
"想问一下,一个udtf运行的很慢,到R3_2,progress总在99%的位置。这是什么原因呢? https://logview.aliyun.com/logview/?h=http://service.cn.maxcompute.aliyun-inc.com/api&p=Mihuashi_MaxCompute_dev&i=20230606104612410g68qw5tkncg&token=WjFHSUtkc0dDKzloMmtNdGlNVG5jMnQweEQ0PSxPRFBTX09CTzpwNF8yMDU0MjQzODQxNDUyNTYxMDgsMTY4ODY0MDM3Mix7IlN0YXRlbWVudCI6W3siQWN0aW9uIjpbIm9kcHM6UmVhZCJdLCJFZmZlY3QiOiJBbGxvdyIsIlJlc291cmNlIjpbImFjczpvZHBzOio6cHJvamVjdHMvbWlodWFzaGlfbWF4Y29tcHV0ZV9kZXYvaW5zdGFuY2VzLzIwMjMwNjA2MTA0NjEyNDEwZzY4cXc1dGtuY2ciXX1dLCJWZXJzaW9uIjoiMSJ9 那个就试跑了一下,这个udtf,我是with下来这个结果,然后再做一些处理。然后再udtf/udaf,结果with下来,再处理,这样是会比较耗时吗?还是?LATERAL VIEW+filter的方式会比udtf省时吗?我发现每个Reduce Worker的工作量并不是均分的,最后一个比较少,就会快一点,odps.stage.reducer.num; odps.stage.reducer.mem 和odps.sql.reducer.memory 的区别是什么啊"
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
"能自己不写udf,就不写,整体看下来也就这个阶段时间相比其他阶段长,看reduce阶段的worker也不多,可以加参数调一下。odps.stage.reducer.num:修改每个Reduce阶段的Worker数量。多一点odps.stage.reducer.mem:设置每个Reduce Worker的内存大小。高一点明细参考:https://help.aliyun.com/document_detail/469143.html?spm=a2c4g.120578.0.i1 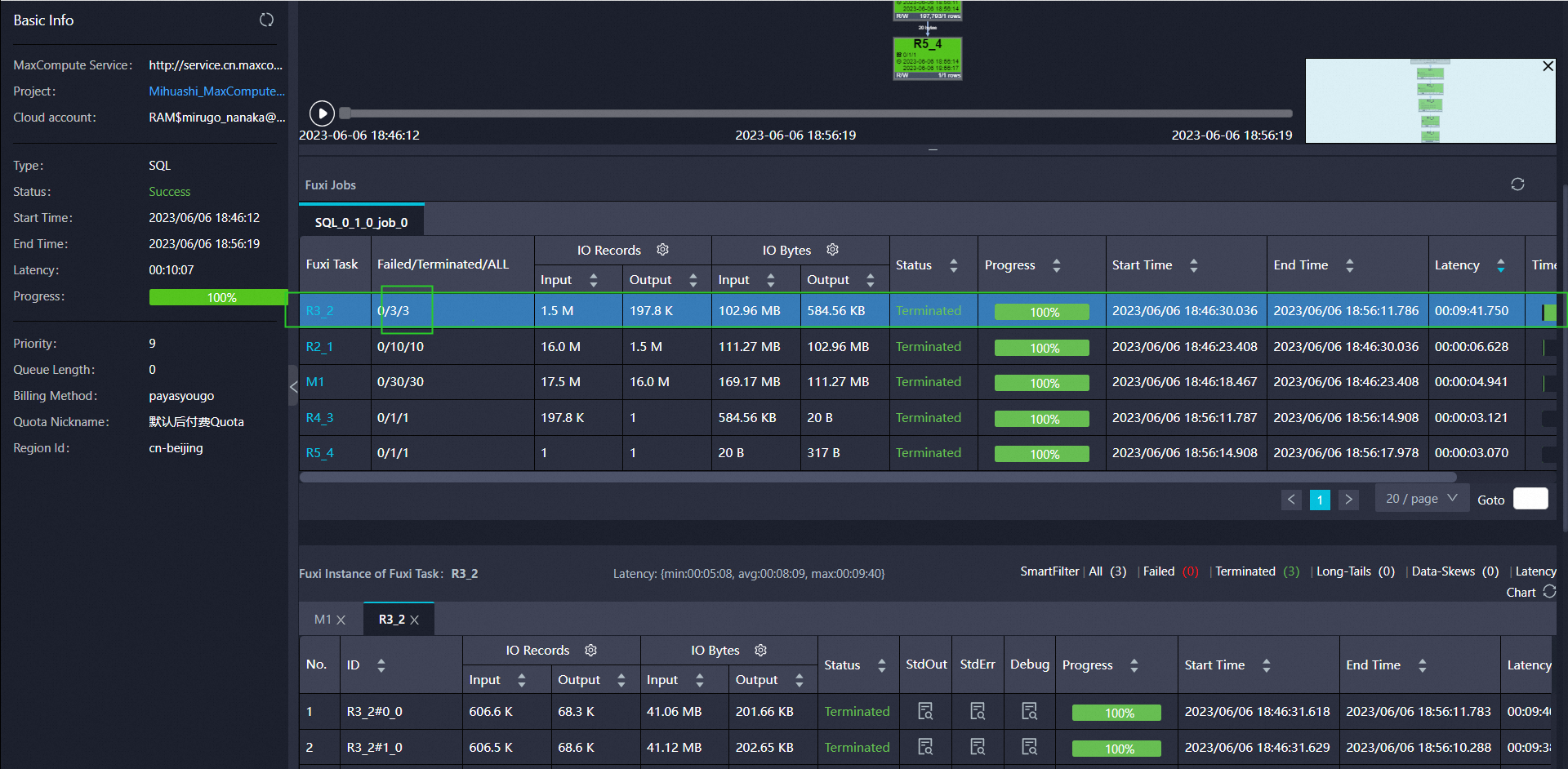 如果可以用MaxCompute的内建函数,可以先用内建函数。内建函数实现不了的可以走udf实现一下,odps.stage.reducer.num:修改每个Reduce阶段的Worker数量。 odps.stage.reducer.mem:设置每个Reduce Worker的内存大小。 说明可以在这个文档里看一下:https://help.aliyun.com/document_detail/469143.html?spm=a2c4g.606063.0.i10
如果可以用MaxCompute的内建函数,可以先用内建函数。内建函数实现不了的可以走udf实现一下,odps.stage.reducer.num:修改每个Reduce阶段的Worker数量。 odps.stage.reducer.mem:设置每个Reduce Worker的内存大小。 说明可以在这个文档里看一下:https://help.aliyun.com/document_detail/469143.html?spm=a2c4g.606063.0.i10
odps.sql.reducer.memory这个参数是内部的一个参数,对应的就是目前文档上的odps.stage.reducer.mem,@宋瑞雪(宋瑞雪 Kumamon) odps.stage.reducer.num:修改每个Reduce阶段的Worker数量。 odps.stage.reducer.mem:设置每个Reduce Worker的内存大小。 说明可以在这个文档里看一下:https://help.aliyun.com/document_detail/469143.html?spm=a2c4g.606063.0.i10
odps.sql.reducer.memory这个参数是内部的一个参数,对应的就是目前文档上的odps.stage.reducer.mem,此回答整理自钉群“MaxCompute开发者社区2群(答疑@机器人)”"
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

