
大数据计算MaxCompute pyodps 对大量数据进行逐条处理,我才用的是dataframe 转为pandas dataframe的方式进行处理,但是效率太低,能否提供合理的方案?运行时间长,每一类数据有上百万条,有大概上万类,处理逻辑就是df = DataFrame(o.get_table(self.table4)),然后对df根据类进行filter得到小的sub_df,最后转化sub_df为pandas dataframe进行逐条处理
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果您在大数据计算MaxCompute中使用pyodps处理大量数据时,通过将DataFrame转换为Pandas DataFrame进行逐条处理的方式效率较低,我可以提供一些合理的方案来提高处理效率:
利用MaxCompute的计算能力:MaxCompute具有强大的计算能力和分布式处理能力,可以利用它来处理大规模数据。您可以尝试在MaxCompute中使用MaxCompute SQL或MaxCompute SQL任务,直接在MaxCompute上进行数据过滤和处理,而无需将数据转换为Pandas DataFrame。
利用MaxCompute的分区功能:如果您的数据按照某种特定的分类进行分区,可以考虑在MaxCompute中创建分区表,并按照分类字段进行分区。这样,您可以通过针对特定分区的查询来处理数据,而无需加载整个数据集。
使用MaxCompute的UDF(用户自定义函数):如果您的处理逻辑需要自定义函数或特定的处理操作,可以考虑在MaxCompute中编写UDF来实现。UDF可以在MaxCompute分布式环境中高效地处理大量数据。
批量处理数据:尽量避免逐条处理数据,而是尝试批量处理数据。您可以根据分类字段将数据分组,并在每个组上进行批量处理。这样可以减少数据转换和处理的开销。
调整数据处理流程:如果可能,尝试优化数据处理流程,将一些处理步骤前置或合并,减少不必要的数据转换和重复操作。
效率低是指运行时间太长还是啥,衡量的指标是什么呢。现在大概是什么样的处理逻辑.慢的原因大概是这样,pyodps的sdk,访问odps表都会根据pyodps的def逻辑转为udf,有的也会转为内建函数,比如agg之类的,def自定义的没有映射内建函数的逻辑,跑起来,效率可能会有慢。目前您这边这个场景,我建议可以这样。方式1:目前的PyODPS任务,因为pandas是开源的,所以逻辑快慢我们调整不了。可以加上几个参数调一下转化后的SQL任务。看看主要是map阶段慢了,还是reduce阶段慢了,调一下参数值。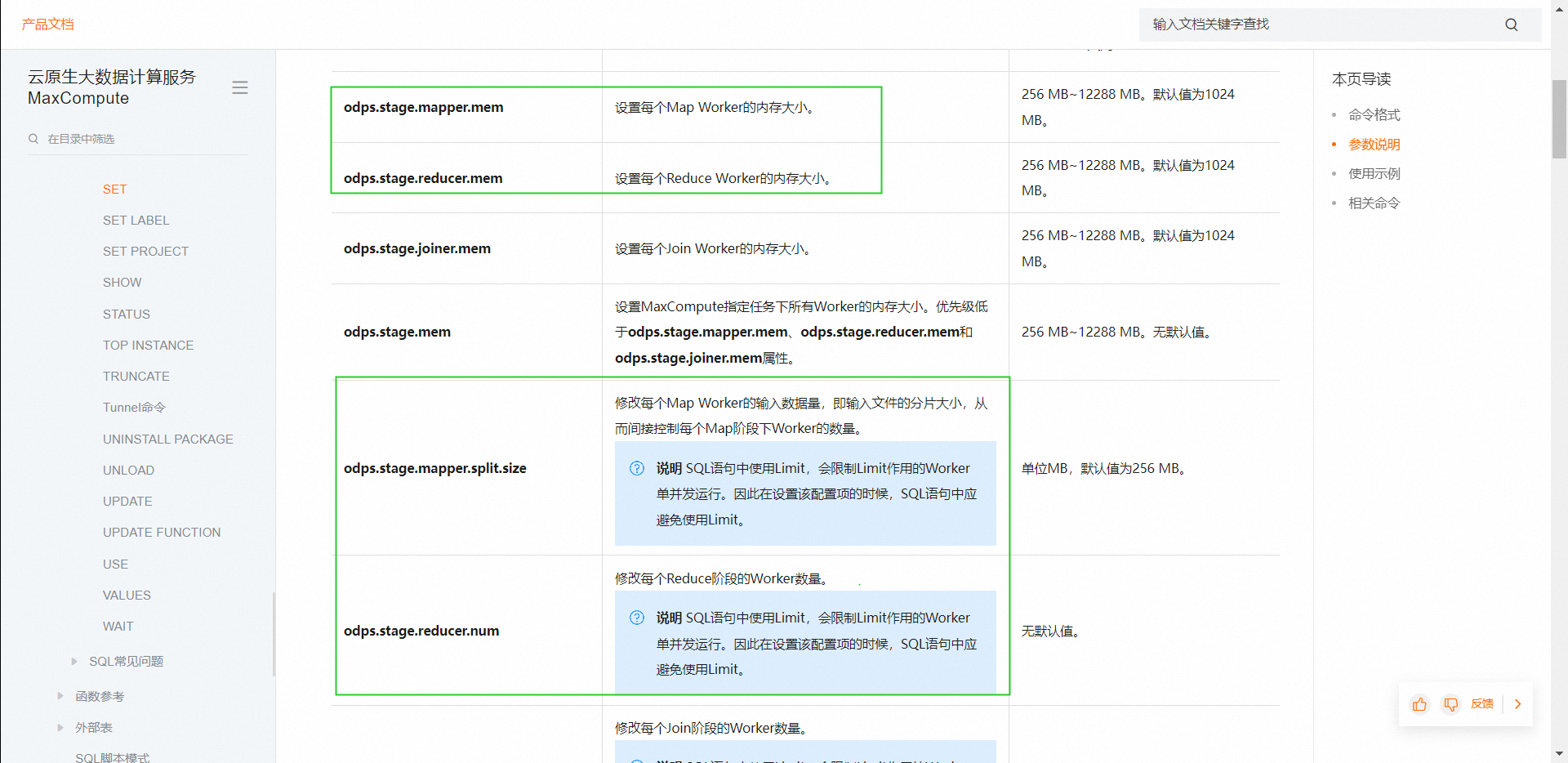
加参数方式:https://help.aliyun.com/zh/maxcompute/user-guide/sql?spm=a2c4g.11186623.0.i34#section-ntm-54m-cfb获取log view方式:https://help.aliyun.com/zh/maxcompute/user-guide/task-instances?spm=a2c4g.11186623.0.0.277f613digbIlx#section-dmm-mtm-cfb方式2:看下能否使用ODPS的DataFrame实现逻辑,应该会效率高一点。方式3:如果上述方式能不能很好的改善效率,看看能否转成SQL的方式,使用ODPS的内建函数,直接SQL处理,效率会好一些。,此回答整理自钉群“MaxCompute开发者社区2群”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


