
系统环境:CentOS7.9 flink环境:flink-1.16.2 flink cdc版本:2.14.1
Java版本:11.0.17.0.1
数据源:oracle 19c;目标库:oracle 19c

flink接触的少,基础薄弱。 flink集群和flink sql都已正常启动,传输数据前我必须要建一张虚表吗?还有数据源和目标库的连接信息保存在哪里?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC实时同步的基本步骤如下:
准备数据源和目标数据库:您需要先在数据源和目标数据库上创建相应的表结构,并在其中插入一些测试数据。
安装并配置Flink CDS:根据官方文档,您需要先从Apache Flink官网下载Flink CDS的JAR包,然后将其添加到Flink的classpath中。接下来,您还需要在Flink SQL中定义CDS的驱动程序。
建立虚表:在Flink SQL中,您需要先创建一个虚拟表,该表包含所有要同步的表的所有字段。例如,如果您有一个名为“orders”的表,并且希望将其与“customers”表一起同步,那么您应该创建一个名为“all_fields”的虚拟表,该表包含“orders”和“customers”表的所有字段。
定义同步策略:在Flink SQL中,您需要定义如何将数据从数据源传递到目标数据库。这通常涉及到定义过滤条件、排序规则等。
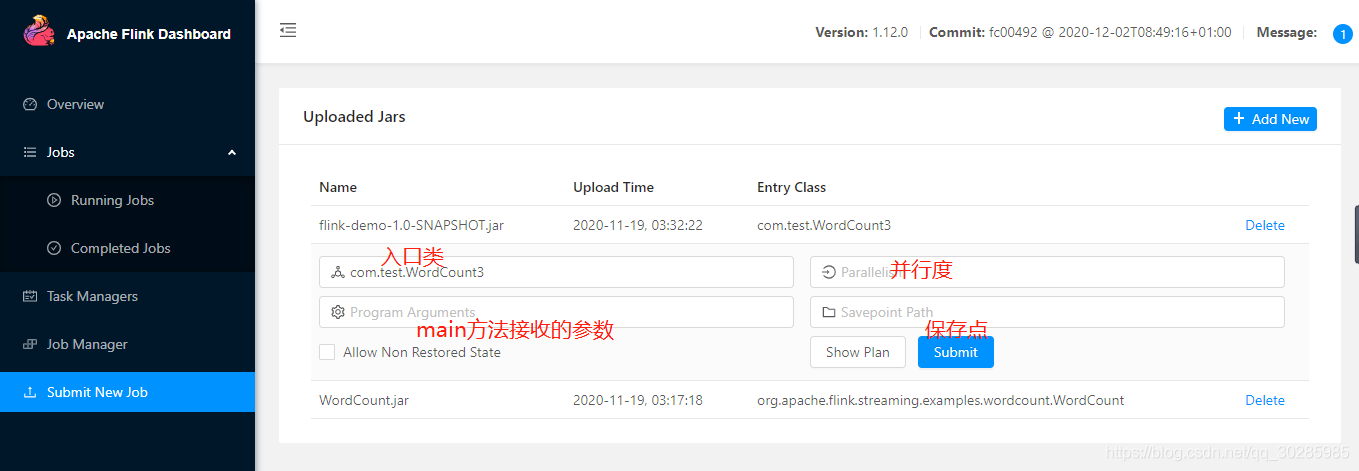
提交作业:最后,您需要将上述SQL语句提交给Flink集群执行。一旦作业开始运行,Flink将会自动读取数据源上的数据,并将它们写入目标数据库。
关于数据源和目标库的连接信息,它们通常会被保存在Flink SQL的配置文件中,或者直接作为参数传递给Flink作业。具体的位置取决于您使用的Flink版本和部署方式。

