCR能够正确解析每一行。如果文本之间缺少明显的分隔符(例如换行符),则可能导致OCR无法正确识别。
使用自定义规则和模板:针对具体的文本结构和格式,您可以创建自定义规则和模板,指导OCR识别过程。通过设定特定的规则,如行数、字数、字符位置等限制条件,可以帮助OCR更准确地解析文本,并将其正确分成相应的行数。
尝试不同的OCR引擎和参数设置:不同的OCR引擎可能对于特定的文本结构和格式有不同的表现。尝试使用不同的OCR引擎,并调整参数设置,以找到最适合您需求的配置。
手动校正和后处理:如果OCR结果仍然存在问题,您可以手动进行校正和后处理。对于缺失的行或空格问题,可以在识别结果上手动添加或调整相应的文本内容,并进行必要的格式修正。


