
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

根据图中的文档,可以实现mysql数据写入和写出的任务,创建一个数据流。使用mysql为数据源配置账号和密码。设置完毕后,点击运行任务即可开始数据抽取和写入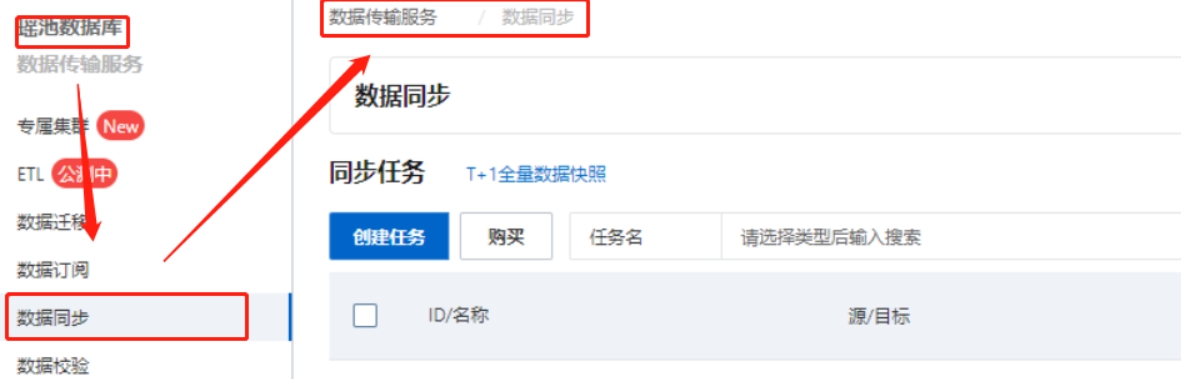
楼主你好,阿里云DI(Data Integration)可以很方便地帮助我们实现MySQL数据抽取写入DataHub的任务。
首先,在阿里云DI管理控制台中创建一个数据流任务。
在任务的数据源设置中,选择MySQL作为数据源,填写相应的数据库信息和账号密码。
在目标数据源设置中,选择DataHub作为目标数据源,配置相应的DataHub信息,包括数据集名称、AccessKeyId和AccessKeySecret等。
在数据同步设置中,可以选择增量同步或全量同步,并设置同步的时间间隔等参数。
设置完毕后,点击运行任务即可开始数据抽取和写入。
需要注意的是,阿里云DI的使用需要一定的费用支出,具体费用情况可以参考阿里云DI官方文档。同时,数据同步过程中可能会出现一些问题,需要根据具体情况进行排查和解决。
阿里云流式数据服务DataHub是流式数据(Streaming Data)的处理平台,提供对流式数据的发布、订阅和分发功能,让您可以轻松构建基于流式数据的分析和应用。通过数据传输服务DTS(Data Transmission Service),您可以将RDS MySQL同步至阿里云流式数据服务DataHub,帮助您快速实现使用流计算等大数据产品对数据实时分析。
支持同步的SQL操作

操作步骤
进入同步任务的列表页面。
登录DMS数据管理服务。
在顶部菜单栏中,单击集成与开发(DTS)。
在左侧导航栏,选择数据传输(DTS) > 数据同步。
在同步任务右侧,选择同步实例所属地域
单击创建任务,配置源库及目标库信息。
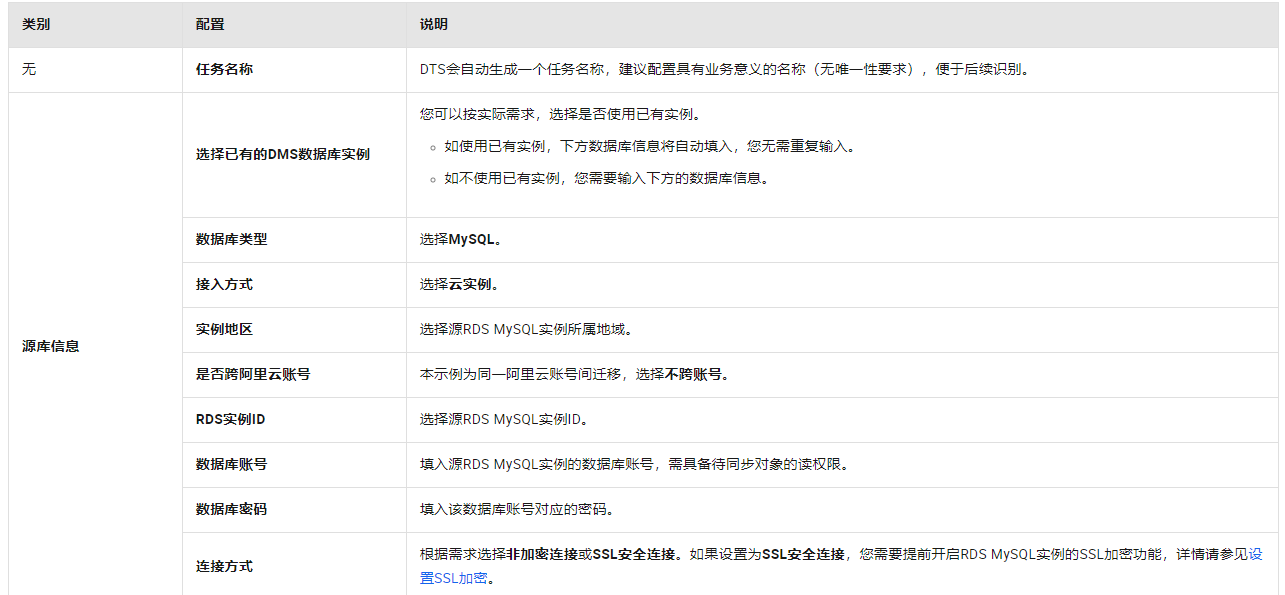
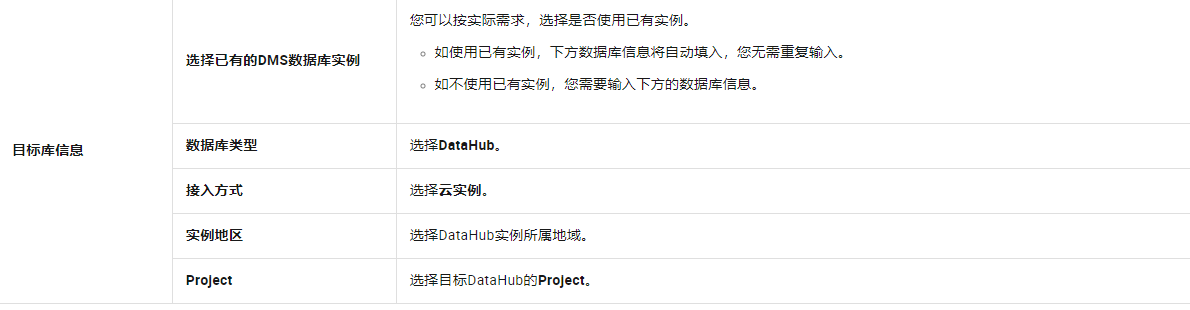
配置完成后,单击页面下方的测试连接以进行下一步。
配置任务对象及高级配置。
可选:将鼠标指针放置在已选择对象框中待同步的Topic名上,鼠标右键单击对象后出现编辑,然后在弹出的对话框中设置Shardkey(即用于分区的key)。
配置完成后,单击页面下方的下一步高级配置。
保存任务并进行预检查。
预检查通过率显示为100%时,单击下一步购买。
在购买页面,选择数据同步实例的计费方式、链路规格,详细说明请参见下表。
配置完成后,阅读并勾选《数据传输(按量付费)服务条款》。
单击购买并启动,同步任务正式开始,您可在数据同步界面查看具体任务进度。
要将MySQL数据抽取并写入DataHub,你可以按照以下步骤操作:
连接到MySQL数据库:使用适合你的编程语言和数据库连接库,建立与MySQL数据库的连接。提供正确的主机名、端口号、用户名、密码和数据库名称等参数。
查询MySQL数据:使用SQL查询语句从MySQL数据库中检索需要的数据。根据你的需求编写相应的SQL查询,以选择所需的表和字段,并执行查询操作。
解析查询结果:处理查询结果并提取出需要的数据。根据返回的结果集格式,通过编程语言提供的API或库解析结果集,将数据转换为合适的数据结构,如列表、字典等。
连接到DataHub:使用DataHub提供的SDK或API,建立到DataHub的连接。提供正确的Endpoint、AccessKeyId、AccessKeySecret等凭证信息,确保能够访问DataHub服务。
创建Topic和Shard:在DataHub上创建一个新的Topic,并配置适当数量的Shard,以便进行后续的数据写入操作。
将数据写入DataHub:使用DataHub提供的API或SDK,将从MySQL中获取的数据逐条写入DataHub的Topic中。确保数据按照指定格式进行序列化,并指定目标Topic、Partition和Shard等信息。
处理错误和异常情况:在数据写入过程中,处理任何可能发生的错误和异常情况,如连接失败、数据转换错误或写入超时等。进行适当的错误处理和日志记录,以确保数据一致性和可靠性。
要将MySQL数据抽取并写入Datahub,你可以按照以下步骤进行:
安装所需的库和驱动程序:
mysql-connector-python、pymysql等)和Datahub SDK。连接到MySQL数据库:
查询MySQL数据:
创建Datahub客户端:
遍历查询结果并写入Datahub:
关闭连接和资源释放:
要将MySQL数据抽取并写入DataHub,您可以按照以下步骤操作:
安装所需的库和工具:
pip install mysql-connector-pythonpip install datahub-client连接到MySQL数据库:
```python
import mysql.connector
config = {
'user': 'your_username',
'password': 'your_password',
'host': 'your_host',
'database': 'your_database'
}
cnx = mysql.connector.connect(**config)
cursor = cnx.cursor()
3. 查询MySQL数据:
```python
query = "SELECT * FROM your_table"
cursor.execute(query)
# 获取查询结果
rows = cursor.fetchall()
datahub_config = {
'project_name': 'your_project_name',
'access_key': 'your_access_key',
'secret_key': 'your_secret_key'
}
datahub = DataHub(**datahub_config)
source = datahub.create_source('mysql_source')
source.add_mysql_table(
table_name='your_table',
column_mappings=[
{'name': 'column1', 'type': 'STRING'},
{'name': 'column2', 'type': 'INT'},
# ...
],
rows=rows
)
job = source.start()
5. 等待任务完成,然后关闭MySQL连接和DataHub客户端:
```python
# 等待任务完成
job.wait()
# 关闭MySQL连接
cursor.close()
cnx.close()
# 关闭DataHub客户端
datahub.stop()
以上代码示例展示了如何从MySQL数据库中抽取数据并将其写入DataHub。请根据您的实际情况修改连接信息、查询语句和数据表结构。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


