
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。简单的讲,就是识别自然文本中的实体指称的边界和类别。
2. 命名实体识别的发展历史
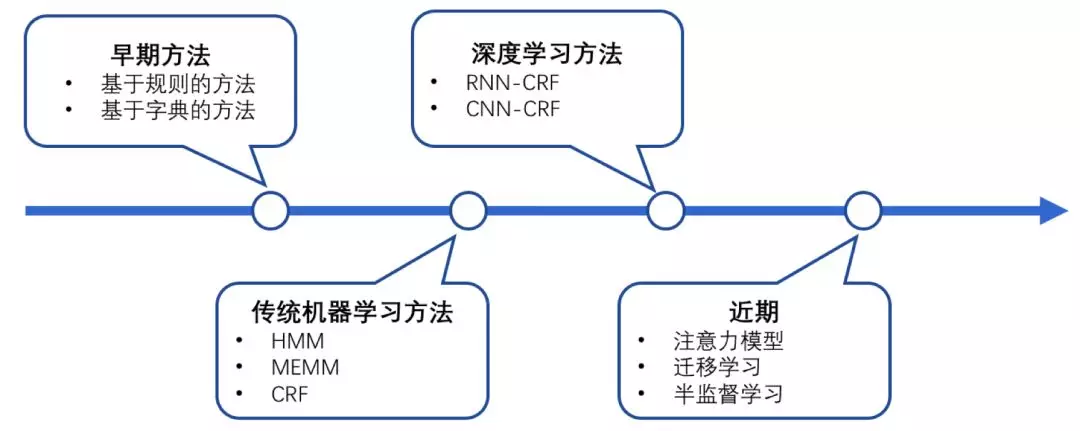
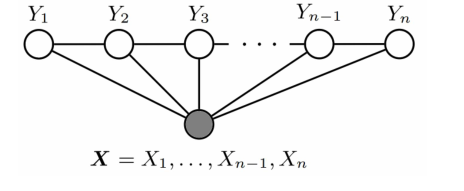
早期基于规则、字典的方法就不细说。目前使用最广泛的应该是基于统计的方法(对语料库的依赖比较大),利用大规模的语料来学习出标注模型,来对各个位置进行标注。CRF是NER目前的主流模型,它的目标函数不仅考虑输入的状态特征函数,而且还包含了标签转移特征函数。在已知模型时,给输入序列求预测输出序列即求使目标函数最大化的最优序列,是一个动态规划问题,可以使用Viterbi算法解码来得到最优标签序列。CRF的优点在于其为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息。
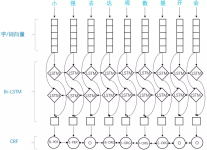
3. BiLSTM-CRF
应用于NER中的biLSTM-CRF模型主要由Embedding层(主要有词向量,字向量以及一些额外特征),双向LSTM层,以及最后的CRF层构成。实验结果表明biLSTM-CRF已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
4. 总结
将神经网络与CRF模型相结合的CNN/RNN-CRF成为了目前NER的主流模型。对于CNN与RNN,并没有谁占据绝对优势,各有各的优点。由于RNN有天然的序列结构,所以RNN-CRF使用更为广泛。基于神经网络结构的NER方法,继承了深度学习方法的优点,无需大量人工特征。只需词向量和字向量就能达到主流水平,加入高质量的词典特征能够进一步提升效果。对于少量标注训练集问题,迁移学习,半监督学习应该是未来研究的重点。
5. 工具推荐
5.1. Stanford NER
斯坦福大学开发的基于条件随机场的命名实体识别系统,该系统参数是基于CoNLL、MUC-6、MUC-7和ACE命名实体语料训练出来的。
地址:https://nlp.stanford.edu/software/CRF-NER.shtml
python实现的Github地址:https://github.com/Lynten/stanford-corenlp
# 安装:pip install stanfordcorenlp
# 国内源安装:pip install stanfordcorenlp -i https://pypi.tuna.tsinghua.edu.cn/simple
# 使用stanfordcorenlp进行命名实体类识别
# 先下载模型,下载地址:https://nlp.stanford.edu/software/corenlp-backup-download.html
# 对中文进行实体识别
from stanfordcorenlp import StanfordCoreNLP
zh_model = StanfordCoreNLP(r'stanford-corenlp-full-2018-02-27', lang='zh')
s_zh = '我爱自然语言处理技术!'
ner_zh = zh_model.ner(s_zh)
s_zh1 = '我爱北京天安门!'
ner_zh1 = zh_model.ner(s_zh1)
print(ner_zh)
print(ner_zh1)
[('我爱', 'O'), ('自然', 'O'), ('语言', 'O'), ('处理', 'O'), ('技术', 'O'), ('!', 'O')]
[('我爱', 'O'), ('北京', 'STATE_OR_PROVINCE'), ('天安门', 'FACILITY'), ('!', 'O')]
# 对英文进行实体识别
eng_model = StanfordCoreNLP(r'stanford-corenlp-full-2018-02-27')
s_eng = 'I love natural language processing technology!'
ner_eng = eng_model.ner(s_eng)
s_eng1 = 'I love Beijing Tiananmen!'
ner_eng1 = eng_model.ner(s_eng1)
print(ner_eng)
print(ner_eng1)
[('I', 'O'), ('love', 'O'), ('natural', 'O'), ('language', 'O'), ('processing', 'O'), ('technology', 'O'), ('!', 'O')]
[('I', 'O'), ('love', 'O'), ('Beijing', 'CITY'), ('Tiananmen', 'LOCATION'), ('!', 'O')]
5.2 MALLET
麻省大学开发的一个统计自然语言处理的开源包,其序列标注工具的应用中能够实现命名实体识别。 官方地址:http://mallet.cs.umass.edu/
5.3 Hanlp
HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。支持命名实体识别。 Github地址:https://github.com/hankcs/pyhanlp
官网:http://hanlp.linrunsoft.com/
# 安装:pip install pyhanlp
# 国内源安装:pip install pyhanlp -i https://pypi.tuna.tsinghua.edu.cn/simple
# 通过crf算法识别实体
from pyhanlp import *
# 音译人名示例
CRFnewSegment = HanLP.newSegment("crf")
term_list = CRFnewSegment.seg("我爱北京天安门!")
print(term_list)
[我/r, 爱/v, 北京/ns, 天安门/ns, !/w]
5.4 NLTK
NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。
Github地址:https://github.com/nltk/nltk 官网:http://www.nltk.org/
# 安装:pip install nltk
# 国内源安装:pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
import nltk
s = 'I love natural language processing technology!'
s_token = nltk.word_tokenize(s)
s_tagged = nltk.pos_tag(s_token)
s_ner = nltk.chunk.ne_chunk(s_tagged)
print(s_ner)
5.5 SpaCy
工业级的自然语言处理工具,遗憾的是不支持中文。 Gihub地址: https://github.com/explosion/spaCy 官网:https://spacy.io/
# 安装:pip install spaCy
# 国内源安装:pip install spaCy -i https://pypi.tuna.tsinghua.edu.cn/simple
import spacy
eng_model = spacy.load('en')
s = 'I want to Beijing learning natural language processing technology!'
# 命名实体识别
s_ent = eng_model(s)
for ent in s_ent.ents:
print(ent, ent.label_, ent.label)
Beijing GPE 382
6.6 Crfsuite
可以载入自己的数据集去训练CRF实体识别模型。
文档地址:
https://sklearn-crfsuite.readthedocs.io/en/latest/?badge=latest
代码已上传:https://github.com/yuquanle/StudyForNLP/blob/master/NLPbasic/NER.ipynb
参考文献: https://mp.weixin.qq.com/s/7R3Y2-nD5fELPa9rtnK7Tg
GitHub - philipperemy/Stanford-NER-Python: Stanford Named Entity Recognizer (NER) - Python Wrapper
原文链接:https://blog.csdn.net/keeppractice/article/details/119921126

