
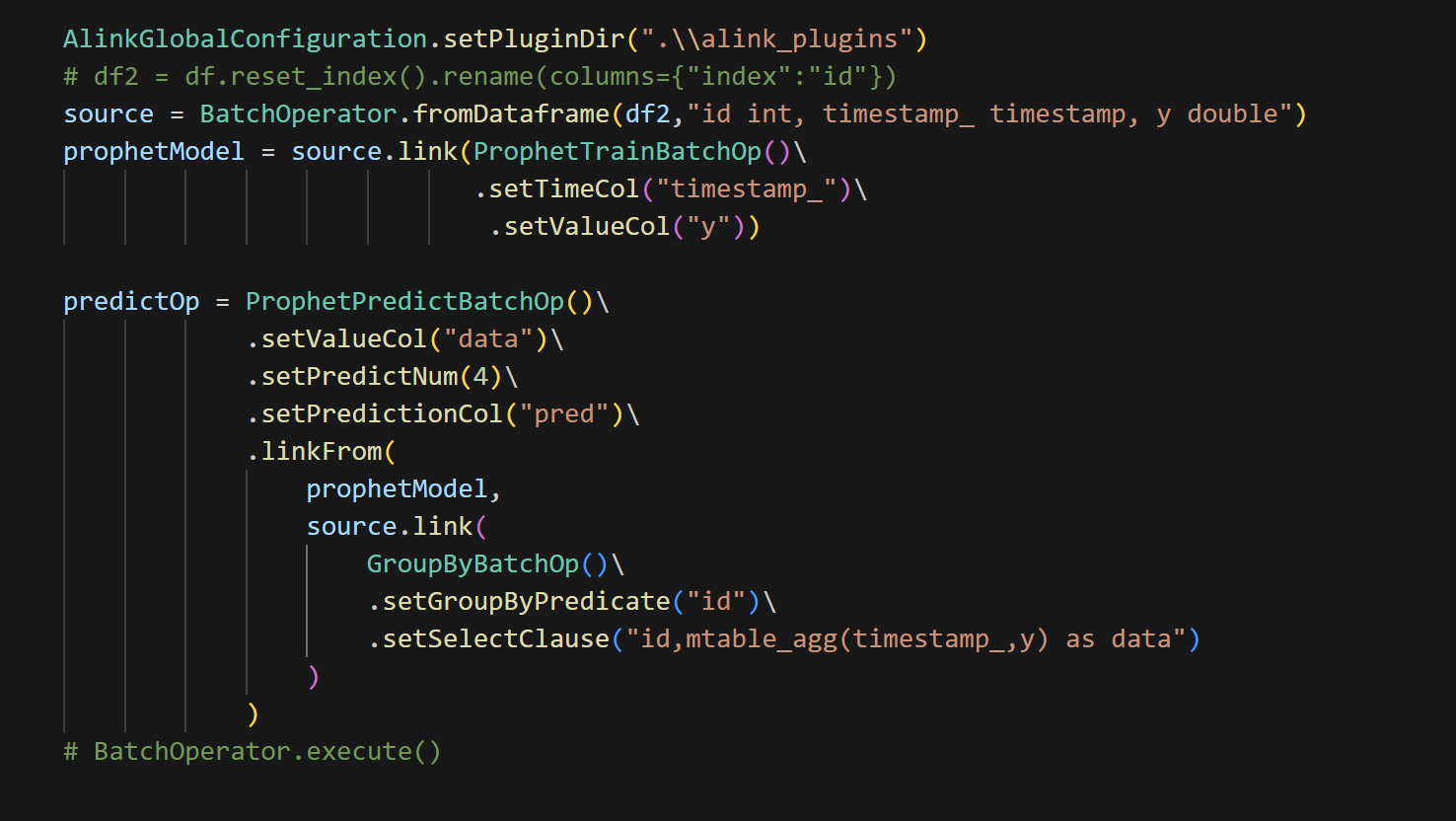
 在机器学习PAI请问pyalink==1.5.5版本中使用prophet预测得到的结果是NaN的问题怎么解决?
在机器学习PAI请问pyalink==1.5.5版本中使用prophet预测得到的结果是NaN的问题怎么解决?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
如果在机器学习PAI中使用PyAlgo的Prophet模型预测得到的结果为NaN,可能是因为时间戳数据类型不匹配导致的。Prophet模型要求时间戳数据必须是pandas的datetime类型,如果数据类型不匹配,则会出现NaN的情况。
解决方法如下:
1.检查数据集的时间戳数据类型是否为pandas的datetime类型。如果不是,则需要将其转换为datetime类型。
2.检查数据集是否包含缺失值或异常值。Prophet模型对缺失值和异常值比较敏感,可能会导致预测结果不准确。
3.检查Prophet模型的参数设置是否正确。例如,是否设置了正确的时间间隔和季节性参数等。
4.尝试使用其他时间序列预测模型,例如ARIMA、LSTM等,看看是否可以得到更好的预测结果。
如果以上方法都无法解决问题,请尝试联系机器学习PAI的技术支持团队获取帮助。
在使用PyaLink 1.5.5版本中的Prophet模型进行预测时,出现结果为NaN的情况可能有多种原因,下面列举几种可能的原因以供参考:
缺失值:Prophet模型对于输入数据中的缺失值是比较敏感的。如果输入数据中存在缺失值,可能会导致预测结果出现NaN的情况。建议在使用Prophet模型进行预测前,首先对输入数据进行清洗和处理,确保数据质量。
数据范围错误:Prophet模型默认使用的是时间序列数据,而且要求数据的时间间隔是固定的。如果输入数据的时间间隔不正确,或者数据范围错误,例如时间戳格式错误等,也会导致预测结果为NaN。可以检查一下输入数据的时间戳格式是否正确,并根据需要进行处理和转换。
模型参数错误:Prophet模型的预测效果受到多个参数的影响,例如季节性、趋势性等参数的设置。如果这些参数设置不正确,也会导致预测结果为NaN。可以检查一下Prophet模型的参数设置是否正确,并根据需要进行调整和优化。
模型训练数据过少:Prophet模型需要足够的历史数据来进行训练,否则可能无法准确预测未来的数据。如果模型训练数据过少,也会导致预测结果出现NaN的情况。建议在使用Prophet模型进行预测前,确保训练数据充足,并根据需要进行采样和平滑处理。
根据您提供的代码,我发现您使用的是pyalink 1.5.5版本,其中使用了Alink和ProphetTrainBatchOp进行时间序列预测。根据您提供的代码,我无法判断您的数据是否正确,因此我将假设您的数据格式正确。
在您的代码中,您使用ProphetTrainBatchOp训练了一个Prophet模型,然后使用ProphetPredictBatchOp进行预测。但是,根据您提供的代码,我没有看到您将训练好的模型与预测操作连接起来。您需要将ProphetTrainBatchOp的输出链接到ProphetPredictBatchOp,以便在模型上进行预测。
另外,在您的代码中,我没有看到您指定Prophet模型的超参数。Prophet模型的预测性能很大程度上取决于超参数的选择。您需要根据您的数据和预测任务选择合适的超参数。
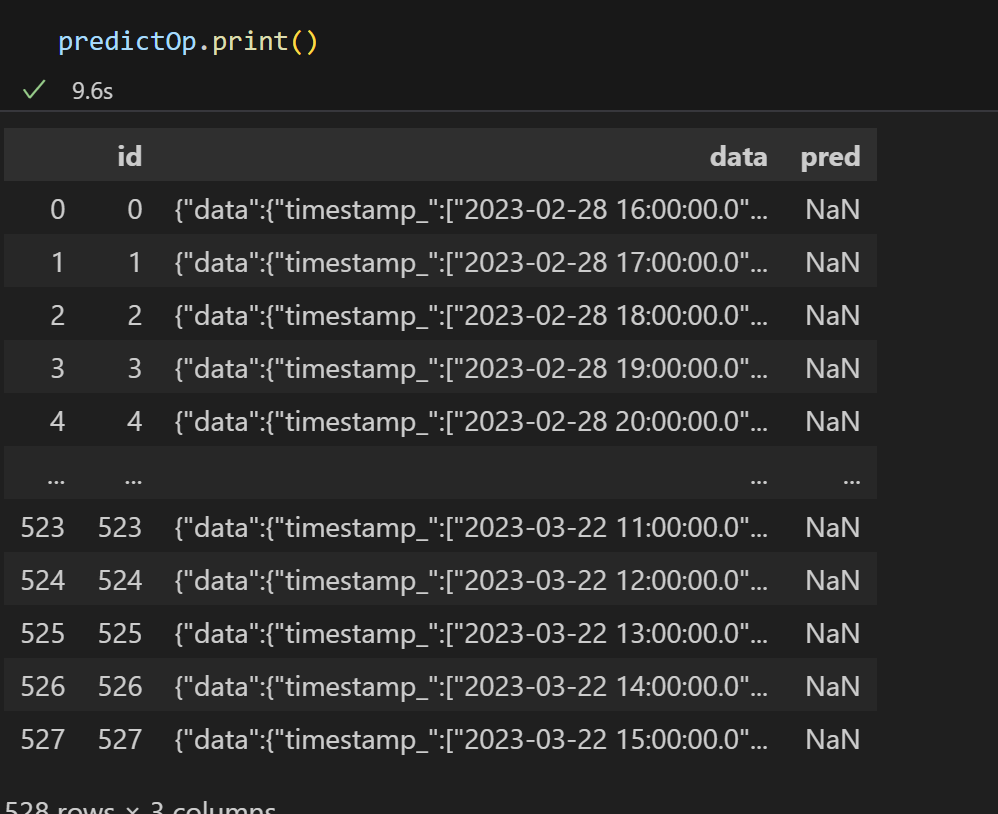
最后,您提到预测结果为NaN。这可能是由于训练数据中存在NaN值或异常值,或者您的超参数选择不合适,导致模型无法正确拟合数据。您可以检查您的数据和超参数选择,以确定问题的根本原因。
如果您需要更多的帮助,请提供更多的上下文信息或代码,以便我可以更好地帮助您解决问题。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。



