
请问在使用机器学习PAI ProphetBatchOp的时候,希望保留uuid列,但是这个列只是做为标记使用,有什么办法可以做到?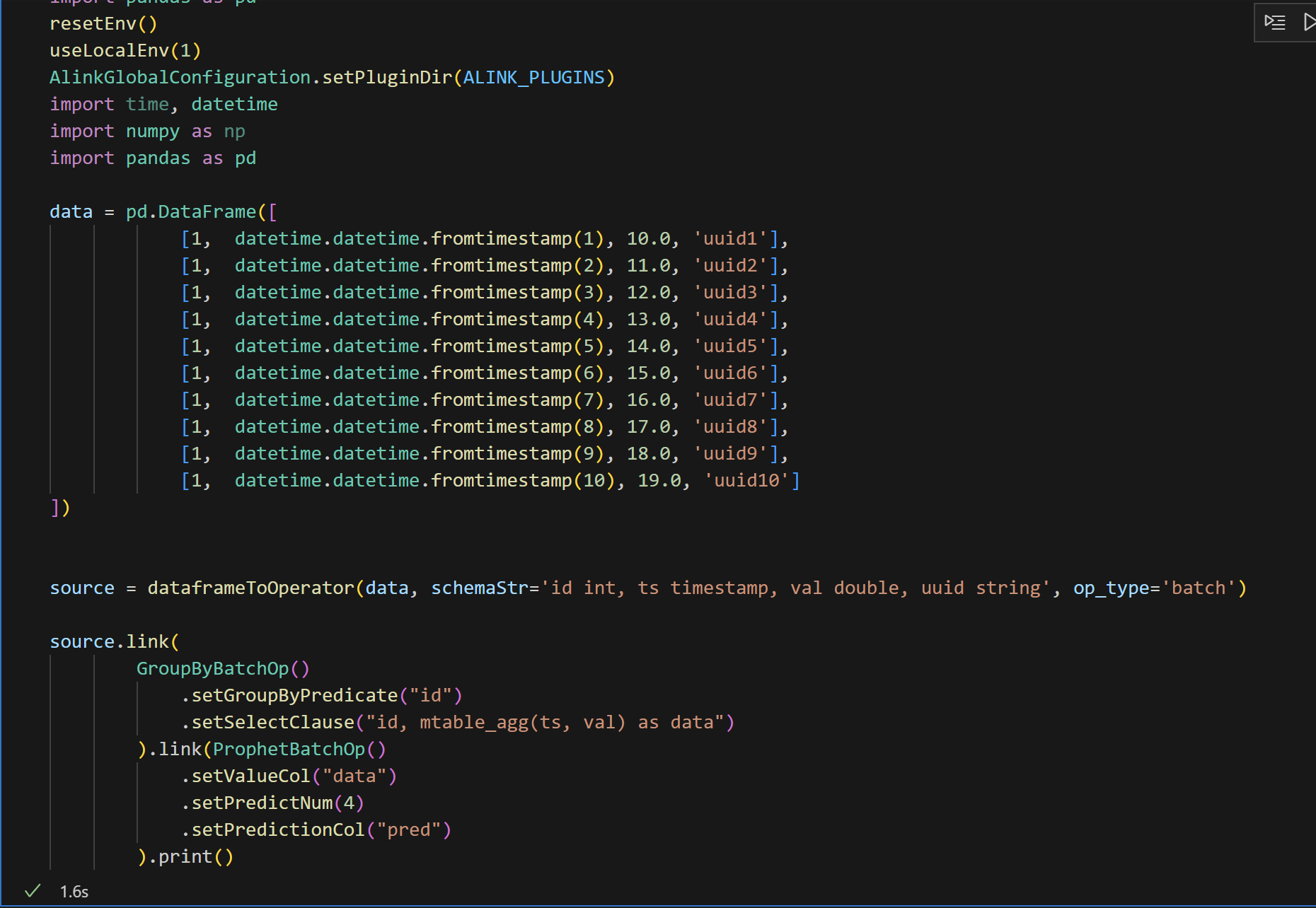
GroupbyBatchOp select里加上uuid会导致这个报错,因为我其实并不想把uuid做为groupby的依据
请问该如何解决?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
当你使用机器学习PAI中的ProphetBatchOp时,想要保留uuid列作为标记列而不参与模型训练和预测时,可以考虑以下方法:
Drop列:在使用ProphetBatchOp之前,可以在数据处理流程中使用DropColumnsBatchOp来删除uuid列。这样,在ProphetBatchOp中只会使用到需要的列进行训练和预测,而uuid列将被舍弃。
保留列但不用于训练和预测:如果你希望在ProphetBatchOp中保留uuid列,并将其作为标记列,但又不希望其参与模型的训练和预测过程,可以在数据处理过程中将uuid列从特征集合中移除或设置为无效值。ProphetBatchOp通常接受一个featureCols参数,可以将uuid列排除在外,仅选择需要的特征列进行模型训练和预测。
这个需要groupbyOp后先joinBatchOp原表,再输入ProphetBatchOp。
此回答整理自钉群“Alink开源--用户群”。
在使用机器学习PAI ProphetBatchOp时,如果您希望保留uuid列,但不将其作为分组关键字,可以通过以下方法实现:
使用Select操作符来选择需要保留的列,并将其命名为新的列名,例如uuid列可以选择为uuid_new:
ProphetBatchOp prophetBatchOp = new ProphetBatchOp()
.setTimeCol("time")
.setPrimaryKeyCol("key")
.setDsCol("ds")
.setPredictionCol("prediction");
BatchOperator result = prophetBatchOp.linkFrom(inputBatchOp)
.select("uuid as uuid_new", "other_cols_to_keep")
.as("input")
.groupBy("key")
.select("input.uuid_new as uuid", "other_cols_to_keep", "prediction");
上述代码做了以下操作:
使用select操作选择需要保留的列,包括uuid列,并将其重命名为uuid_new列。
对select操作的结果进行重命名为input表。
对input表进行分组操作,根据key列进行分组。
对分组后的结果再次进行select操作,选择需要保留的列,并将uuid_new列重命名为uuid列。
使用setReservedCols方法将uuid列添加到保留列列表中(前提是uuid列在原始数据中存在):
reasonml
Copy
ProphetBatchOp prophetBatchOp = new ProphetBatchOp()
.setTimeCol("time")
.setPrimaryKeyCol("key")
.setDsCol("ds")
.setPredictionCol("prediction")
.setReservedCols("uuid");
BatchOperator result = prophetBatchOp.linkFrom(inputBatchOp)
.groupBy("key")
.select("uuid", "other_cols_to_keep", "prediction");
上述代码做了以下操作:
使用setReservedCols方法将uuid列添加到保留列列表中。
对原始数据进行分组操作,根据key列进行分组。
对分组后的结果进行select操作,选择需要保留的列,包括uuid列。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。


