
ADB中insert的时候没有什么能提高性能的设置吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
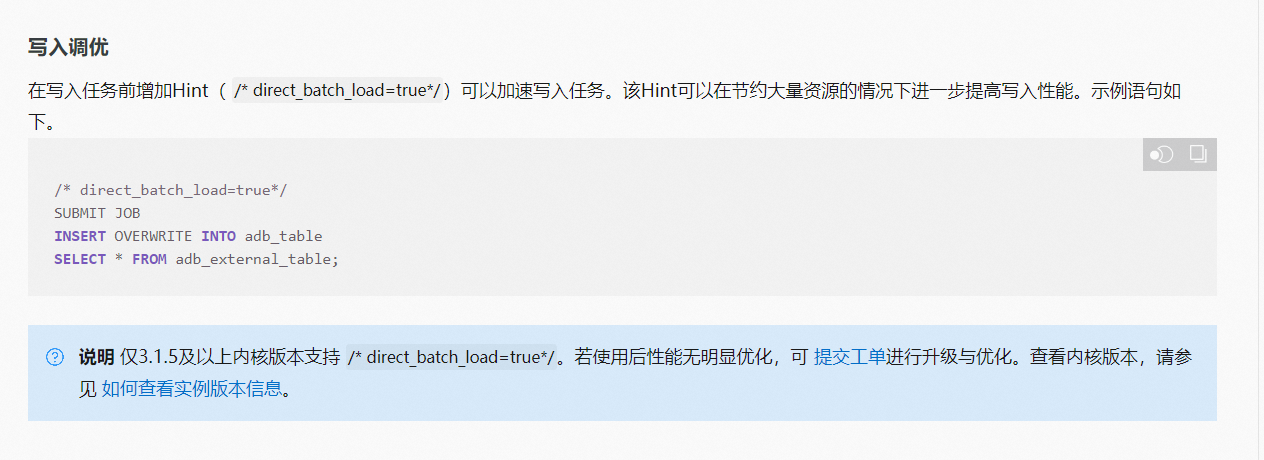 参考文档:https://help.aliyun.com/document_detail/123824.html?spm=a2c4g.123686.0.i8,此回答整理自钉群“云数据仓库ADB-开发者群”
参考文档:https://help.aliyun.com/document_detail/123824.html?spm=a2c4g.123686.0.i8,此回答整理自钉群“云数据仓库ADB-开发者群”
问题1:ADB中 insert 时可以通过以下几种方式来提高性能:
批量操作:使用批量插入的方式可以显著提高性能。批量插入可减少连接数、减小网络负荷、简化处理过程,避免多余的解析工作。批量插入支持的行数取决于插入值的大小和数据类型。
启用排序缓存:在对具有相同表结构和排序列的大型数据库执行插入操作时,启用“排序缓存”可以显著提高插入速度。启用后,在支持排序操作INSERT语句时允许数据库以奇妙的速度插入数据。
调整跨区域复制参数:跨区域复制是透明且自动化的,但是在某些情况下可能会对插入性能产生负面影响。 您可以考虑在插入重负载表期间调整跨区域复制参数。
使用导入和导出服务:如果需要在大规模数据集之间进行插入或复制操作,则可以使用导入或导出服务来尽快完成此操作。 可以支持的数据格式包括 JSON、AVRO、CSV、TSV 等。
问题2:如果您的需求只能使用 insert into tablename values() 的语法,则可以使用类似以下方式的纯 JDBC 代码实现批量插入:
Connection connection = // 获取数据库连接
PreparedStatement pstmt = connection.prepareStatement("INSERT INTO tablename (column1, column2, column3) VALUES (?, ?, ?)");
for (int i = 0; i < valuesList.size(); i++) {
pstmt.setXXX(1, valuesList.get(i).getColumn1()); // 设置第一个参数的值
pstmt.setXXX(2, valuesList.get(i).getColumn2()); // 设置第二个参数的值
pstmt.setXXX(3, valuesList.get(i).getColumn3()); // 设置第三个参数的值
pstmt.addBatch();
}
pstmt.executeBatch();
此代码基于 PreparedStatement 对象实现,允许将多行数据批量插入,每个 PreparedStatement 实例都应包含一些占位符,用 '?' 来代替需要更新的实际值。然后可以使用 setXXX() 方法为每个参数设置实际值。
问题3:jdbc 连接字符串中的 rewriteBatchedStatements=true 参数可以开启批量更新操作的性能优化。开启此选项后,大多数数据库开发工具都会使用某种形式的批量更新来执行多条语句,以提高执行速度。使用 rewriteBatchedStatements 参数设置后,JDBC 将捆绑记录在一起,再将它们作为单个批处理语句进行发送。这可以提高效率和性能。
如果使用 Alibaba Cloud ADB for MySQL,可以在官方文档中找到相关的说明:https://www.alibabacloud.com/help/zh/doc-detail/122206.htm
如果使用其他的 JDBC 驱动程序,具体的参数和用法可能有所不同,建议仔细参考官方文档或 API 文档。
问题1:在 ADB 中,对于插入数据的性能优化可以通过以下几种方式来实现:
使用批量插入(Batch Insert):可以使用 insert into table values(),(),...() 语句将多条记录一次性插入到数据库中,这样可以减少网络传输和数据库交互的次数,从而提高性能。 启用事务(Transaction):事务是将多个数据库操作组合成一个原子操作的逻辑单元,可以保证数据的一致性和完整性。在插入数据时,可以将多个插入操作放在同一个事务中,从而减少数据库的锁定时间和资源消耗。 调整 JDBC 连接的参数:可以通过调整 JDBC 连接的参数来优化插入数据的性能。例如,可以设置 batchSize 参数来控制批量插入的大小,设置 cacheEnabled 参数来启用结果集缓存等。 问题2:如果只能使用 insert into tablename values() 的语法插入数据,则无法使用 insert select 语法进行数据迁移。可以考虑使用其他工具或技术来实现数据迁移,例如使用外部表(External Table)或 ETL(Extract, Transform, Load)工具等。
问题3:rewriteBatchedStatements=true 是 JDBC 连接的一个参数,它用于控制批量语句的重写方式。在 JDBC 4.0 及以上版本中,默认为 true,表示使用优化后的批量语句。在 JDBC 4.0 以下版本中,需要手动设置该参数为 true 才能启用优化。相关文档可以在 JDBC 官方文档中找到。
对于您的问题1,ADB 中的 insert 操作可以通过以下几种方式来提高性能:
批量插入:通过批量插入多条记录,可以减少 I/O 操作次数,提高插入性能。可以使用 JDBC API 的 executeBatch 方法执行批量插入操作。
分区插入:将需要插入的记录按照表的分区规则划分到不同的分区中,可以利用并行计算的能力提高插入性能。
压缩插入数据:使用压缩格式将插入数据写入磁盘,可以减少 I/O 操作的次数,提高插入性能。
对于您的问题2,如果您只能使用 insert into tablename values() 语法进行插入操作,可以采用单个 JDBC 插入语句,或批量预处理的方式,执行多个插入语句,来完成数据的插入操作。您可以在使用 JDBC API 时,使用 PreparedStatement 的 addBatch() 方法添加多个插入语句,再使用 executeBatch() 方法执行批量插入操作,以提高性能。
对于您的问题3,rewriteBatchedStatements=true 是一个 JDBC 连接参数,表示将一组 insert、update 和 delete 操作转换为一个批量语句执行,而不是多个单个语句执行。这个参数可以提高 insert 操作的性能。您可以在创建 JDBC 连接对象时,设置此参数,以启用批量插入功能。
ADB 的 JDBC 官方文档中(https://www.alibabacloud.com/help/zh/doc-detail/159198.htm)提到了这个参数,您可以参考文档了解更多相关信息。
问题1:在阿里云云原生数据仓库 AnalyticDB 中,可以通过以下几种方式来提高 insert 操作的性能:
尽量使用批量插入,而不是单条插入。可以通过 JDBC 的 addBatch 和 executeBatch 方法来实现批量插入。
合理设置分区键和分布键,以便数据能够均匀分布在各个节点上。
将 AnalyticDB 的读写分离功能开启,将读操作和写操作分别路由到不同的节点上,从而提高写入性能。
使用 AnalyticDB 提供的数据导入工具 DataX 进行数据导入,可以利用其高效的数据传输和并发处理能力。
问题2:如果您的需求只能使用 insert into tablename values() 语法进行数据插入,那么可以考虑使用批量插入的方式来提高性能。例如,可以将多条 insert 语句组合成一个批量插入操作,然后一次性执行。可以通过 JDBC 的 addBatch 和 executeBatch 方法来实现批量插入。
问题3:在使用 JDBC 进行数据插入时,可以设置 rewriteBatchedStatements 参数来开启批量插入功能。当该参数设置为 true 时,JDBC 会将多条 insert 语句合并成一个批量插入操作,从而提高性能。该参数的设置方法可以参考 JDBC 驱动程序的相关文档。此外,您也可以在阿里云云原生数据仓库 AnalyticDB 的官方文档中找到更多关于数据插入的详细信息和最佳实践。
问题1:在 ADB 中,可以通过以下设置来提高 insert 性能:
使用多个线程并行插入数据。 禁用索引,插入完成后再启用。 批量插入数据。 问题2:如果你的需求只能使用 insert into tablename values(),那么你可以考虑使用以下方法来提高性能:
使用多个线程并行插入数据。 禁用索引,插入完成后再启用。 批量插入数据。 问题3:jdbc 中可以使用 rewriteBatchedStatements=true 参数来开启批量插入功能。关于这个参数的详细说明可以参考 MySQL 官方文档:https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-configuration-properties.html
在ADB(AnalyticsDB)中,insert数据时可以通过以下设置来提高性能:
使用批量插入
减少索引和约束
调整分区数和分区策略
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。



