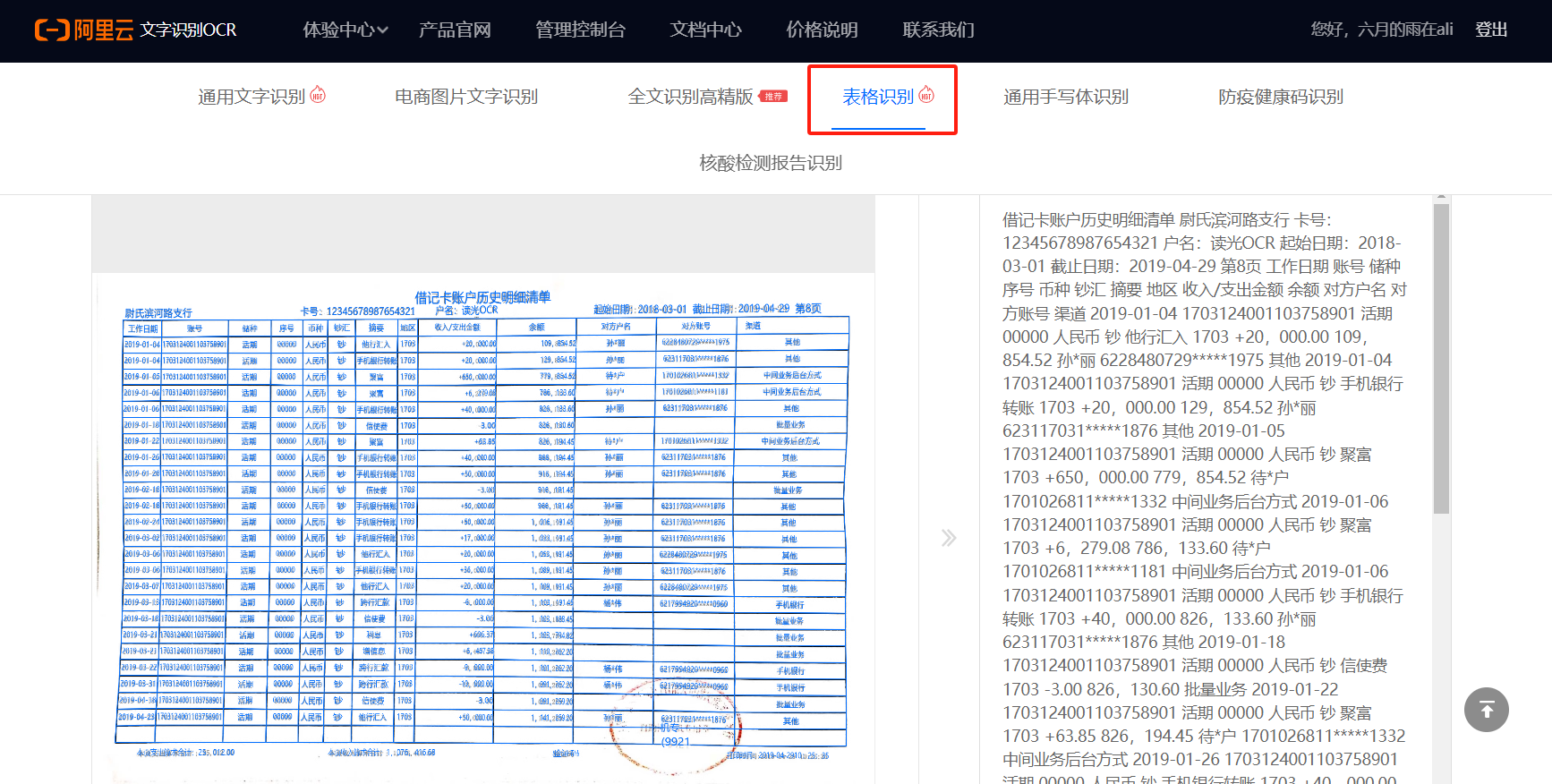
有个识别配料表的需求,现在测试使用通用文字识别功能碰到问题,配料都在左边,换行了,然后就把右边的产地插入到了语序中导致结果不可用,这种情况文字识别OCR有什么办法可以避免吗?需求就是需要得到完整的配料表。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
针对您提到的识别配料表的需求,如果使用通用文字识别功能存在问题,可以考虑使用更加专业的OCR技术和算法来解决。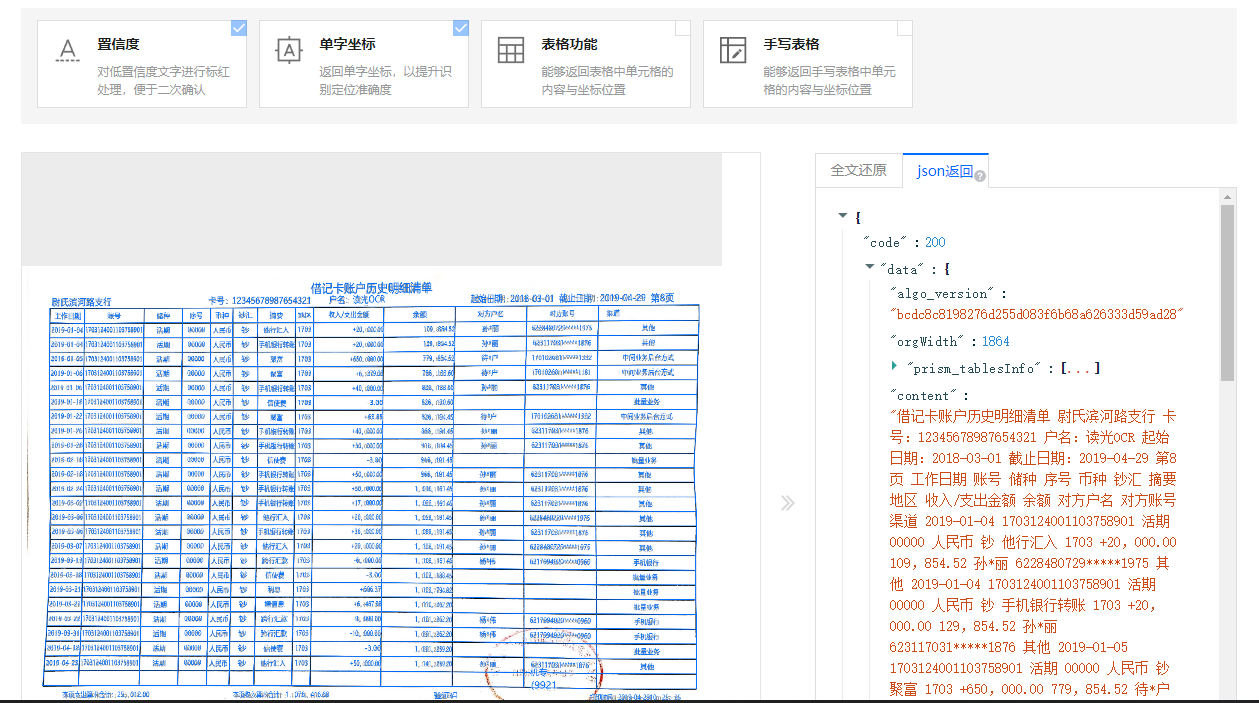
具体来说,您可以考虑使用针对特定领域的OCR技术和算法,例如针对食品配料表的OCR技术和算法。这些技术和算法通常会针对特定的场景和应用进行优化,例如识别特定的文字格式、排版、字体等,从而提高识别准确率和可靠性。
此外,您还可以考虑使用深度学习技术和算法,例如基于卷积神经网络(CNN)的OCR技术和算法。这些技术和算法通常可以学习和模拟人类视觉系统,从而更好地处理复杂的文字识别任务,例如识别不同字体、排版、背景等。
最后,您还可以考虑使用自然语言处理(NLP)技术和算法,例如语义分析、文本理解等,来处理识别出的文字结果,从而更好地提取和理解配料表的信息。
修改图像预处理:在将配料表图像传递给OCR引擎之前,尝试进行一些预处理操作,例如扫描和检测文本区域、分割文本行、去除干扰等。这可以提高文字识别准确性并避免换行带来的问题。

在使用通用文字识别功能时,遇到配料表中换行导致右边的产地插入到语序中的问题是比较常见的。以下是一些可能的解决办法:
修改图像预处理:在将配料表图像传递给OCR引擎之前,尝试进行一些预处理操作,例如扫描和检测文本区域、分割文本行、去除干扰等。这可以提高文字识别准确性并避免换行带来的问题。
调整OCR参数:OCR服务通常提供一些参数选项,例如语言模型、识别算法等,您可以尝试调整这些参数以改善识别结果。有些OCR服务还支持自定义词典或规则,您可以根据具体情况添加一些规则或关键词,以指导识别引擎正确处理特定语序。
使用专业的OCR解决方案:通用文字识别服务虽然功能强大,但对于复杂的布局或特殊需求,可能无法满足期望。考虑使用专门针对配料表或特定场景的OCR解决方案,这些解决方案通常具备更高的精度和适应性。
手动处理或后处理:如果自动识别无法满足需求,可以考虑手动处理或使用其他算法来整理和解析配料表。例如,基于规则的文本解析或自然语言处理技术能够更好地处理语序问题。