
Chinese CLIP已经被Transformers官方merge了,可查看官方repo:)
另外,Chinese CLIP工作中的ELEVATER benchmark分类数据集的中文版本也在官方网站被cross link
https://computer-vision-in-the-wild.github.io/ELEVATER/
7月的时候开源了Chinese CLIP,当时得到很多朋友们的肯定和支持。
中间经历一点小波折暂时关闭了,但我们团队也没歇着,这两三个月里蓄力了一波,做了一波大更,前两天在Github重新开源,并在达摩院最新发布的平台ModelScope魔搭社区 (modelscope.cn)上同步发布。一次放出5个规模的Chinese CLIP,最小到ResNet50大小,最大到ViT-H。效果比原来好很多,中文多模态检索基本都是SOTA了,zero-shot image classification可以和英文巨头们一拼(唯一参加ECCV CVinW workshop的外语选手)。我们还做了检索的Demo,可以直接输query体验效果:
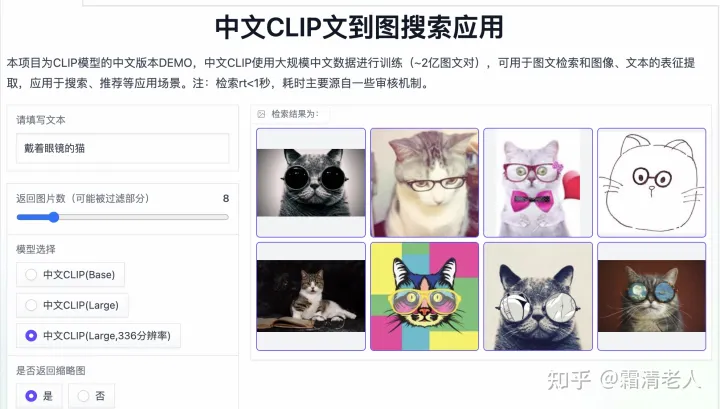
技术报告也已经在arXiv放出,详细地介绍了实现细节,包括数据和模型训练,以及下游验证实验和分析等等。本文会做简单的介绍。
Arxiv链接:[2211.01335] Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese (arxiv.org)
ModelScope链接:ModelScope 魔搭社区
Demo链接:ModelScope 魔搭社区
之前的文章已经介绍过做中文CLIP的一些想法,更详细的可以看上一篇文章的一些showcase,可以看到多语言的mclip在中文图搜表现是很难让人满意的,比如搜索“对联”返回的却是圣诞相关的物品。在我们后来的实验里,在中文原生的数据集上,我们对比了OpenAI CLIP和我们中文CLIP的表现,会发现后者的优势是巨大的。当然,之前也有一些相关工作,但大多增加了算法的复杂性,并且还存在开源做得不足的问题等等。因此,我们就是想打造一个靠谱的Baseline,CLIP如果换成大规模的中文数据应当取得比较突出的效果。因此,我们收集了接近2亿的图文对数据(绝大部分都是公开的数据),在上面用CLIP的方法做预训练(当然有一些训练方法上的改动,后续会介绍我们使用的两阶段预训练的方法,如下图所示),训练出了5个规模的中文CLIP模型,包括ResNet、ViT-B/16、ViT-L/14、ViT-L/14@336px和ViT-H/14。实验做了3个公开数据集的图文检索,还做了一系列经典图像分类数据集的零样本分类,都取得不错的效果,其中检索基本达到SOTA,零样本分类也比较有竞争力。我们补充做了一些分析,证明了两阶段预训练的有效性,同时还发现了CLIP本身一些比较明显的缺陷,比如对prompt很敏感以及难以理解否定。之后,我们还会做一些更强的模型,同时还会特别关注轻量化这块,让小模型的效果能提上去。
我们希望我们的工作即使预训练也是可以复现的,因此为了减少壁垒,我们尽可能使用公开数据集。其中包括LAION-5B中标注了“zh”的部分,华为悟空数据集,但因为失效链接等问题,1.1亿的LAION和7千万的悟空的图才被下下来。我们还增加了一些英文的翻译数据集,比如VG和COCO。此外因为一些历史原因,我们的预训练数据集还是混入了少量私有数据集,不过我们认为应该不会对最终效果造成太大影响。
先简单回顾CLIP,它的核心就是图文双塔模型,用对比学习让正例更近,让负例更远,CLIP原文的图非常易懂:
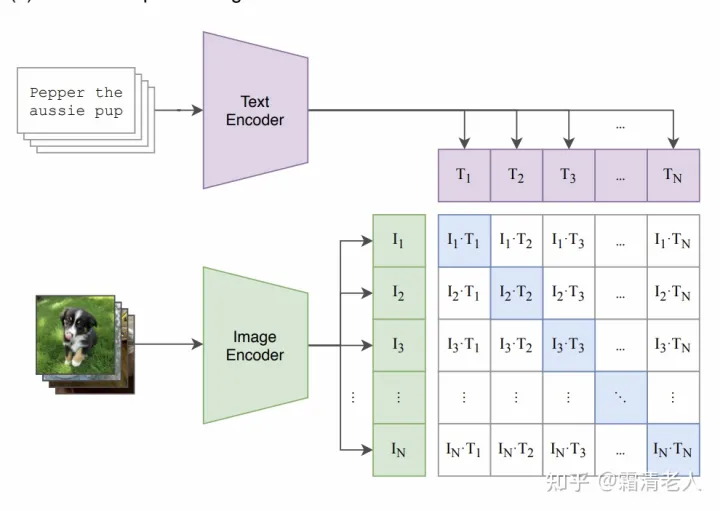
可以看到负采样就是在batch内采样,和SimCLR一个道理,我们的实现上就是使用all gather让分布式增大batch size的同时也能增大负例size。
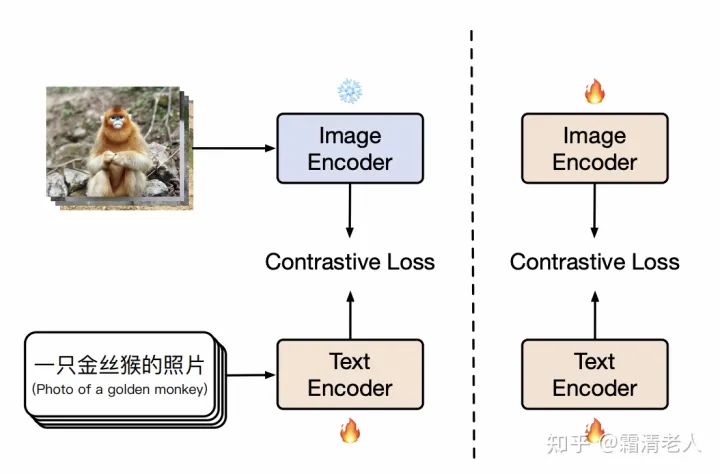
下面说下我们核心的训练方法。最朴素的方案就是用我们的数据从头开始训练,但是成本太高了,当时就设计了两阶段的方法,后续我们也通过ablation证明它是相对来说最好的方案了。两阶段训练法的核心思路就是把OpenAI那个极强的CLIP给用上,现在有的工作做得比较狠,直接把文本塔对齐CLIP的图像塔。固然在Flickr30K-CN和COCO-CN这类翻译数据集上应该能取得比较不错的效果,但是没有学过中文世界的图像的模型真的能很好地应用到中文场景吗?当然也可以直接finetune,我们也把它作为一个对比选项。
我们的核心方法在于把训练分为两阶段(如上图所示),第一阶段和LiT是一致的,冻结图像塔,让文本塔表示接近图像塔表示。当训练继续但下游精度不能再产生显著提升,即下游零样本检索的精度,我们就把训练切换到第二阶段,即解除图像塔的参数冻结,继续用contrastive tuning预训练,同样直到下游精度没有显著提升。后者的意义在于让图像塔能拟合中文世界的图像数据的分布,学习中文世界的知识。更多实验参数欢迎查看论文的附录部分。
最终我们训练了5个规模的模型,小到ResNet50,大到ViT-H,如下表所示:

目前我们做的实验集中在图文检索的零样本和finetuningh场景,以及最具代表性的CLIP的零样本图像分类。检索方案,我们在MUGE、Flickr30K-CN、COCO-CN上基本都做到零样本和finetuning最优:
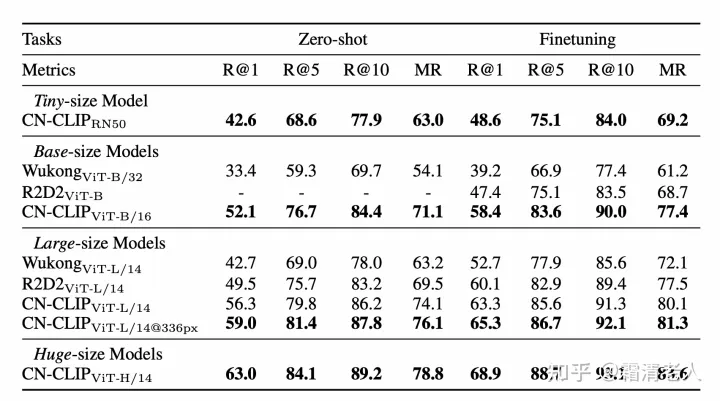
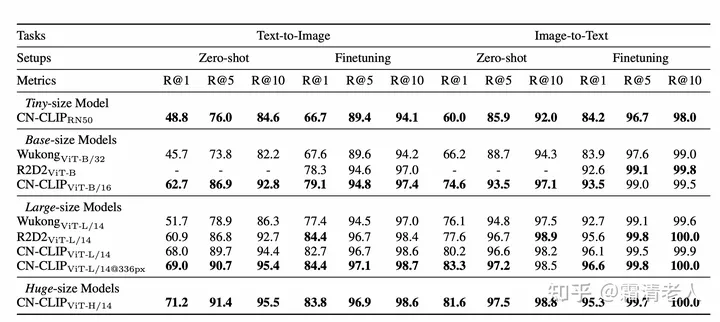
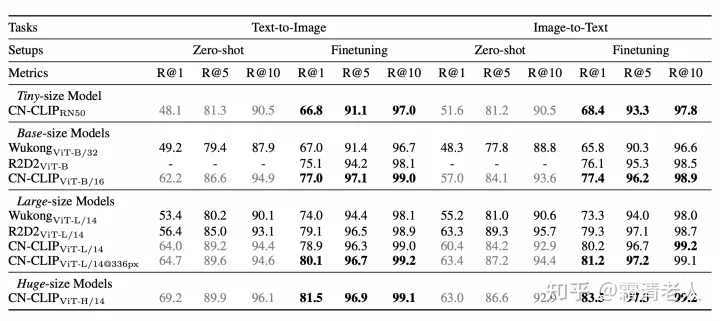
由于预训练数据的原因,COCO的零样本分类我们选择标灰
在零样本图像分类方面,MSR近期做了个不错的叫做ELEVATER的工作,并且在ECCV 2022上举办了Computer Vision in the Wild的Workshop,中文CLIP参加了其中的图像分类的Zeroshot industry track(EvalAI: Evaluating state of the art in AI),最终排名第五,主要败给英文世界的巨头们,其中包括2个超大模型:
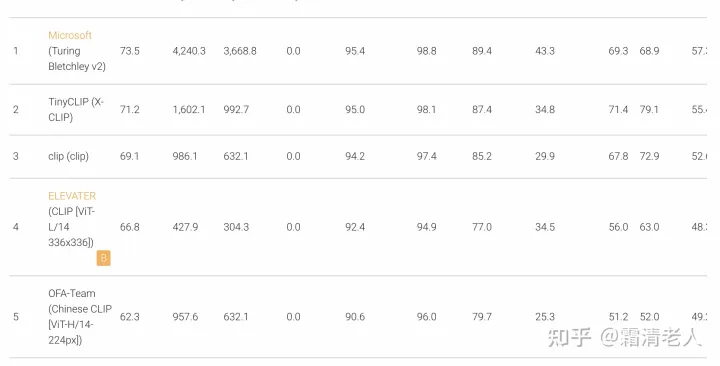
作为中文选手参赛,我做了些手活把20个数据集的标签全部翻译了,然后用和OpenAI一样的prompt ensembling去做零样本分类。和检索类似,我们也发现随着规模增大,总体效果能不断提升,但也并非绝对。有些数据集可以看到跟模型大小似乎没啥关系,比如检测肿瘤这种,甚至包括Rendered SST2其实我都觉得不甚合理。此外还有不少数据集对中文模型是比较不友好的,比如GTSRB这个德国交通标志分类、Country211这个根据图片分类国家/地区(抗议其中label的政治不正确!)、以及Food、Pet,都不是很友好。最难搞的应该是Aircraft和Car了,飞机那个好多我基本都不认识也只能靠谷歌查有的甚至搜不到只能强行音译,汽车也是同理。这些翻译的影响都实在太大了,以及原始的label是不是还能有很大的优化空间也不好说。
此外我们做了点比较有趣的分析,比如验证了两阶段方法的有效行,主要和从头训练,只做contrastive tuning来对比,可以从下图看出,除了MUGE,两阶段都是最优的。但即便MUGE,两阶段也和直接tune差距很小,但是在翻译数据集上优势就非常明显。有趣的是,一阶段切换二阶段在多个数据集上都出现了明显的效果的蹿升。
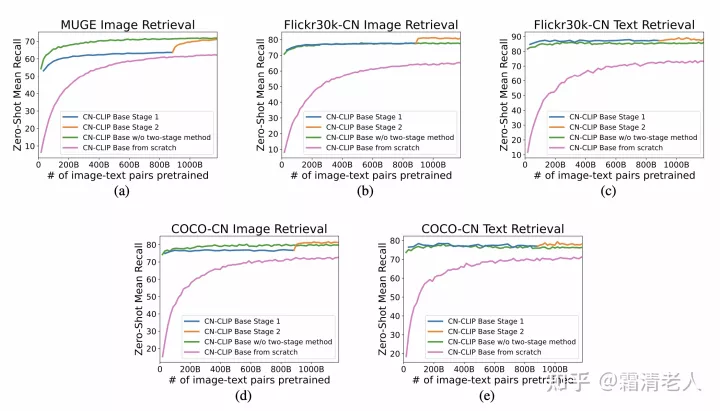
另外观察到两个点,一是此前比较多工作提到的对prompt的敏感,我们总体而言观察到接近90个prompt的OpenAI prompt集合的翻译版本表现总体要优于ELEVATER为每个数据集提供的定制版prompt,但也有几个例外,比如飞机就是个典型。我在定制版的翻译的基础上还添加了很多类似的prompt做ensemble,效果还能有大幅提升。
更有趣的是关于CLIP理解否定的问题。这事其实BERT已经被讨论过,但CLIP据我了解应该之前没有。我们发现CLIP这方面的问题更明显。其实这事还是我们的用户做实验给我们反馈他们在业务上使用出现的问题,我们才意识到这事。刚好KITTI这个数据集给了个很不错的场景做验证。KITTI的label有4个,分别是“在汽车的左边或右边”、“在汽车的附近”、“离汽车一段距离”、“没有汽车”,我做的替换就是把“没有汽车”替换成“其它”,准确率就能提升20多个点。其实不难理解,CLIP的训练数据都是文本描述图像,没有说这个图像没有什么这种话,之后的研究可以适当加入这样的标注数据进来,利用物体检测和规则应该就能构造。
很简单的一项工作,我们这篇技术报告之后还会更新加入更多细节,还有一些关于轻量化的内容补充,以及短期内我们还会探索更多的玩法,当然也包括探索它更多的不足,让大家对CLIP多一分了解。

