
论文地址:Learning Transferable Visual Models From Natural Language Supervision
代码:https://github.com/openai/CLIP
Clip(Contrastive Language-Image Pre-Training)是由OpenAI于2021年推出的一种深度学习模型,它是一种可以同时处理文本和图像的预训练模型。与以往的图像分类模型不同,Clip并没有使用大规模的标注图像数据集来进行训练,而是通过自监督学习的方式从未标注的图像和文本数据中进行预训练,使得模型能够理解图像和文本之间的语义联系。
CLIP(Contrastive Language Image Pretraining)这篇文章出自OPEN-AI大名鼎鼎的Alec-Radford(GPT系列的一作,在GAN,Diffusion等各种生成领域都颇有影响力)。而CLIP这篇论文可以看做是多模态在预训练时代的一次妙到巅峰的任务设计。
NLP领域里借助海量文本进行无(自)监督式的预训练使得各种与下游任务类型无关的模型架构成为可能,并取得了非常好的迁移性和效果。CLIP使用了一种对比学习的方式,在4亿图文对上进行了文本和图片的匹配任务训练,使得该模型在无任何微调的情况下(zero-shot),在imageNet上取得了和ResNet-50微调后一样的效果。 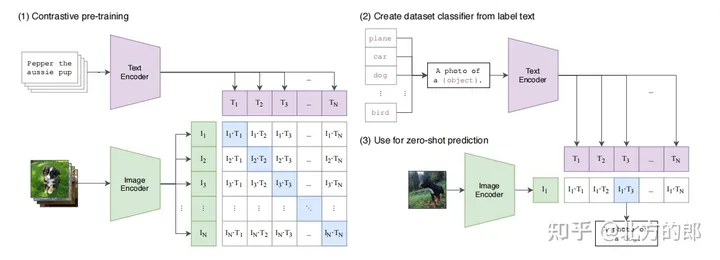
Clip模型的核心思想是通过学习图像和文本之间的匹配关系来提高模型的性能。具体来说,Clip模型包含两个主要组成部分:一个用于处理图像的卷积神经网络(CNN)和一个用于处理文本的Transformer模型。这两个组件都被训练成能够将输入的信息映射到相同的嵌入空间中,并使得相似的图像和文本在嵌入空间中的距离更近。
Clip模型的预训练分为两个阶段:第一阶段是通过一个大规模的文本数据集来训练Transformer模型,使得模型能够理解文本之间的关系;第二阶段则是使用一个大规模的图像和文本数据集来训练整个Clip模型,使得模型能够将文本和图像之间的联系进行匹配。实现的伪代码如下: 
Clip模型的一个重要应用是图像分类,它可以将输入的图像和文本信息进行匹配,从而识别图像的内容。此外,Clip模型还可以用于图像生成、图像检索、视觉问答等任务。
CLIP模型因其创新的预训练方法和跨模态理解能力,在多领域展现了强大的应用潜力。尽管CLIP是由OpenAI研发,但阿里云也提供了丰富的服务和产品,可以帮助用户利用类似的技术思路或是在CLIP基础上进一步开发自己的应用。以下是一些与之相关的阿里云产品和服务:
模型训练与推理服务:
机器学习平台:
图像处理与分析服务:
自然语言处理服务:
开发者工具与服务:
综上所述,虽然阿里云没有直接提供CLIP模型作为服务,但通过其强大的基础设施、机器学习平台及丰富的开发者工具,用户完全有能力基于CLIP或类似技术构建和部署自己的多模态应用解决方案。

