
刚接触otter,对otter的很多东西还不了解,想咨询以下各位大神,otter可否实现全量数据的同步,如果可以的话大体是一个怎么样的操作流程,万分感谢!
原提问者GitHub用户 raisemeup
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
一般全量同步我都是这么做的:
1.全量备份(备份前请确认binlog已经开启) mysqldump --single-transaction --master-data=2 --databases db1 db2 -u user -p > full_bak.sql [注]: 必须使用--master-data=2,这样在sql中才有会备份文件的位点信息,如下

2.在目标库执行上述的full_bak.sql
3.在otter中创建canal,指定位点信息,如下(以上图的位点信息为例):
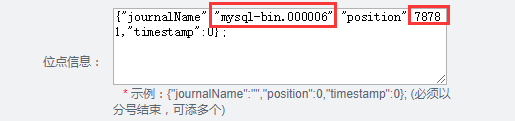
4.然后创建channel,pipline就和正常的步骤一样了
原回答者GitHub用户 linqh1
