
视觉智能平台通用图像打标,目前看不准确,我们有办法提高准确率吗?  识别的时候车没有识别出来,返回的是书,其他 这种程度没办法使用啊,或者有更准确的方式吗?是新闻媒体 场景的话就是想给图片打标签 这个主要是图片都是随机的,没办法裁剪啊?
识别的时候车没有识别出来,返回的是书,其他 这种程度没办法使用啊,或者有更准确的方式吗?是新闻媒体 场景的话就是想给图片打标签 这个主要是图片都是随机的,没办法裁剪啊?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
是识别不准,还是通用标签中没有该类物品呢? 通用图像打标最多输出图片中的5个标签,且按照置信度进行排序。车没有识别可能是因为其识别结果的置信度比较低,排至5个标签之后了,所有未显示 你们的应用场景是怎样的?主要需要识别的内容是什么? 嗯嗯,那使用图像打标会更合适些,因为有输入出的标签数的限制,所以有的标签未输出,我测试了下将图片进行裁剪之后,标签结果会更加准确。是否可以不使用多图拼图呢?
通用图像打标最多输出图片中的5个标签,且按照置信度进行排序。车没有识别可能是因为其识别结果的置信度比较低,排至5个标签之后了,所有未显示 你们的应用场景是怎样的?主要需要识别的内容是什么? 嗯嗯,那使用图像打标会更合适些,因为有输入出的标签数的限制,所以有的标签未输出,我测试了下将图片进行裁剪之后,标签结果会更加准确。是否可以不使用多图拼图呢? 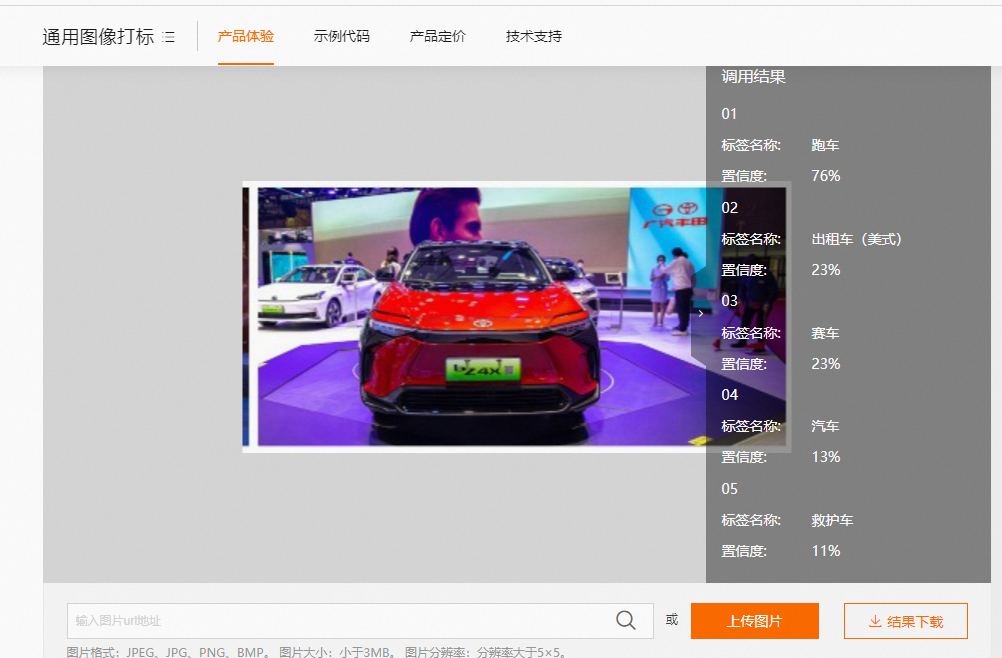 这个没办法,毕竟只输出5个标签,有些识别的标签置信度靠后就会无法识别。或者你们可以看物体检测,对图片中的物体会识别输出的比较多 https://vision.aliyun.com/experience/detail?spm=a2c4g.159140.0.0.6c393fbfKHhV8l&&tagName=objectdet&children=DetectObject,此回答整理自钉群“阿里云视觉智能开放平台咨询1群”
这个没办法,毕竟只输出5个标签,有些识别的标签置信度靠后就会无法识别。或者你们可以看物体检测,对图片中的物体会识别输出的比较多 https://vision.aliyun.com/experience/detail?spm=a2c4g.159140.0.0.6c393fbfKHhV8l&&tagName=objectdet&children=DetectObject,此回答整理自钉群“阿里云视觉智能开放平台咨询1群”
针对通用图像打标的准确率问题,有以下几种方法可以尝试提高:
改善数据集:如果训练数据集不够全面、不够丰富,那么模型的准确率就会受到限制。可以通过增加数据集样本数量、增加数据集类别、选择更具代表性的数据等方式来改进数据集。
调整算法参数:有些算法具有一些可调参数,比如神经网络的层数和节点数、卷积核大小等。可以通过尝试不同的参数组合来寻找最优的预测效果。
使用预训练模型:有些预训练模型在大规模数据集上已经取得了很好的效果,可以考虑使用这些模型作为基础模型,再进行微调或迁移学习。
人工干预:对于一些难以准确识别的图片,可以考虑引入人工审核的环节,在此基础上改进模型。
总之,提高视觉智能平台通用图像打标的准确率需要多方面的努力和尝试,并且需要评估不同方法的效果,逐步找到最适合自己应用场景的解决方案。
有以下几种方式可以提高准确率:
将更多样本加入到训练集中,可以让算法更好地学习不同物体的特征,从而提高准确率。您可以尝试收集更多不同场景下的图片作为训练数据,来提高分类器的泛化能力。
将图像传入识别算法前,可以对其进行灰度化、裁剪、缩放等预处理操作,以减少噪声和干扰,增加分类器的准确率。
视觉智能平台提供多种算法和模型供选择,您可以尝试使用不同的算法模型或调整参数以获得更高的准确率。
在图像分类准确率较低的情况下,可以采用人工干预或半自动化的方式进行打标。例如,您可以通过人工干预的方式手动选取符合要求的部分区域,或者使用半自动化的方式让算法先自动选取一些区域,人工再进行调整。
总的来说,针对不同场景下的图片,提高准确率需要针对性的进行优化。最好的方法是收集足够多的样本,并利用不同的算法和参数进行实验,以找到最适合您的业务需求的数据处理和模型训练方式。



