
问题1: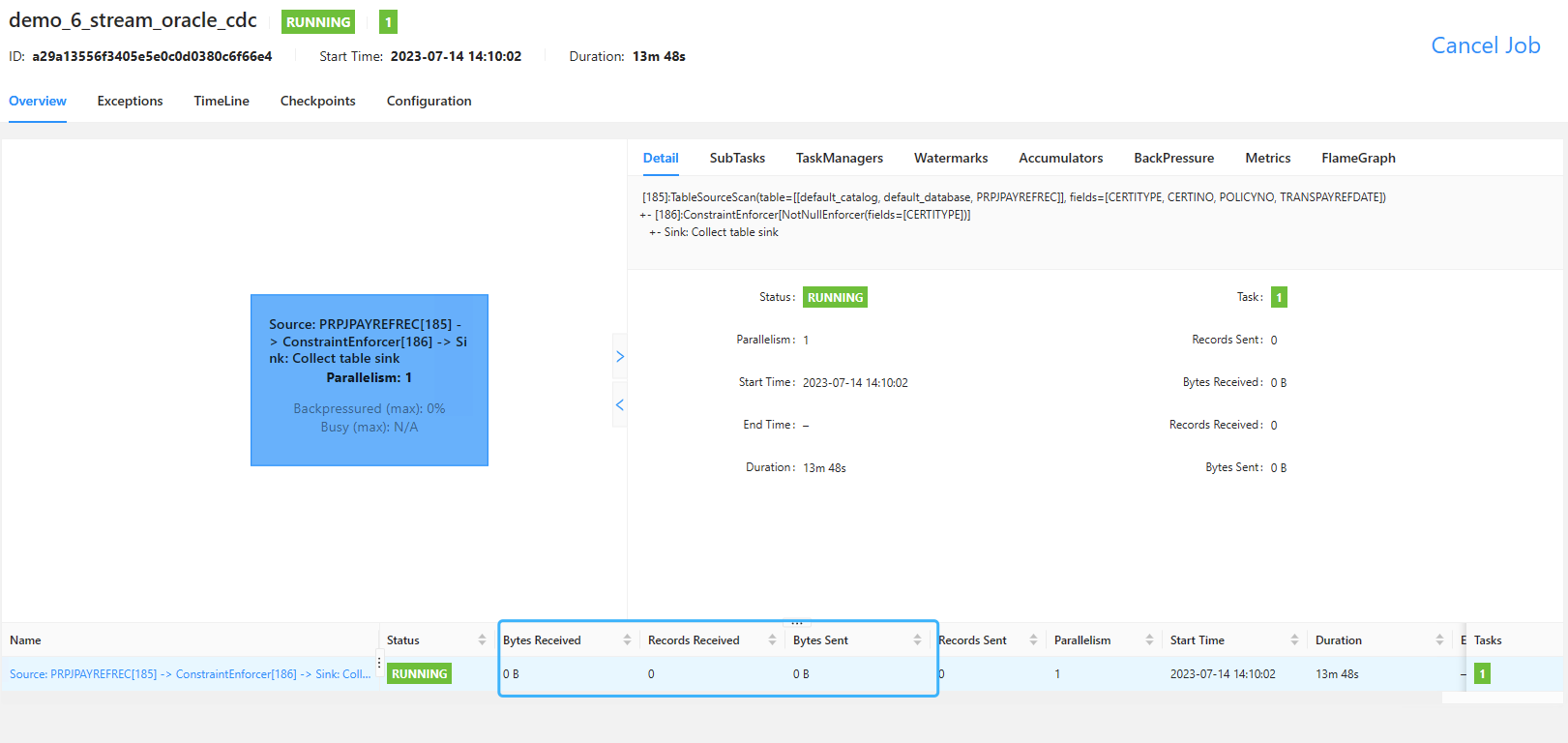
请问Flinkcdc中oracle cdc 一直没有数据,怎么排查?
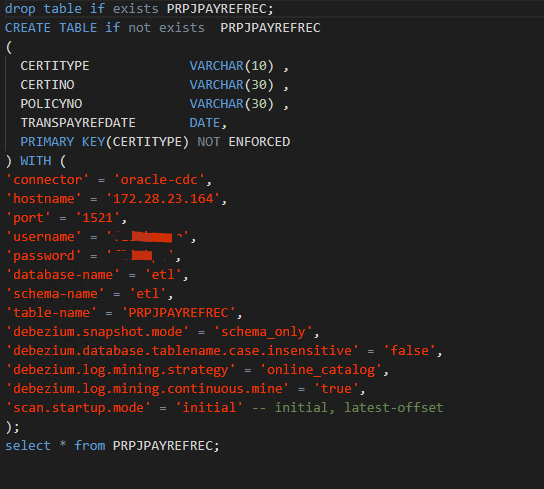
问题2: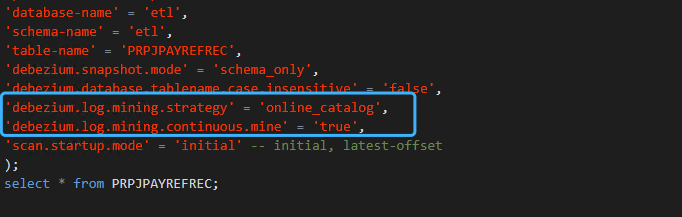
我加了这俩参数了,还是读取不到数据。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink CDC 中,如果 Oracle CDC 数据源一直没有数据,可能是由于多种原因导致的。以下是一些可能的原因和排查方法:
数据库连接问题:可能是连接到 Oracle 数据库时出现了问题,导致无法获取 CDC 数据。您可以检查 JDBC URL、用户名、密码等配置项是否正确,以及网络连接是否正常。
Oracle LogMiner 配置问题:可能是 Oracle LogMiner 配置有误,导致无法正确读取 redo log。您可以检查 Oracle LogMiner 的相关配置参数,例如 logminer.dictionary_filename、logminer.continuous_mine、logminer.startSCN 等。
Oracle 表配置问题:可能是 Oracle 表的配置有误,导致表中的数据无法被 Oracle LogMiner 检测到。您可以检查表的状态是否正常,是否有足够的权限进行操作,以及表的大小是否超过了 Oracle LogMiner 的限制。
CDC 引擎配置问题:可能是 Flink CDC 引擎的配置有误,导致无法正确解析 CDC 数据。您可以检查 CDC 引擎的相关配置参数,例如 checkpoint、parallelism、event filter 等。
数据格式不匹配:可能是 Oracle 数据库中的数据格式与 Flink 表的数据格式不匹配,导致无法正确解析数据。您可以检查表的数据类型
"回答1:OracleCDC的归档日志增长很快,且读取log慢,导致捕捉数据变化延迟较大
解答:可以使用在线挖掘的模式,不写入数据字典到 redo log 中,但是这样无法处理 DDL 语句(但是对于生产环境,一般不会进行 DDL 操作,业务上也仅需要捕捉 DML 操作即可)。生产环境默认策略读取 log 较慢,且默认策略会写入数据字典信息到 redo log 中导致日志量增加较多,可以添加如下 debezium 的配置项。 'log.mining.strategy' = 'online_catalog','log.mining.continuous.mine' = 'true'。如果使用 SQL 的方式,则需要在配置项中加上前缀 'debezium.',即:
'debezium.log.mining.strategy' = 'online_catalog',
'debezium.log.mining.continuous.mine' = 'true'此回答整理至钉群“Flink CDC 社区”。"
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


