文字识别OCR这种手写的文字,识别准确率很低呀,如何调整?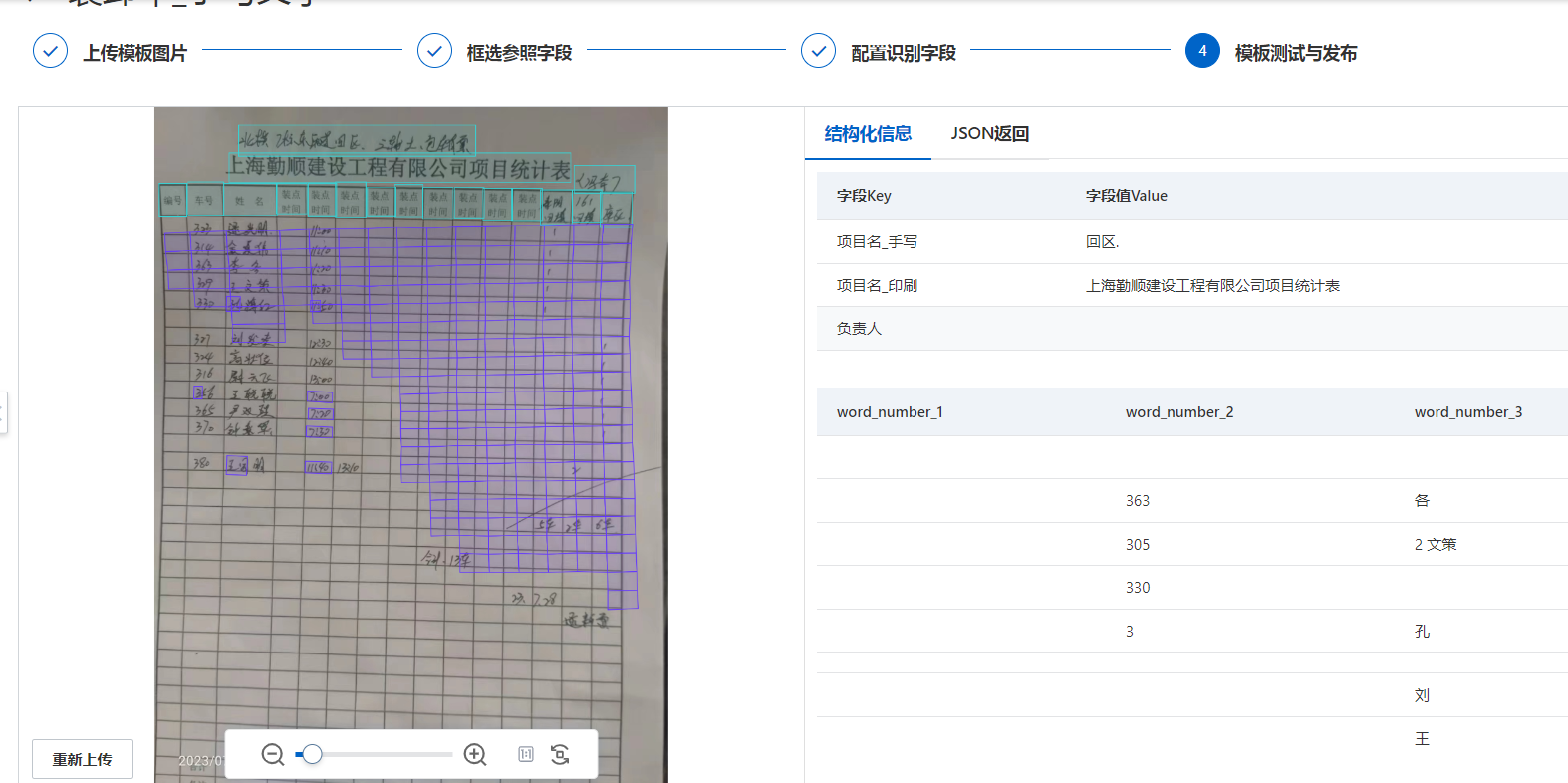
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
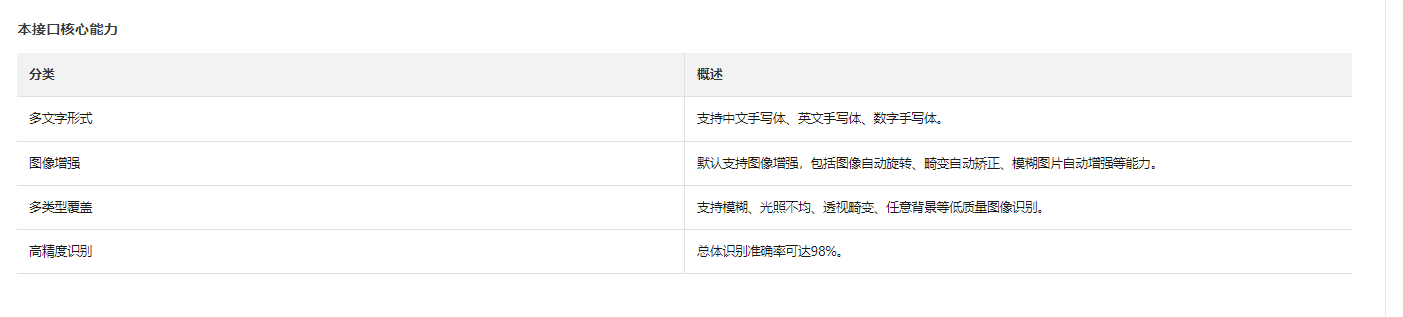
尽可能在使用阿里云OCR服务进行识别之前,了解和了解手写字体的特点。避免使用过于奇特或潦草的手写字体,因为这些字体可能会影响识别准确性。建议尽可能使用规范的、容易辨认的手写字体。
楼主你好,阿里云文字识别OCR对手写文字的识别准确率会受到多方面因素的影响,包括手写字体的清晰度、字迹的整齐程度、背景干扰、图片质量等等。以下是一些调整准确率的方法:
提高图片质量:手写文字图片的质量越高,识别准确率越高。因此,可以尽量选择高清晰度的图片,并确保图片清晰、无噪点和阴影。
选择合适的识别模型:针对手写文字的识别,阿里云OCR提供了手写文字识别接口。在使用API时,可以选择相应的识别模型,例如“手写通用识别模型”或“中英文手写识别模型”等。
增加字典:OCR系统支持添加自定义词典,可以根据需求,将需要识别的字典添加到系统中,提高识别准确率。
调整识别参数:通过调整识别参数,如图片旋转角度、矫正阈值、文字大小等,可以提高OCR的准确率。
练习字迹规范:对于手写的数据,字迹的规范程度会影响准确率,因此在写作时尽量规范写字,可以有效提高识别准确率。
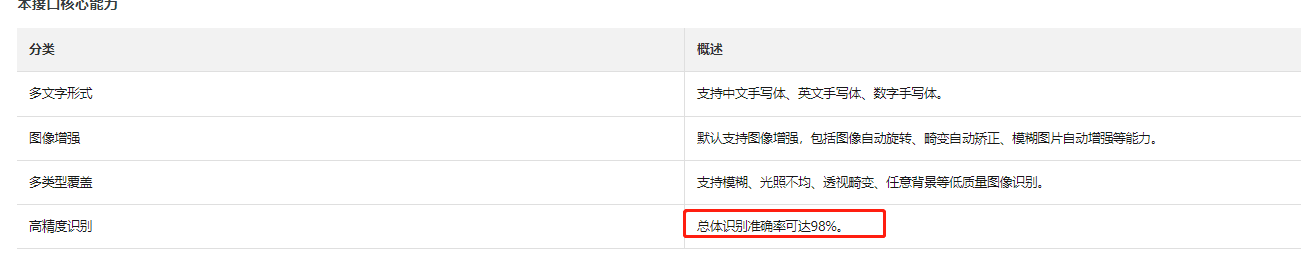
需要注意的是,由于手写文字的复杂性和多样性,OCR系统对于手写文字的识别准确率可能无法完全达到人工水平,因此在使用OCR进行手写文字识别时,需要根据实际需求进行权衡和使用。
对于OCR文字识别来说,手写文字的识别确实较难,准确率通常不高。
主要有几个原因:
手写文字样式多样:笔画粗细不均、连体字多等,增加复杂度
训练样本不足:市面上手写文字样本有限,难以收集大量训练数据
模型偏向于印刷体:现有的OCR模型多为识别印刷体texto而设计
存在空格与抖动:手写文字间存在额外的间距和抖动,增加噪音
为了提高手写文字识别的准确率,可以采取以下方法:
收集更多的手写文字图片用于训练
收集手写字、词、句的图片,训练模型,可有效增强识别能力。
使用专门的手写文字识别模型
部分OCR提供商有针对性的手写文字识别模型,可试用试试。
通过数据增强生成更多样本
如随机扭曲、翻转、添加噪声等技术,来扩充数据集。
调整模型超参数
比如增加LSTM的层数和神经元数量,减小学习速率,延长训练周期。
使用更深的神经网络
如ResNet、DenseNet等,可以增强模型学习能力。
要大幅提高手写文字识别,最好的方法仍是收集广泛的训练样本。
模型本身的调节效果一般。
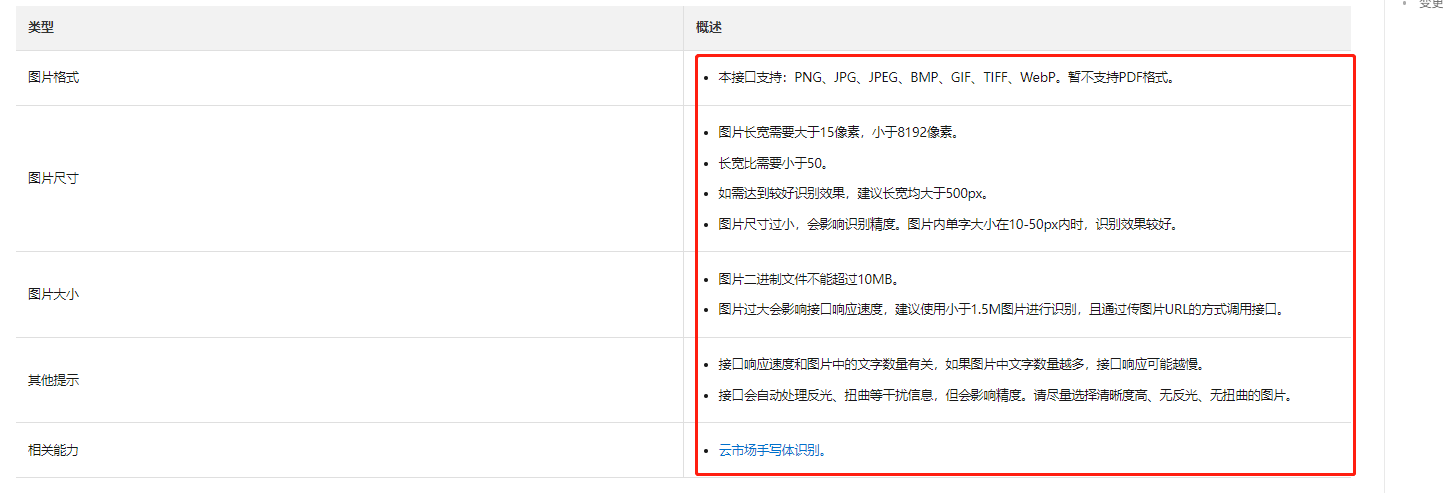
提高图像质量:OCR技术依赖于图像质量,如果图像模糊、噪声大或者光线不足,识别准确率就会降低。因此,您可以尝试使用更清晰、更干净的图像来提高OCR的识别效果。
调整模板:根据OCR识别的结果,调整模板的大小、位置、角度等,以提高识别准确率。
调整参数:OCR技术需要一些参数来控制识别的效果,例如阈值、最小字体大小等,可以尝试调整这些参数,以提高识别准确率。
使用深度学习技术:深度学习技术可以提高OCR的识别准确率,例如卷积神经网络、循环神经网络等,可以尝试使用这些技术来改进OCR的识别效果。
这个是底层手写体ocr模型可能需要优化,另外非常潦草的手写体文字,精度很难保证,建议使用正楷字书写。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”
您好,文字识别OCR手写体识别效果受多方的影响,比如图片尺寸的影响以及图片内文字大小的影响,另外还受图片拍摄质量的影响都比较大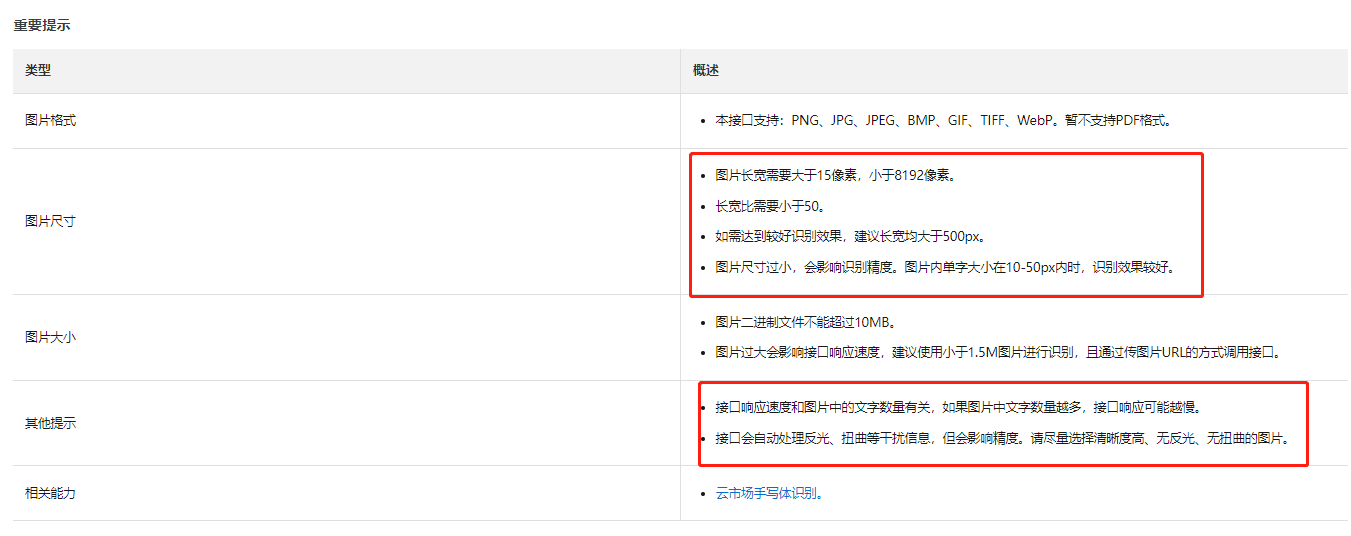
建议您通过OCR文档自学习的形式进行模板标注,数据训练,从而来提高识别精确度。
确实,手写体文字识别的准确率相对较低,因为手写字迹的差异性和多样性较大。然而,以下是一些可以尝试以提高手写体文字识别准确率的方法:
数据预处理:在进行文字识别之前,可以对图像进行预处理来优化识别结果。例如,可以应用图像增强技术、去噪处理、图像平滑等操作,以提高图像质量。
字体样本收集:收集更多不同风格的手写字体样本,并将其添加到训练数据中,以使模型更加全面并能够识别更多的手写字体。
模型训练和调优:使用机器学习或深度学习的方法,基于收集的手写字体样本进行模型训练。通过调整模型参数、增加训练样本数量、采用更复杂的网络结构等方式来提高模型准确率。
多模型融合:使用多个不同的OCR模型进行识别,并将它们的结果进行融合,以提高整体的准确率。可以尝试使用不同的OCR引擎或算法,并采取投票、加权平均等方法来综合各模型的输出。
后处理和纠错:在识别结果中应用后处理技术,例如使用语言模型或规则引擎进行纠错和校正,以减少识别错误。