
DataWorks中EMR-MR节点WordCount案例是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
DataWorks中的EMR-MR节点WordCount案例是一个基于Hadoop生态系统的大数据 WordCount 案例,用于展示DataWorks平台的数据加工和处理能力。
该案例涉及的数据源包括一组文本文件,每个文件中包含一篇文章或文档,其中包含了各种单词和词汇。通过DataWorks的EMR-MR节点,可以将这些数据源加载到Hadoop集群中,并进行一系列的数据处理操作。
在该案例中,DataWorks的EMR-MR节点将使用MapReduce程序来对文本数据进行处理。具体的处理流程包括:
数据分片:将文本数据按照特定的规则进行分片,例如按照文件路径或文件名进行分片。 数据读取:使用MapReduce程序从分片后的数据中读取文本内容,并将文本内容解析为单词。 单词计数:对每个单词进行计数,并输出结果。 结果汇总:将各个分片的结果进行汇总,得到最终的单词计数结果。 通过该案例,用户可以了解DataWorks平台在大数据处理方面的能力和优势,包括数据分片、数据读取、数据处理和结果输出等。同时,该案例也可以帮助用户掌握使用DataWorks进行数据加工和处理的基本流程和方法。
实现:基于EMR在DataWorks上使用MR节点实现分布式单词个数统计(以存储在OSS上为例)。 OSS 原始数据: 准备原始数据 input01.txt hadoop emr hadoop dw hive hadoop dw emr 登录oss控制台,在OSS bucket中建/emr/datas/wordcount02/inputs目录,存入原始数据。顺便新建一个/emr/jars目录,等下存放jar资源。 
预期结果: word count dw 2 hadoop 3 emr 2 hive 1 IDE编写MR 打开IDEA,新建一个项目。 添加pom依赖
org.apache.hadoop
hadoop-mapreduce-client-common
2.8.5
org.apache.hadoop
hadoop-common
2.8.5
编写程序 要在MapReduce中读写OSS,需要配置如下的参数。 conf.set("fs.oss.accessKeyId", "unknown"); conf.set("fs.oss.accessKeySecret", "unknown"); conf.set("fs.oss.endpoint","unknown"); WordCount代码:JAVA代码为例,将Hadoop官网WordCount例子做如下修改。对该实例的修改只是在代码中添加了AccessKey ID和AccessKey Secret的配置,以便作业有权限访问OSS文件。 编辑完以后打jar包。 package cn.apache.hadoop.onaliyun.examples; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class EmrWordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: wordcount [...] "); System.exit(2); } conf.set("fs.oss.accessKeyId", "unknown"); // conf.set("fs.oss.accessKeySecret", "unknown"); // conf.set("fs.oss.endpoint", "unknown"); // Job job = Job.getInstance(conf, "word count"); job.setJarByClass(EmrWordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } DataWorks 登录DataWorks控制台。 提交资源 在业务流程EMR引擎下,新建EMR jar资源,存储在/emr/jars目录下(首次使用需要一键授权),提交。 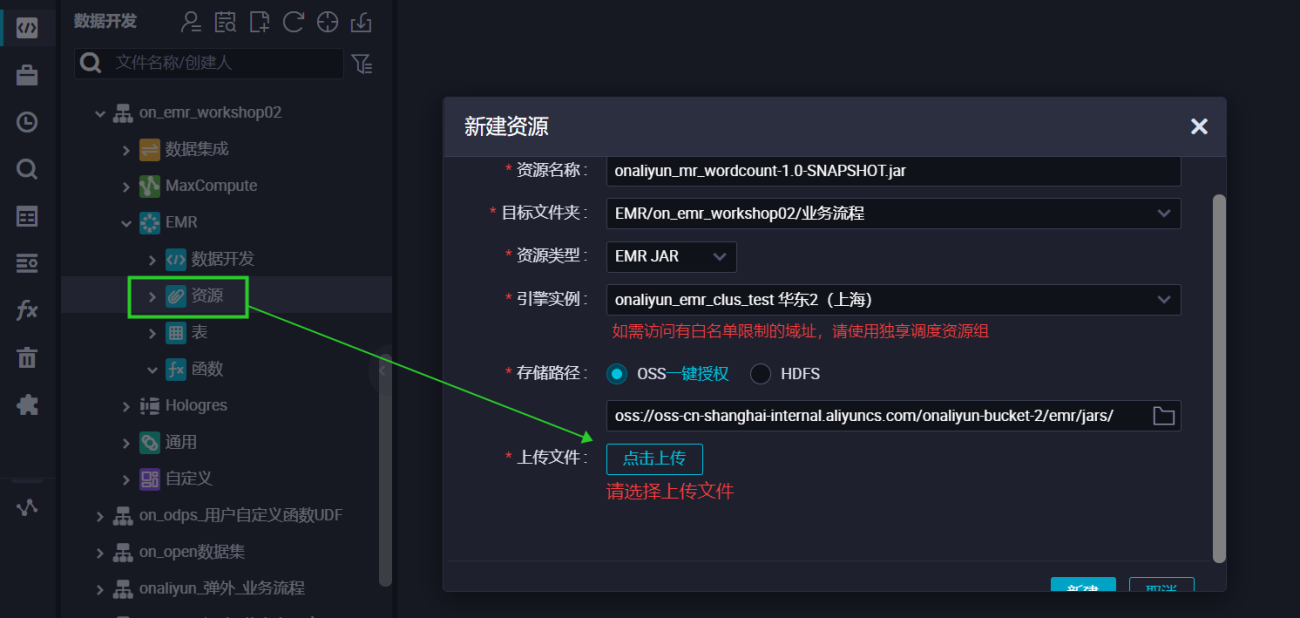
新建MR任务 在业务流程EMR引擎下,新建EMR MR节点。 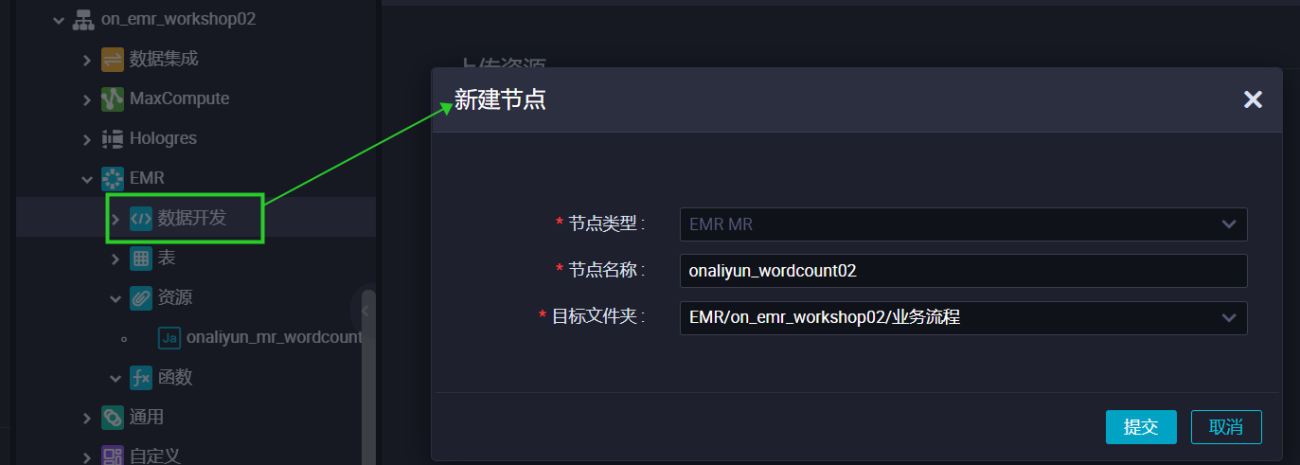
用引用资源的方法调用jar包。 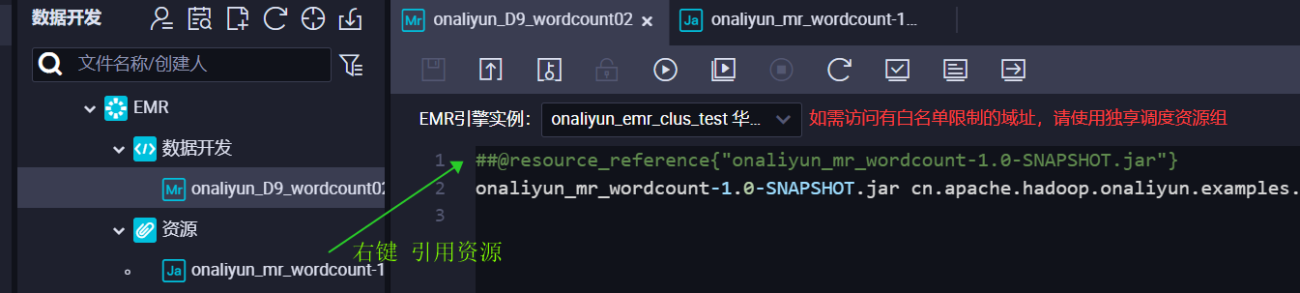
编辑,执行EMR-MR命令。 ##@resource_reference{"onaliyun_mr_wordcount-1.0-SNAPSHOT.jar"} onaliyun_mr_wordcount-1.0-SNAPSHOT.jar cn.apache.hadoop.onaliyun.examples.EmrWordCount oss://onaliyun-bucket-2/emr/datas/wordcount02/inputs oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs 查看结果 返回OSS控制台,目标bucket路径下已经写入了结果。
在DataWorks读取统计结果:新建EMR HIVE节点,建挂载在OSS上的hive外表,读取表数据。 CREATE EXTERNAL TABLE IF NOT EXISTS wordcount02_result_tb ( word STRING COMMENT '单词', cout STRING COMMENT '计数' ) ROW FORMAT delimited fields terminated by '\t' location 'oss://onaliyun-bucket-2/emr/datas/wordcount02/outputs/'; SELECT * FROM wordcount02_result_tb; 获得结果集。 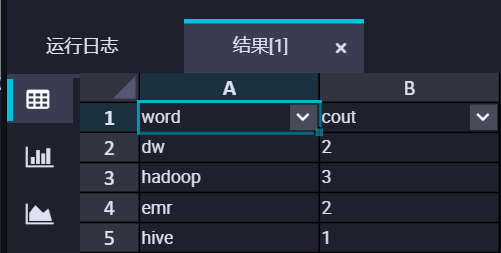 ,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


