
背景 部署了三台机器,分别是 172.21.1.116(记为116),172.21.1.134(记为134),172.21.1.150(记为150) 启动均采用 nacos.core.member.lookup.type=address-server 模式获取集群列表
缩容场景 执行步骤:
1、kill - 9 134机器上的nacos进程
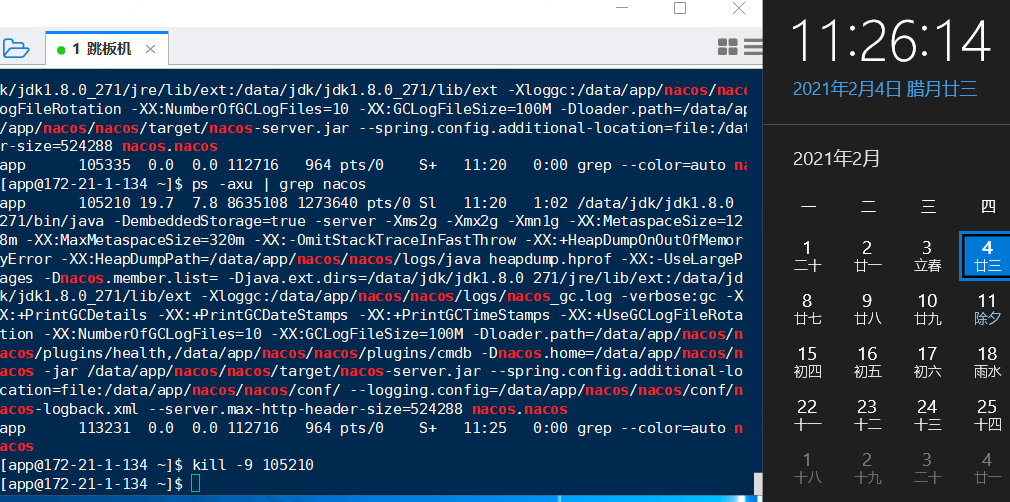
2、查看150机器上的控制台
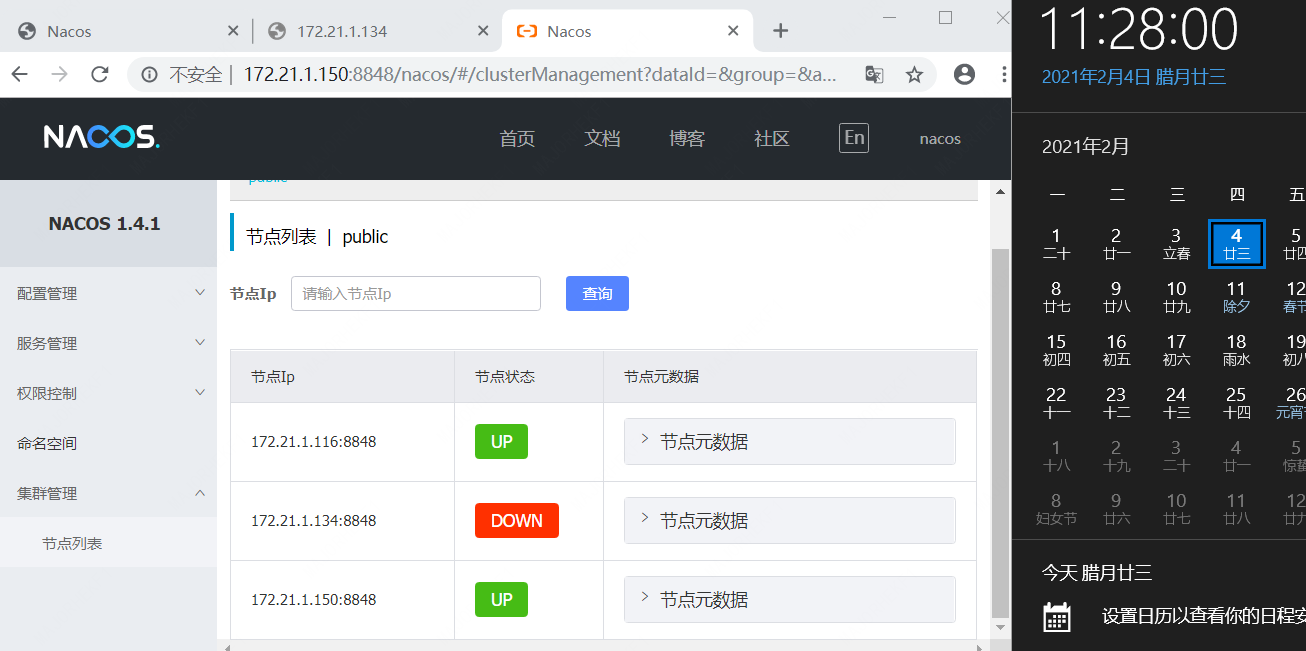
3、刷新再查看150机器上的控制台
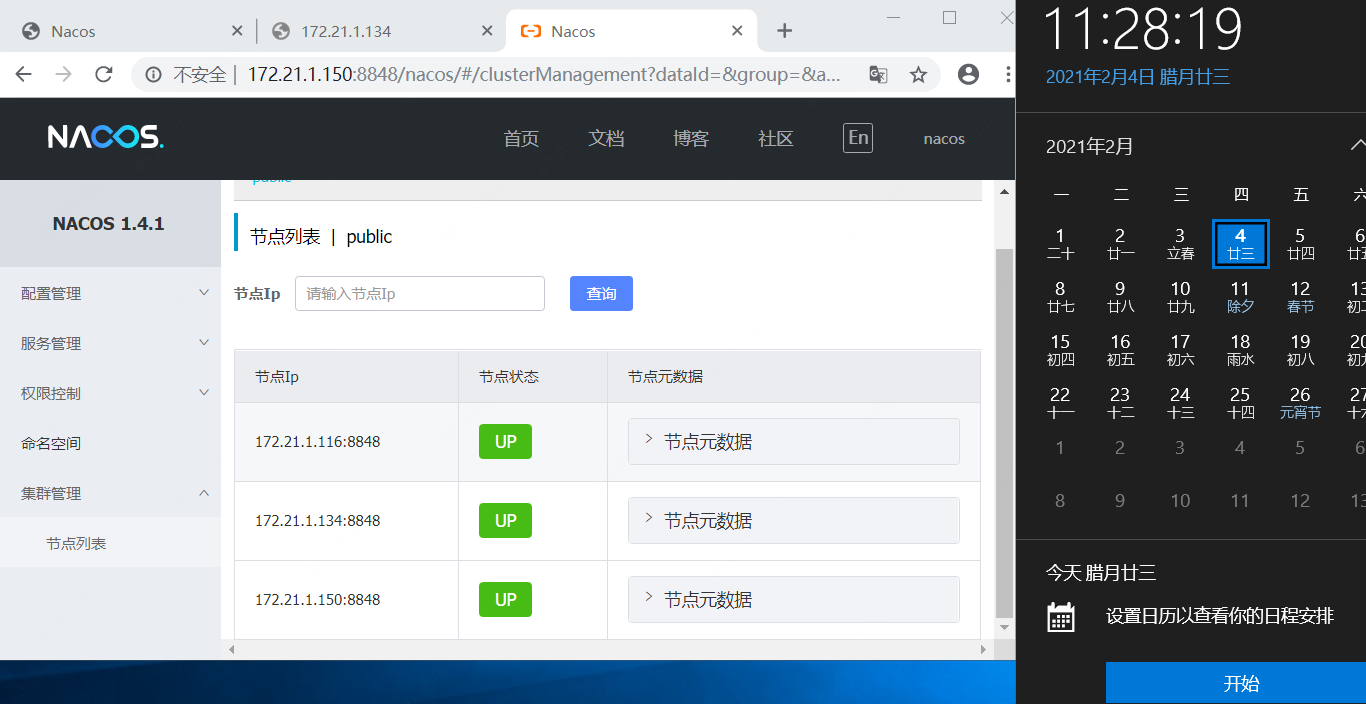
4、查看116机器上的控制台
5.查看nacos.log文件的错误日志
注意,无论是从控制台看,还是用OpenAPI直接访问获取数据,在116、150这两台机器上看134这台机器上的状态,都是不断的在down 和 up 之间来回跳转。
问题1:对于distro协议计算权威节点或者其他涉及到要获取nacos server状态的逻辑来说,这样的情况会不会造成问题?比如说我看到就有其他issue在反馈说请求被转发到已经杀掉进程的机器上。
扩容场景
1、无论是使用 cluster.conf 还是 address-server 应该无论哪种寻址模式都能复现这个问题
2、跟上面相同的背景,此时新增一台机器A,从同一个address-server获取集群列表(注意,集群列表没有改动)
3、机器A发现获取的集群列表没有自己的IP地址,根据nacos的代码,它将 members.add(this.self);
4、已有的三台机器,116,134,150并不承认新加入的机器A,nacos.log抛出异常说机器A的ip不在 ip list 里面
5、但是raft协议会将机器A的ip加入到raft group里面
6、如果我尝试kill 116,134,150这些机器,有可能会出现选主选机器A为leader的情况
7、这个时候,整个nacos的CP协议都失效了,在控制台无法查询配置、无法查看命名空间、无法查询集群列表,报出来的异常也都是 No leader at term xx.
8、个人测试,重启116,134,150这些机器也没用,重启后也是处于CP协议失效的状态,除非kill掉机器A,然后rm -rf 原来的nacos的文件并重新解压运行(embedded storage),不知道你们能不能复现这个场景
问题2:扩容是不是要严格遵循,先更改address-server里面的集群列表,再启动进程的过程?如果不是,那扩缩容同时进行就有可能出现我说的这个问题;如果是,那为什么在机器A启动的时候,发现没有自己的ip地址,没有报错终止启动?
原提问者GitHub用户MajorHe1
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
1、这个报错是必然的 因为这是个废弃的raft协议,集群已经全部升级到1.4以上并且运行后, 旧raft协议会被关闭,扩容时肯定找不到旧raft leader,而是去找新raft leader。
2、扩容可以先启动,再添加ip,也可以先添加ip,后启动程序。只要ip列表发生变化(无论cluster。conf还是addressserver, 都会触发server member update事件,重新读取和更新。
3、暂不支持自动扩缩容,需要手动到addressserver去添加或者修改cluster.conf
原回答者GitHub用户KomachiSion
阿里云拥有国内全面的云原生产品技术以及大规模的云原生应用实践,通过全面容器化、核心技术互联网化、应用 Serverless 化三大范式,助力制造业企业高效上云,实现系统稳定、应用敏捷智能。拥抱云原生,让创新无处不在。
