
文字识别OCR中,这是要转化下编码嘛?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您好,文字识别OCR支持图片Url链接或者body图片二进制文件,不支持将本地路径的文件直接读取,您可以将本地文件上传到对象存储OSS,然后获取请求地址后作为Url参数来调用。
" with open(r'D:\Image\高精版\get_img.jpg', 'rb') as f: # 以二进制读取本地图片
data = f.read() body =data
此回答整理自钉群“【官方】阿里云OCR公共云客户交流群”。"
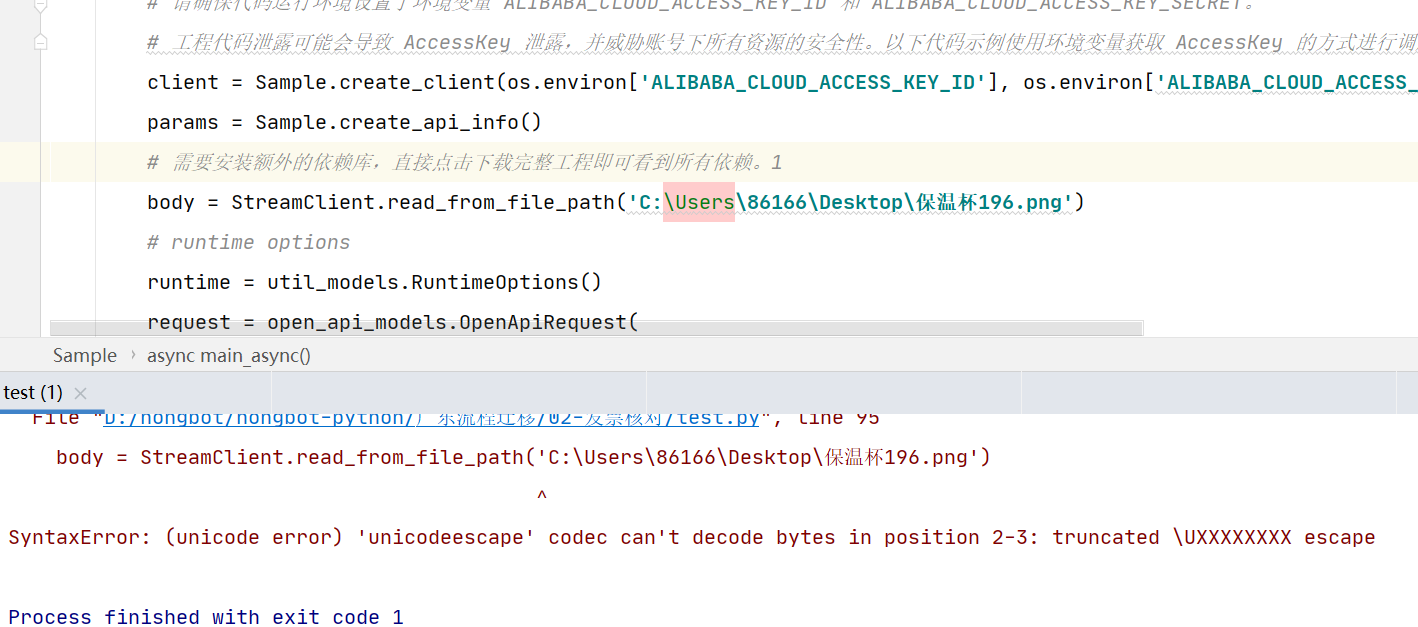
您收到了SyntaxError: (unicade eran) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXx escape的错误消息,那么说明您的代码中存在一个无法解码的Unicode转义序列。这种错误通常是由于您尝试使用一个无效的Unicode转义序列引起的。为了解决这个问题,您可以尝试使用一个有效的Unicode转义序列,或者尝试使用其他方式来处理该字符。另外,您也可以查看代码中的其他部分,以确定是否存在其他可能导致该错误的问题。
通常情况下,在使用阿里云文字识别OCR服务时,不需要进行编码转化。阿里云提供的OCR接口接受的请求参数和响应结果都是以UTF-8编码传输的,因此在使用API时,您只需将请求参数按照UTF-8编码进行传输即可。同样,接收到的响应结果也是以UTF-8编码返回的,您可以直接处理。
这个错误是因为在 Windows 系统中,路径分隔符是反斜杠\,而反斜杠是 Python 中的转义字符,所以在字符串中表示反斜杠需要使用两个反斜杠\。
您可以尝试将路径中的反斜杠\替换为正斜杠/,或者使用双反斜杠\表示反斜杠,例如:
Copy
U:/nongpot/nongpot-pytnon/Line y5Streamclient.read_from_file_path('c:/Users/86166/Desktop/保温杯196.png')
或者:
Copy
U:/nongpot/nongpot-pytnon/Line y5Streamclient.read_from_file_path('c:\Users\86166\Desktop\保温杯196.png')
这样就可以避免路径中反斜杠的转义问题,确保程序可以正确读取图片文件。
在文字识别OCR中,遇到类似 "SyntaxError: (unicode error unicodeescape' codec can't decode bytes in position 2-3: truncated uxxxxxxxx escape" 的错误通常是由于编码问题导致的。这个错误提示表明在字符串中存在无效的Unicode转义字符。
要解决这个问题,您可以尝试以下方法:
转义字符处理:检查可能引起错误的字符串,并确保其中的转义字符(以反斜杠 \ 开头的字符)被正确处理。例如,如果字符串中包含反斜杠,您可以使用双反斜杠 \ 或原始字符串 r"\" 来表示转义字符。
编码声明:如果您的代码文件中包含非ASCII字符,可以在代码文件的开头添加编码声明,指定文件使用的编码方式。例如,对于UTF-8编码,可以在文件开头添加 # -*- coding: utf-8 -*-。
字符串前缀处理:如果您在字符串中使用了特殊的前缀,如 'u'、'r'、'b' 等,可能会导致编码错误。请确保在字符串前缀中使用有效的前缀标记,并根据需要进行适当的修改或删除。
使用合适的文本编辑器:确保您使用的文本编辑器支持您所使用的编码方式,并正确地保存和加载文件。不同的编辑器可能具有不同的默认编码设置。


