
问题1: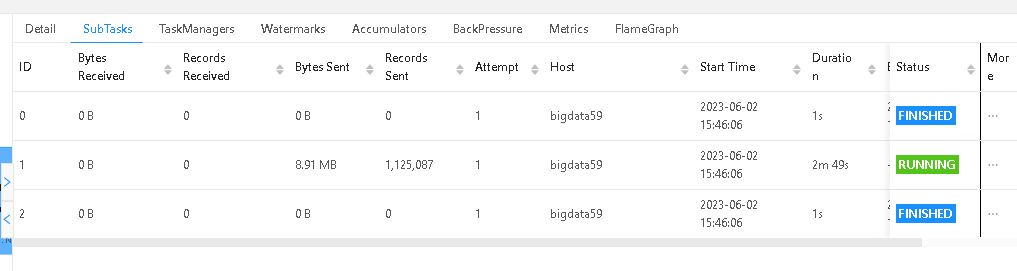 在机器学习PAI感觉读取Hive数据的时候并行度调成3,其他两个subtask好像没读取数据就转成finished状态了,那是不是数据读取不均导致的?问题2:我试了下纯读写任务的速度差不多,应该就是本身读取的速度不快。2023-06-02 17:30:05,423 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -------------------------------------------------------------------------------- 2023-06-02 17:30:05,428 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - Starting YARN TaskExecutor runner (Version: 1.13.3, Scala: 2.12, Rev:a4700e3, Date:2021-10-11T23:52:36+02:00) 2023-06-02 17:30:05,428 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - OS current user: hive 2023-06-02 17:30:05,859 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - Current Hadoop/Kerberos user: hive 2023-06-02 17:30:05,859 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - JVM: Java HotSpot(TM) 64-Bit Server VM - Oracle Corporation - 1.8/25.141-b15 2023-06-02 17:30:05,860 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - Maximum heap size: 12880 MiBytes 2023-06-02 17:30:05,860 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - JAVA_HOME: /usr/java/jdk1.8.0_141-cloudera 2023-06-02 17:30:05,861 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - Hadoop version: 2.8.3 2023-06-02 17:30:05,861 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - JVM Options: 2023-06-02 17:30:05,861 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Xmx14092861440 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Xms14092861440 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -XX:MaxDirectMemorySize=10066329600 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -XX:MaxMetaspaceSize=4294967296 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Djava.security.krb5.conf=/etc/krb5.conf 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -DALINK_PLUGINS_DIR=/data2/anaconda3/envs/alink/lib/python3.6/site-packages/pyalink/lib/plugins 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -DALINK_HIVE_HDFS_CONFIG=/etc/hadoop/conf 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Dlog.file=/data11/yarn/container-logs/application_1683777826211_79791/container_1683777826211_79791_01_000002/taskmanager.log 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Dlog4j.configuration=file:./log4j.properties 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Dlog4j.configurationFile=file:./log4j.properties 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - Program Arguments: 2023-06-02 17:30:05,866 INFO org.apache.flink.yarn.YarnTaskExecutorRunner
在机器学习PAI感觉读取Hive数据的时候并行度调成3,其他两个subtask好像没读取数据就转成finished状态了,那是不是数据读取不均导致的?问题2:我试了下纯读写任务的速度差不多,应该就是本身读取的速度不快。2023-06-02 17:30:05,423 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -------------------------------------------------------------------------------- 2023-06-02 17:30:05,428 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - Starting YARN TaskExecutor runner (Version: 1.13.3, Scala: 2.12, Rev:a4700e3, Date:2021-10-11T23:52:36+02:00) 2023-06-02 17:30:05,428 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - OS current user: hive 2023-06-02 17:30:05,859 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - Current Hadoop/Kerberos user: hive 2023-06-02 17:30:05,859 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - JVM: Java HotSpot(TM) 64-Bit Server VM - Oracle Corporation - 1.8/25.141-b15 2023-06-02 17:30:05,860 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - Maximum heap size: 12880 MiBytes 2023-06-02 17:30:05,860 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - JAVA_HOME: /usr/java/jdk1.8.0_141-cloudera 2023-06-02 17:30:05,861 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - Hadoop version: 2.8.3 2023-06-02 17:30:05,861 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - JVM Options: 2023-06-02 17:30:05,861 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Xmx14092861440 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Xms14092861440 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -XX:MaxDirectMemorySize=10066329600 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -XX:MaxMetaspaceSize=4294967296 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Djava.security.krb5.conf=/etc/krb5.conf 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -DALINK_PLUGINS_DIR=/data2/anaconda3/envs/alink/lib/python3.6/site-packages/pyalink/lib/plugins 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -DALINK_HIVE_HDFS_CONFIG=/etc/hadoop/conf 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Dlog.file=/data11/yarn/container-logs/application_1683777826211_79791/container_1683777826211_79791_01_000002/taskmanager.log 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Dlog4j.configuration=file:./log4j.properties 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - -Dlog4j.configurationFile=file:./log4j.properties 2023-06-02 17:30:05,862 INFO org.apache.flink.yarn.YarnTaskExecutorRunner [] - Program Arguments: 2023-06-02 17:30:05,866 INFO org.apache.flink.yarn.YarnTaskExecutorRunner
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
阿里云机器学习PAI在执行任务时,如果出现数据读取异常、处理异常或计算错误等情况,会导致任务提前结束。有可能是读取不均匀导致的,但还有其他一些可能的原因。
以下是可能导致任务提前结束的一些常见原因:
如果您的任务需要读取数据,但是在读取数据时出现了异常,例如文件不存在、权限问题、文件格式错误等,都可能导致任务提前停止。建议您检查数据源文件路径、权限设置以及文件格式是否正确,确认代码中的数据读取逻辑是否正确。
如果您的程序存在异常、崩溃或死锁等问题,也可能导致任务提前停止。建议您检查代码中的逻辑是否正确、代码是否存在潜在的错误和漏洞,并在异常发生时进行相应的错误处理。
如果您的任务涉及到复杂的计算或运算,例如数值计算、模型训练等,那么计算错误也可能导致任务提前停止。建议您检查代码中的计算逻辑是否正确,尝试将计算任务拆分为更小的部分,并对每个步骤进行检查和验证。
如果您的任务需要占用大量系统资源,例如内存、CPU、GPU等,而系统资源不足,也可能导致任务提前停止。建议您检查系统中是否有足够的资源供任务使用,并优化代码以提高资源利用率。
关于您提到的第一个问题,如果将并行度调整为3后,只有一个Subtask读取了数据,而其他两个Subtask则立即转换为“finished”状态,可能是由于数据倾斜导致的。数据倾斜是指在并行处理中,某些数据量较大或者处理时间较长的任务会造成任务之间的负载不均衡,从而导致某些任务执行时间过长,而其他任务则处于空闲状态。为了解决数据倾斜问题,可以采取以下措施:
数据预处理:在进行计算前,可以对数据进行预处理,例如进行数据采样、分片、降维等操作,以减小数据的规模和复杂度,从而降低数据倾斜的风险。
数据重分区:在进行并行计算时,可以对数据进行重分区,将数据均匀地分布到各个任务中,以减少任务之间的负载不均衡问题。可以使用Flink提供的rebalance()函数将数据均匀地分布到各个任务中。
动态调整并行度:如果出现数据倾斜问题,可以尝试动态调整并行度,将任务分配到更多的节点或更多的任务中,以提高计算效率和负载均衡。
关于您提到的第二个问题,如果纯读写任务的速度与Hive数据读取速度相当,那么可能是由于Hive数据读取的速度受限于网络和存储性能等因素。为了提高Hive数据读取的速度,可以采取以下措施:
优化查询语句:使用合适的查询语句,可以减少数据的扫描和传输量,从而提高查询速度。
数据分区和压缩:对于大规模数据集,可以使用数据分区和压缩等技术,减少数据的存储空间和传输量,从而提高数据读取和处理的速度。
使用高性能存储:使用高性能的存储设备和文件系统,可以提高数据读取和写入的速度,从而加快数据处理的速度。
增大并行度:通过增大任务的并行度,可以将数据分配到更多的节点或更多的任务中,从而提高数据处理的速度。
针对问题1的回答:1. 其他的task都提前finish了,这就是读没切开,orc的话,可以用debug的log level,看下具体的原因 2. 这个读取速度本身确实好像不怎么快,这个可以看下是不是下游有没有比较重的任务,或者就直接整个只有读写的任务看下吞吐。针对问题2的回答:看了一下
按照 https://github.com/alibaba/Alink/blob/c57424780bfe92a313bd09af2f42987e9bfb42e6/core/src/main/java/com/alibaba/alink/common/io/catalog/HiveCatalog.java#L103 这个传进去一个hive的配置文件
具体的格式是 https://github.com/alibaba/Alink/blob/c57424780bfe92a313bd09af2f42987e9bfb42e6/core/src/main/java/com/alibaba/alink/common/io/catalog/HiveBaseUtils.java#L275
这样应该可以对齐hive那边的配置
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。



