
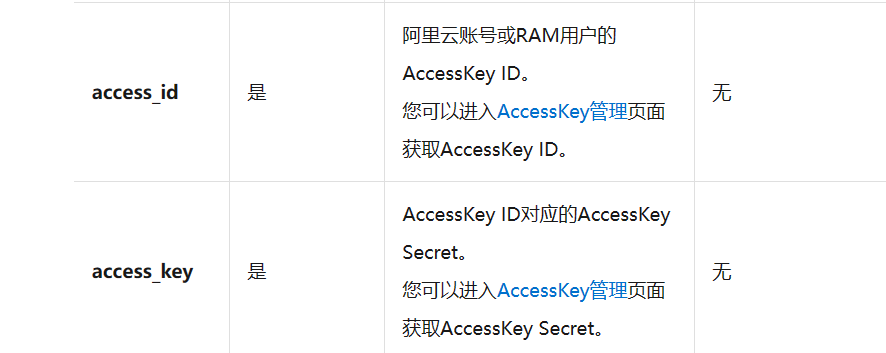
DataWorks中id是对应的哪个 key参数可以不写吗?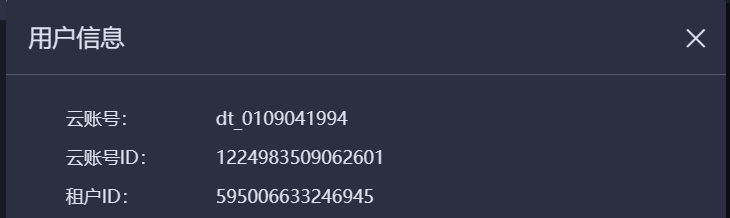
id是哪个账号
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中,id参数通常是用来指定某个资源的唯一标识符,具体对应哪个key参数需要根据具体的场景和操作而定。通常情况下,如果不想指定id参数,可以尝试通过其他参数来进行操作,如名称、路径等。
以下是一些常见场景和操作的key参数说明:
创建表:在创建MaxCompute表时,可以使用odps.tables.create()方法,其中可用的key参数包括project、table、comment、schema等。如果不指定id参数,可以使用project和table参数来指定表所在的项目和表名称。
上传数据:在上传数据到MaxCompute时,可以使用odps.put()方法,其中可用的key参数包括project、table、partition、compress等。如果不指定id参数,可以使用project和table参数来指定上传数据的目标表。
下载数据:在从MaxCompute下载数据时,可以使用odps.get_table()方法获取目标表的信息,其中可用的key参数包括project、table等。如果不指定id参数,可以使用project和table参数来指定下载数据的目标表。
在DataWorks中,ID可以对应不同的参数,具体取决于您使用的功能和接口。以下是几种常见情况:
Project ID(项目ID):在DataWorks中,每个项目都有一个唯一的项目ID。在进行一些操作时,需要指定该项目ID作为参数。例如,获取某个项目的详情、创建任务等。
Instance ID(实例ID):在DataWorks中,每个任务实例都会生成一个唯一的实例ID。在查询或管理任务实例时,需要指定该实例ID作为参数。
DataFlow ID(数据流ID):如果您使用了Data Integration中的数据流功能,每个数据流也会有一个唯一的数据流ID。在进行数据集成任务的配置时,需要指定对应的数据流ID作为参数。
至于账号是哪个ID,需要进一步明确您具体指的是何种账号。通常情况下,DataWorks中的账号可能包括:
应该是必填的 odpscmd具体咨询一下odps同学看看 群公告可以找到,云账号id,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


