
文字识别OCR混贴发票识别中(一图多发票)有推荐的算法吗?(目前待截取图片的第一个角的x坐标取的是x0-x3的最小值,第一个角的y坐标取的是y0-y3的最小值,第二个角的x坐标取的是x0-x3的Max(x)-Min(x),,第二个角的y坐标取的是Max(y)-Min(y)),,,然后原图的第一个角的x坐标、y坐标以及第二个角的x坐标、y坐标 我就不知道了)
graphics2D.drawImage(image, minX, minY, maxX-minX, maxY-minY, orgWidth, orgHeight, srcWidth, srcHeight, null);
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
阿里云混贴发票识别,是阿里云官方自研OCR文字识别产品,适用于获取多种发票集合在一个页面的场景,需要获取多种发票上的关键信息。
阿里云OCR产品基于阿里巴巴达摩院强大的AI技术及海量数据,历经多年沉淀打磨,具有服务稳定、操作简易、实时性高、能力全面等几大优势。
发票信息(subMsgs字段)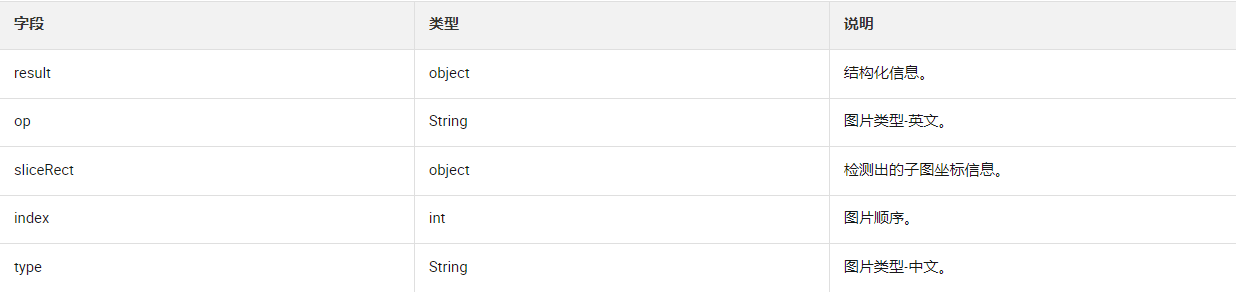
结构化信息(result字段)
在阿里云文字识别OCR混贴发票识别中涉及到截取子图的算法会有多种选择。不同的算法可以根据具体的需求和场景来确定。这里提供一个可能的算法示例:
获取最小和最大坐标值:根据返回的sliceRect参数,获取四个坐标点的x和y的最小值和最大值。即:minX = min(x0, x1, x2, x3),minY = min(y0, y1, y2, y3),maxX = max(x0, x1, x2, x3),maxY = max(y0, y1, y2, y3)。
计算截取区域的宽度和高度:根据最小和最大坐标值,计算截取的区域宽度和高度。即:width = maxX - minX,height = maxY - minY。
进行截取操作:根据计算得到的宽度、高度以及sliceRect的原图信息(orgWidth、orgHeight、srcWidth、srcHeight),使用相应的截取函数对原图进行截取。在提供的代码示例中,使用graphics2D.drawImage()对原图进行截取操作,具体参数设置请参考相关文档。
这个算法示例仅供参考,根据实际场景和需求,您可以针对混贴发票识别的具体情况进行适当的调整和优化。
在文字识别OCR中处理混贴发票的一图多发票问题,有一些常见的算法和技术可供参考。以下是几种常见的算法:
基于边缘检测和轮廓分析:使用边缘检测算法(如Canny边缘检测)来提取发票的边缘信息,然后利用轮廓分析算法(如OpenCV中的轮廓分析功能)来检测和分割不同的发票区域。
基于图像分割:使用图像分割算法(如基于阈值或聚类的方法)将图片中的发票区域从背景中提取出来,并单独处理每个发票区域。
基于模板匹配:创建发票模板,然后使用模板匹配算法(如OpenCV中的模板匹配功能)来在图片中寻找与模板相似的区域,以定位发票位置。
基于深度学习和目标检测:使用深度学习技术,如卷积神经网络(CNN)或目标检测算法(如YOLO、Faster R-CNN等),对图片进行训练和推理,以检测并定位发票区域。
根据您描述的截取方式,可以根据最小和最大的x、y坐标来确定发票区域的位置和大小。在使用Java的Graphics2D.drawImage方法时,可以根据这些坐标参数进行截取操作。
需要注意的是,具体选择哪种算法或技术取决于您的需求和实际情况,如发票样式、图像质量等。同时,这些算法和技术可能需要结合其他图像处理、分析和OCR技术来实现完整的混贴发票识别系统。
楼主你好,阿里云文字识别OCR混贴发票识别中推荐使用基于深度学习的物体检测算法,例如Faster R-CNN、YOLO、SSD等。这些算法能够有效地对图片中的多个发票区域进行检测和定位,并输出每个发票区域的坐标信息。同时,对于待截取图片的第一个角和第二个角的坐标信息,可以通过计算发票区域左上角和右下角的坐标来获得。具体代码实现可能因算法不同而有所差异。


